Research
Meta SAM 3D: 3D Reconstruction of Images from the Physical World
Generative artificial intelligence is undergoing explosive acceleration. While recent years have dazzled us with models capable of generating ultra-realistic text and 2D images, a new frontier is now being crossed: that of depth and volume. Meta, already a pioneer with its Segment Anything Model (SAM), is once again stepping into the spotlight with a major evolution poised to transform our relationship with digital content.
This new iteration, which we’ll examine here through the lens of SAM 3D, goes beyond merely segmenting objects in flat images. Instead, it aims to understand, interpret, and reconstruct the physical world in three dimensions. For developers, augmented reality content creators, and tech enthusiasts alike, this represents a critical breakthrough. How can we move from a simple photograph to a usable 3D asset? That’s precisely the promise of this technology.
In this article, we’ll dive deep into this innovation to understand what this new version truly entails, how it differs from its predecessors, and we’ll closely examine its two core components: SAM 3D Objects for inanimate objects and SAM 3D Body for human reconstruction.
What is Meta’s SAM 3D?
To fully grasp the significance of 3D, it’s essential to revisit the engine powering this technology. When we refer to SAM 3D, the latest logical evolution in the Segment Anything lineage, we’re primarily talking about a visual “brain” capable of unprecedented semantic understanding.
The original SAM model had shocked the industry with its “zero-shot” capability: it could segment any object in an image without ever having been specifically trained on that particular object. SAM 3D takes this concept much further. It’s no longer just about identifying edges based on pixel contrasts; instead, it integrates contextual and temporal understanding (building on prior video-related research).
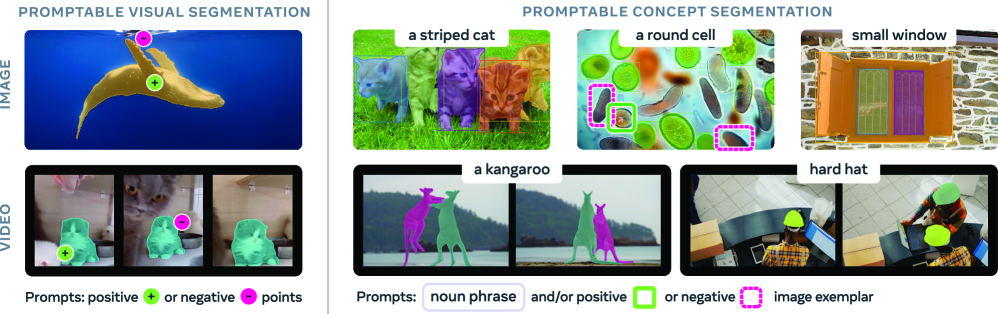
This model acts as a foundation, delivering surgically precise segmentation masks that are essential for any 3D reconstruction task. Without flawless segmentation upfront, any attempt to model an object in 3D fails, as the software cannot distinguish the object from its background. SAM 3 thus serves as this fundamental building block, faster, lighter, and, above all, smarter in handling occlusions and complex lighting, paving the way for the next step: spatialization.
What are the differences between SAM 3 and SAM 3D?
It’s common to confuse the foundational model with its spatial application. To put it simply, we could say that SAM 3 is the “eye,” while SAM 3D is the “sculptor.”
SAM 3 fundamentally operates in a two-dimensional space. It analyzes pixels on an X–Y plane, producing a binary mask: “this is a cat, this is not a cat.” It excels at identifying and separating elements within an image, but it doesn’t inherently “know” what the back of the cat looks like if the cat is viewed from the front.

In contrast, SAM 3D leverages SAM 3’s outputs to infer the Z dimension (depth). It combines SAM’s powerful segmentation capabilities with advanced computer vision techniques and geometric deep learning. Where SAM 3 provides a flat silhouette, SAM 3D delivers a rotatable mesh or point cloud. It is this shift, from image analysis to shape synthesis, that marks the true technological breakthrough. This distinction is crucial: SAM 3D is not merely an update, but an entirely new branch of application dedicated to immersive 3D reconstruction.
