Research
Qwen3 ASR: Open Source Multilingual Speech Recognition
Qwen3 ASR, a new family of automatic speech recognition models
The Qwen team from Alibaba Cloud made a major splash at the end of January 2026 by unveiling Qwen3 ASR, a new family of automatic speech recognition models that is disrupting the audio AI landscape. Available as open source under the Apache 2.0 license, this solution promises to rival the most powerful commercial APIs while supporting 52 languages and dialects. An announcement that consolidates Qwen’s position as the most downloaded open source AI model family in the world, with over 700 million cumulative downloads on Hugging Face.
Available Qwen3 ASR Model Types
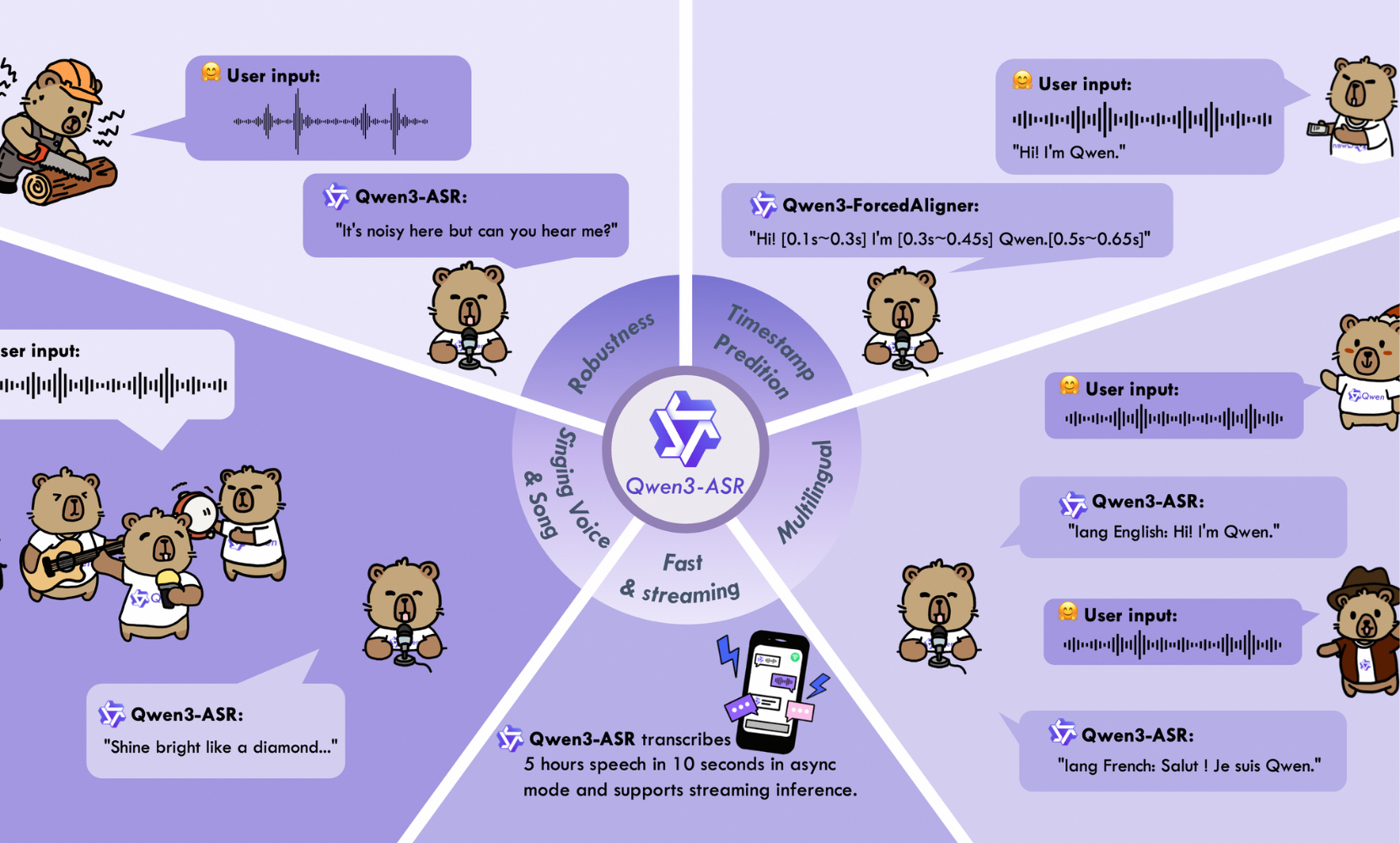
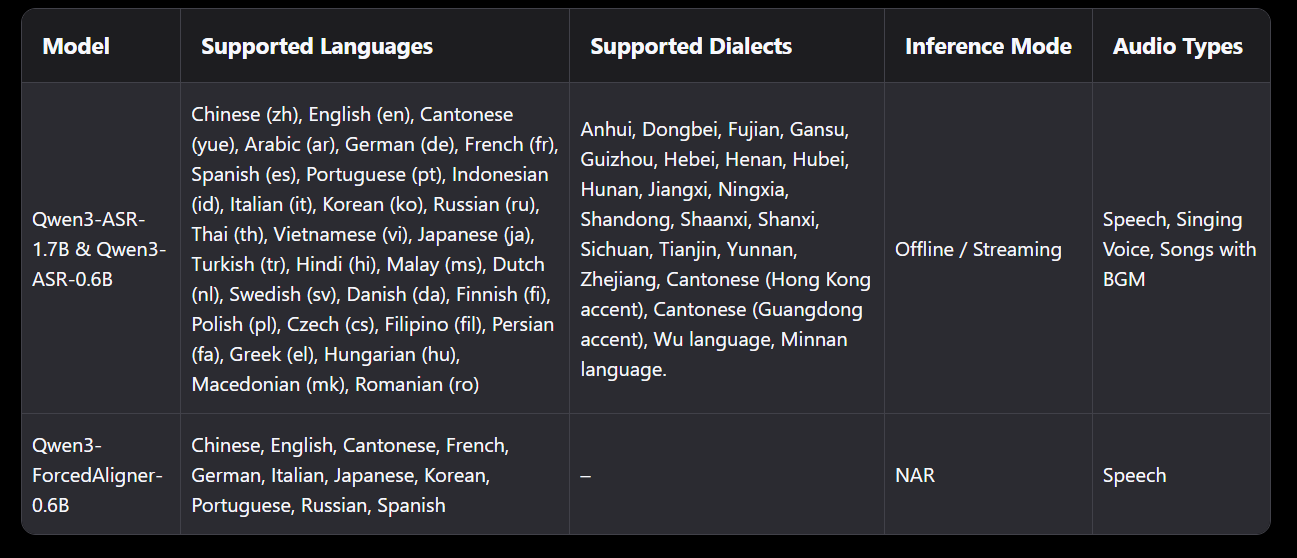
Qwen3 ASR comes in three distinct variants, each addressing specific use cases. The flagship model, Qwen3 ASR 1.7B, features 1.7 billion parameters and aims for maximum performance. For applications requiring a balance between accuracy and efficiency, Qwen3 ASR 0.6B offers a lighter alternative with 600 million parameters. This compact version displays remarkable performance with an average latency of only 92 milliseconds and an impressive capacity to transcribe 2000 seconds of audio in a single second with concurrency of 128 simultaneous requests.
