Research
RAG Anything : The New Era of the RAG-Modal
Generative artificial intelligence has reached a decisive milestone in recent years, radically transforming how we interact with information. Yet, a persistent frustration remains among developers and businesses: the partial blindness of language models to the visual richness of our documents. Until now, most Retrieval-Augmented Generation (RAG) systems have excelled at processing plain text but stumbled when faced with interpreting complex charts, mathematical equations, or sophisticated layouts.
It is precisely to bridge this gap that the RAG Anything framework was created. This innovation promises to redefine information extraction standards by treating every element of a document—whether textual or visual—as an interconnected knowledge entity.
Multimodal Unification
The main limitation of traditional RAG architectures lies in their siloed approach. In a conventional system, text is often separated from images or tables, either ignored entirely or processed through parallel pipelines with no genuine semantic connection to the surrounding content. RAG Anything shatters this barrier by introducing a unified framework that no longer discriminates between data types. To this system, an image, its caption, a financial table, and a paragraph of prose are all first-class citizens within the same knowledge ecosystem.
This design philosophy is transformative for analyzing long, heterogeneous documents. Imagine a 100-page financial report filled with stock charts and balance sheet tables. Where a traditional AI might hallucinate or lose coherence by relying solely on adjacent text, RAG Anything can “see” and understand the document as a cohesive whole. It contextualizes each modality, enabling the AI to reason over evidence that spans multiple formats simultaneously. By seamlessly fusing vision and language, it captures subtle insights completely missed by earlier systems, delivering unprecedented accuracy for mission-critical professional tasks.
The Dual-Graph Architecture
The true technical breakthrough of RAG Anything lies in its innovative hybrid engine, often described as a “Dual-Graph” architecture. Unlike simplistic methods that merely convert content into mathematical vectors (embeddings) for similarity-based retrieval, this framework goes much further by constructing a genuine mental map of the document. It structurally understands how a figure is linked to its explanation three pages later.
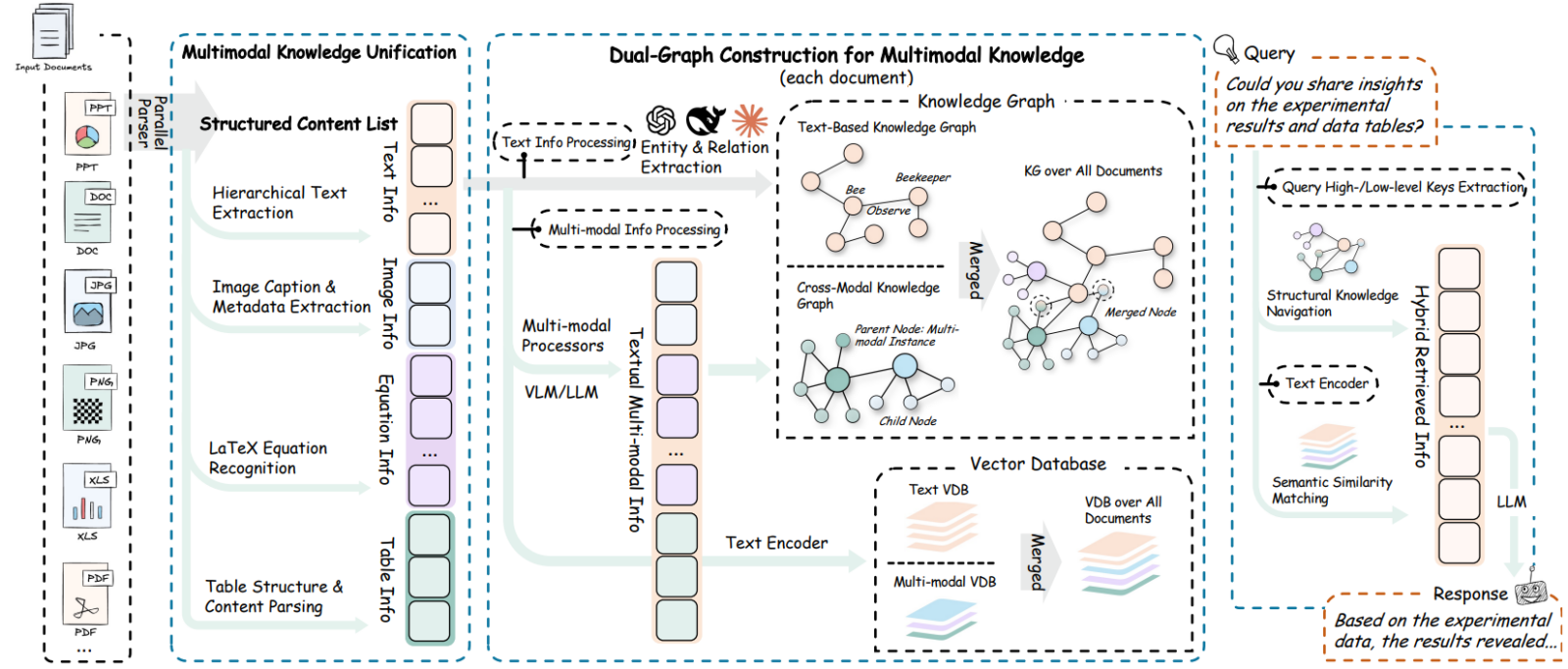
This architecture intelligently combines structural navigation with semantic matching. On one hand, the system uses knowledge graphs to preserve explicit relationships between elements—such as the parent-child link between a section heading and its content, or the referential connection between a footnote and a table. On the other hand, it continues to leverage the power of dense vector embeddings to identify subtle thematic connections that are not explicitly encoded in the document’s structure.
By integrating these two approaches, RAG Anything enables multi-hop information retrieval. The AI can thus follow a complex line of reasoning through a document, jumping from a chart to its explanatory text, then to a concluding remark, effectively replicating the cognitive pathway of a human expert analyzing a technical dossier.

Toward More Autonomous and Capable AI Agents
The impact of this technology goes far beyond merely enhancing internal search engines. By delivering a highly granular and structured understanding of data, RAG Anything paves the way for a new generation of autonomous AI agents that are significantly more reliable. The ability to process heterogeneous information without losing contextual integrity is critical for advanced applications, such as automated auditing, scientific research assistance, or legal advisory systems.
Moreover, recent benchmarks demonstrate that this approach substantially outperforms current state-of-the-art methods, especially on long documents where cognitive load is high. By eliminating the architectural fragmentation that has constrained existing systems, this framework offers a more robust and scalable solution for enterprises. Integrating such capabilities into web and software development pipelines heralds the democratization of multimodal intelligence, transforming virtual assistants from merely talkative interfaces into genuinely insightful and perceptive collaborators.
[1] Guo, Z., Ren, X., Xu, L., Zhang, J., & Huang, C. (2025). RAG-Anything: All-in-One RAG framework. arXiv. https://doi.org/10.48550/arXiv.2510.12323