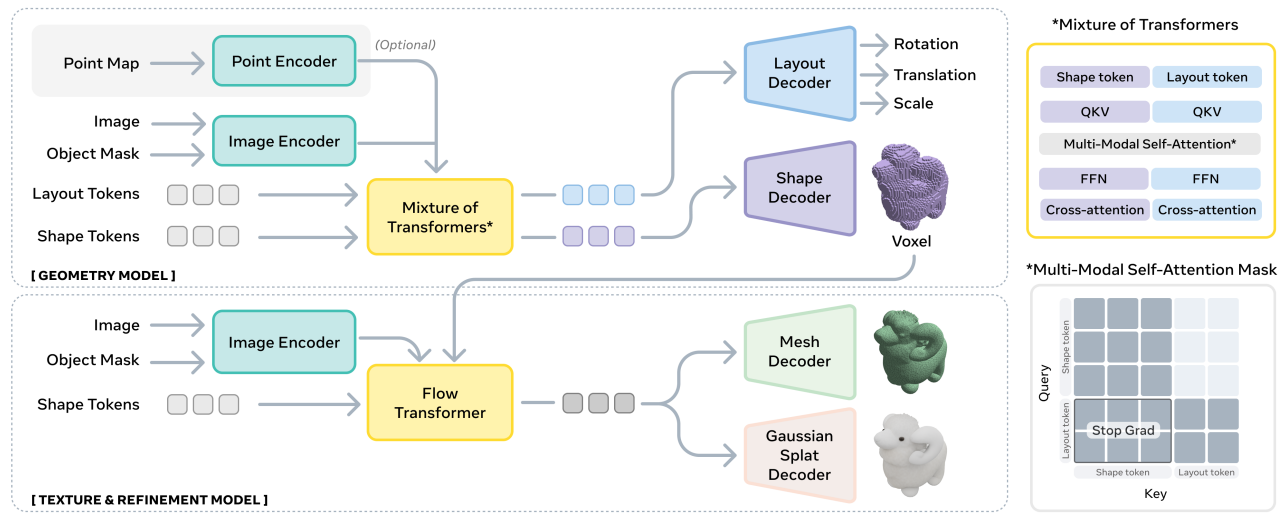
(Right) The mixture-of-transformers-based architecture employs a two-stream approach, with cross-modal information sharing in the multi-modal self-attention layer. (Bottom) The voxels predicted by the geometry model are passed to the texture and refinement model, which adds high-resolution details and textures. Source [2]
SAM 3D Object, from static images to virtual objects in a 3D scene
One of the most anticipated features of this technological suite is the SAM 3D Object module. Imagine being able to snap a photo of a vintage chair in a store and, within seconds, obtain a textured 3D model ready to be imported into a video game or an interior design application. That’s precisely the goal of SAM 3D Object.
The process relies on single-view reconstruction or a handful of sparse viewpoints. The model first identifies the object through segmentation, then “hallucinates” the unseen parts of the object in a coherent manner, leveraging a vast database of 3D shapes it has learned during training. Unlike traditional photogrammetry, which requires dozens of photos captured from every angle, this is AI-assisted predictive reconstruction. Texture is then projected and extrapolated to cover the entire 3D volume. This breakthrough opens enormous opportunities for e-commerce and the metaverse, drastically reducing the cost and effort of producing 3D assets.
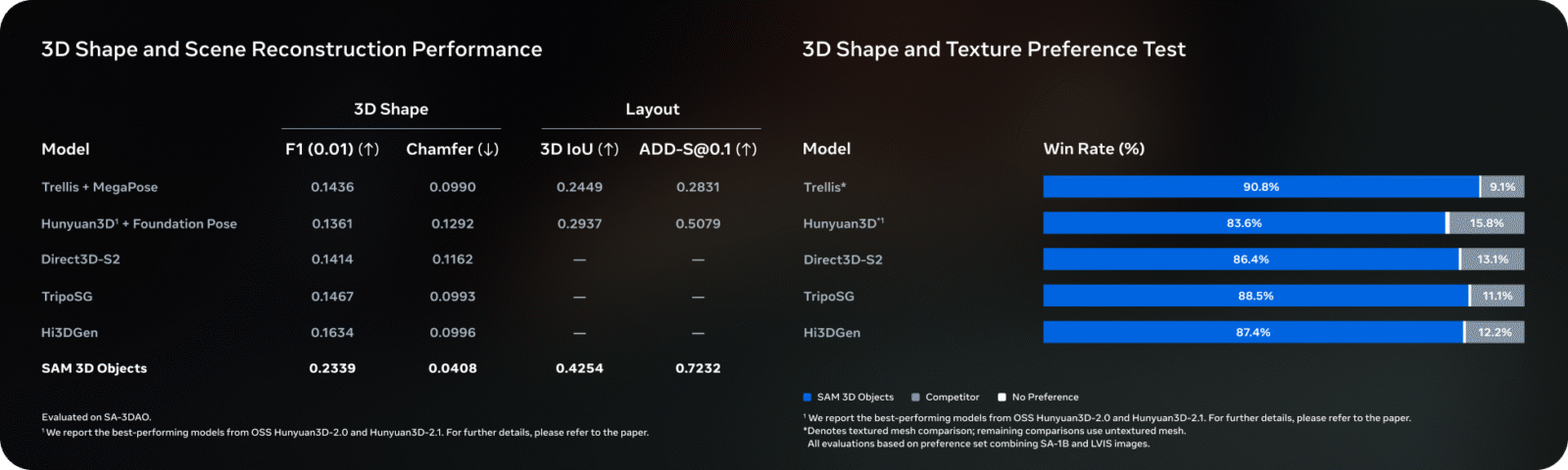
Limitations of SAM 3D Object
However, this technology isn’t magic, yet. SAM 3D Object faces several notable challenges. The first involves complex geometry: if an object contains holes (like a intricate cup handle) or fine structures (such as bicycle wheel spokes), the AI tends to “fill in” these gaps or produce overly smooth shapes, losing fine details.