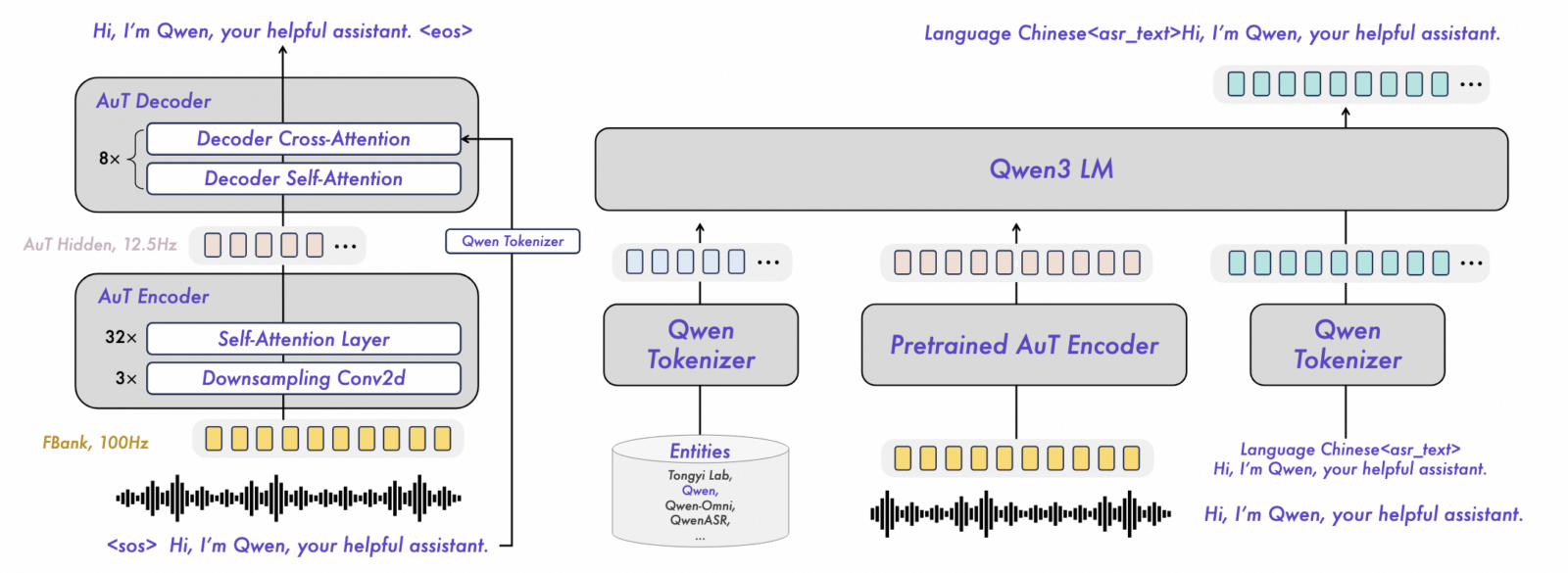
This design incorporates a dynamic attention window adjustable between 1 and 8 seconds, allowing Qwen3 ASR to function both in streaming mode with short segments and in offline mode for long queries. The flagship Qwen3 ASR 1.7B model combines the Qwen3-1.7B language model with a 300 million parameter AuT encoder and a hidden dimension of 1024, connected by a projection module. [1]
The Qwen3 family also stands out with the addition of Qwen3 ForcedAligner 0.6B, an innovative model dedicated to forced alignment. This non-autoregressive solution enables precise prediction of word or character-level timestamps for 11 languages, paving the way for particularly sophisticated subtitling and audio-text synchronization applications.
Qwen3 ASR Performance Challenges OpenAI’s Whisper
Tests reveal that Qwen3 ASR 1.7B achieves state-of-the-art performance among open source models and proves competitive against the most powerful commercial APIs. The model notably surpasses OpenAI’s Whisper large v3, widely considered a benchmark in the field, on several reference