Artificial Intelligence
ManiFlow and DiT-X: The robotic manipulation general
Imagine a robot capable of learning to manipulate any object, in any environment, simply by watching videos or listening to human instructions. This long-standing dream of robotics, once confined to the most advanced laboratories, is now coming closer thanks to a new approach called ManiFlow. This visuomotor imitation learning system promises to revolutionize the way robots interact with the physical world, combining speed, precision, and an unprecedented ability to generalize its skills.
What is ManiFlow, and why it is a major step forward ?
ManiFlow is not a robot, but rather a control policy, an intelligent algorithm that decides which movements to perform. Its goal? To generate complex and precise robotic actions based on visual inputs (images or videos), natural language commands (“pick up the blue cup”), and proprioceptive data (the robot’s joint positions). Until now, existing systems often struggled with slow computation or the difficulty of adapting to novel situations.
The innovation of ManiFlow lies in its learning method. Rather than using the diffusion models of classic, often resource-intensive, requiring many steps of computation, the researchers opted for a technique called flow matching with consistency training. Put simply, this allows the model to generate exceptionally high-quality movements in just 1 or 2 inference steps. It’s a significant speed-up, crucial for real-time applications where every millisecond matters.
The architecture Says X : the brain multimodal ManiFlow
To efficiently handle diverse inputs, an image, a sentence, or the position of the arm, ManiFlow relies on a custom neural architecture called DiT-X. It is a derivative of Diffusion Transformers, highly powerful models in the field of image and video generation. DiT-X incorporates two key mechanisms: adaptive cross-attention and AdaLN-Zero conditioning.
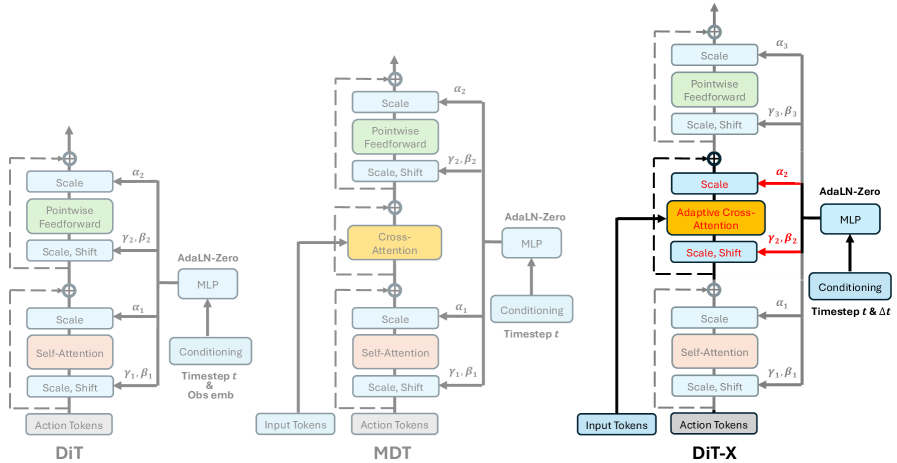
These technical terms hide a simple yet powerful idea: enabling each action token (representing a robot’s movement) to finely interact with every element of the multimodal observations. For example, when the robot “sees” a cup and hears “pick it up,” DiT-X establishes a precise connection between the cup’s position in the image, the word “pick,” and the corresponding movements of the hand and arm. This fine-grained interaction is what allows ManiFlow to handle delicate tasks with remarkable dexterity, whether with one arm, two arms, or even a full humanoid robot.
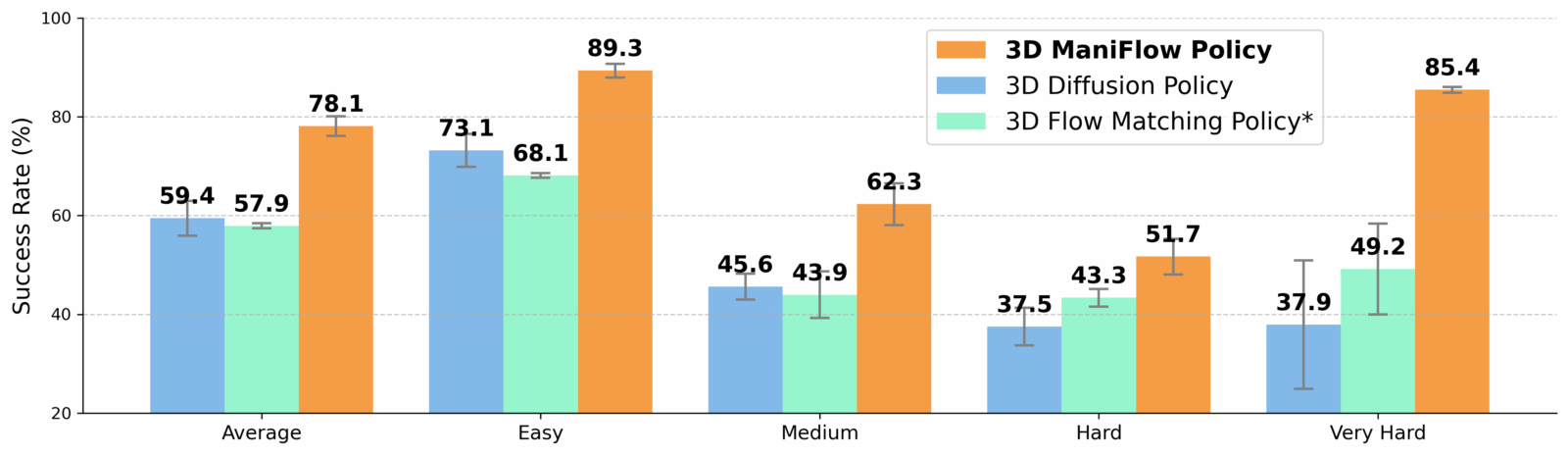
The results speak for themselves. In simulation tests, ManiFlow consistently outperforms previous methods. But the most impressive part happens in the real world, success rates for manipulation tasks were nearly doubled compared to the best existing approaches. The system also demonstrates remarkable robustness when faced with previously unseen objects or changes in the environment, a clear sign of genuine generalization ability.
ManiFlow, to robots more autonomous
The publication of ManiFlow comes at a pivotal moment. Both industry and robotics research are urgently seeking solutions capable of adapting to unstructured environments, such as cluttered warehouses, homes, or hospitals, without needing to be reprogrammed for every new object or task. ManiFlow directly addresses this need.

Its approach, combining imitation, multimodality, and fast action generation, fits into the broader AI trend toward “generalist” models. Much like large language models (LLMs), which can answer an infinite range of questions, ManiFlow aims to become an “LLM for physical manipulation.” Its ability to scale with larger datasets suggests that it could become even more powerful as more robotic interaction data is collected.
[1] Yan, G., Zhu, J., Deng, Y., Yang, S., Qiu, R., Cheng, X., Memmel, M., Krishna, R., Goyal, A., Wang, X., & Fox, D. (2025). ManiFlow: A general robot handling policy through consistency flow training. arXiv.