Moreover, textures on occluded surfaces remain purely predictive. If you photograph an object whose back is radically different from its front, such as a cereal box with ingredient information only on the reverse, the AI will likely generate a back texture resembling the front or a generic placeholder, resulting in inconsistencies with reality. Finally, reflective or transparent surfaces (glass, polished metal) remain a persistent nightmare for 3D reconstruction, often leading to visual artifacts.
SAM 3D Body, Robust and Accurate 3D Human Reconstruction
The other fascinating aspect of this technology is SAM 3D Body. Human reconstruction is a far more challenging task than reconstructing rigid objects, as the human body is articulated, deformable, and often obscured by clothing that conceals its true shape.
Here, Meta delivers a powerful solution capable of capturing not only pose (the skeleton) but also body shape (the volumetric form) with impressive fidelity. Unlike previous approaches that often produced generic “mannequin-like” figures, SAM 3D Body can estimate the subject’s actual morphology from a single image or video. System leverages anatomical priors, pre-existing knowledge of human anatomy, to correct segmentation errors.
The applications are immediate: virtual clothing try-ons, biomechanical sports analysis, and the creation of realistic avatars for virtual reality. The model is so robust that it maintains 3D consistency even when the subject moves quickly or assumes complex poses that would have previously broken earlier 3D reconstruction systems.

Limitations of SAM 3D Body
Despite these advances, perfect human reconstruction remains out of reach. The primary limitation of SAM 3D Body lies in handling loose-fitting clothing. The AI still struggles to disentangle the volume of fabric from the actual body underneath. For instance, a person wearing a winter coat may be reconstructed as significantly bulkier than they really are, with the model misinterpreting the clothing as body mass.
Another challenge involves hand–face or hand–object interactions. While the overall body reconstruction is solid, fine details, such as interlaced fingers or a hand holding a smartphone, often suffer from mesh fusion artifacts, resulting in indistinct “blobs” at the extremities.
Lastly, dramatic lighting or strong cast shadows can still mislead the algorithm about the true depth of certain limbs, slightly distorting the perspective of the generated 3D model.
Key Takeaways from Meta’s Work
With the introduction of these new 3D reconstruction capabilities, Meta is no longer merely segmenting the world, it aims to digitally clone it. The leap from 2D to 3D enabled by SAM 3D represents a qualitative breakthrough, effectively turning any smartphone camera into a potential 3D scanner.
Although challenges remain, particularly regarding the handling of occluded textures in SAM 3D Objects and loose clothing in SAM 3D Body, the work carried out by Meta’s team marks a major advance in the fields of computer vision and 3D modeling.
[1] Carion, N., Gustafson, L., Hu, Y.-T., Debnath, S., Hu, A., Suris, D., Ryali, C., Alwala, K. V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., … Feichtenhofer, C. (2025). SAM 3: Segment Anything with Concepts. arXiv.
[2] SAM 3D Team, Chen, X., Chu, F.-J., Gleize, P., Liang, K. J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., & Malik, J. (2025). SAM 3D: 3Dfy Anything in Pictures. arXiv.
[3] Introducing SAM 3D: Powerful 3D Reconstruction for Physical World Images
Test SAM 3 for segmentation – SAM 3D Object – SAM 3D body