benchmarks. This feat is explained by Qwen3’s sophisticated architecture, which relies on the Qwen3 Omni foundation model and benefits from an AuT audio encoder trained on massive volumes of speech data.
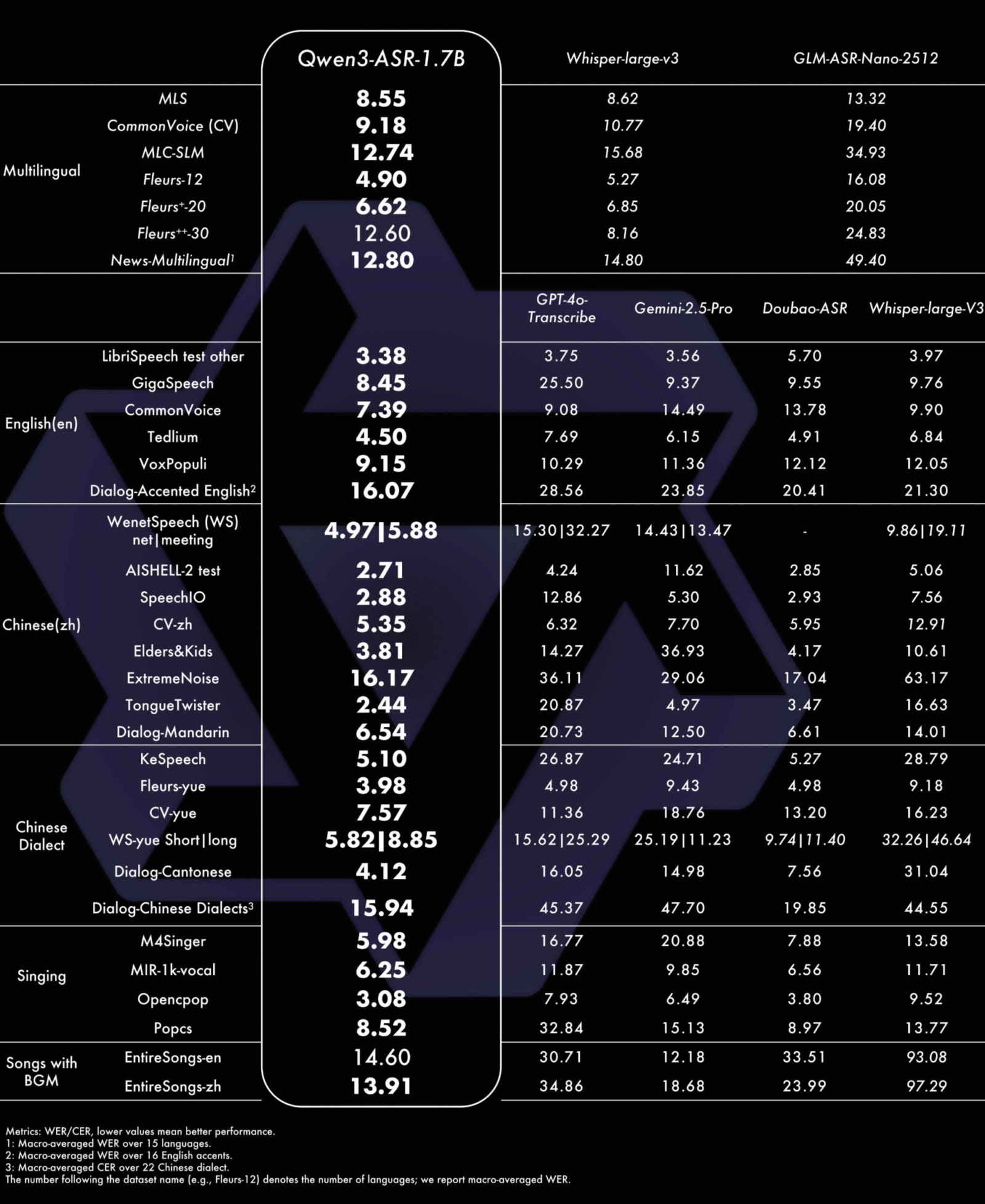
One of the major strengths of Qwen3 ASR lies in its exceptional robustness when facing complex acoustic environments. The model maintains high recognition quality even in the presence of significant ambient noise, background music, or regional dialects. This ability to handle difficult real-world situations distinguishes it from competing solutions that often excel only on clean laboratory audio recordings.
Impressive Language Coverage
With support for 30 languages and 22 Chinese dialects, Qwen3 ASR displays a decidedly global ambition. The model also handles English accents from multiple geographic regions, ensuring reliable recognition regardless of the speaker’s origin. This linguistic versatility is accompanied by an automatic language identification feature, allowing the system to detect and transcribe audio without requiring prior configuration.
The all-in-one approach adopted by Qwen considerably simplifies deployment for developers. No need to juggle multiple specialized models or build complex pipelines: a single Qwen3 ASR model is sufficient to handle language identification, multilingual transcription, and even non-speech segment detection.
An Open Source Model That Opens New Perspectives
The release of Qwen ASR is part of Alibaba Cloud’s offensive in the open source artificial intelligence arena. With nearly 400 Qwen models made accessible and more than 180,000 derivative versions created by the community, the company rivals Meta and its Llama models directly.
Opening under the Apache 2.0 license allows unrestricted commercial use, facilitating adoption by companies wishing to integrate advanced speech recognition capabilities without depending on expensive proprietary services. Applications cover a broad spectrum: automatic subtitling, voice assistants, meeting transcription, call centers, and accessibility for the hearing impaired.
[1]Shi, X., Wang, X., Guo, Z., Wang, Y., Zhang, P., Zhang, X., Guo, Z., Hao, H., Xi, Y., Yang, B., Xu, J., Zhou, J., & Lin, J. (2026). Qwen3-ASR Technical Report. arXiv preprint arXiv:2601.21337v2. https://doi.org/10.48550/arXiv.2601.21337
[2] Qwen3-ASR & Qwen3-ForcedAligner is Now Open Sourced: Robust, Streaming and Multilingual!