Research
DeepSeek-OCR : Compression context with the 2D vision
Large language models (LLMs) are now capable of reasoning, writing, coding, and conversing with impressive fluency. However, even the most powerful among them face a fundamental constraint: context length. The longer a text is, whether it is a conversation, source code, or a document, the more tokens are required to represent it. This increases memory usage, slows down processing, and multiplies costs.
Faced with this obstacle, DeepSeek offers a radically new solution with DeepSeek-OCR. Rather than trying to indefinitely extend the context window, which is a resource-intensive solution, this approach aims to intelligently compress textual information before it even reaches the model.
Context length of an LLM, what is it?
The context length or context window of a large language model (LLM) refers to the maximum number of tokens it can consider at once when processing an input, whether it’s a question, a text to complete, a conversation history, or a document to analyze. This “context” is the model’s immediate memory; everything within it can influence its response, while anything beyond this limit is simply ignored.
Concretely, each word, punctuation mark, or symbol is broken down into tokens (the basic units of language processing). For example, the sentence “Hello, how are you ?” might be transformed into 6 to 8 tokens depending on the model. If an LLM has a context window of 8,000 tokens, it cannot “see” beyond this threshold, even if it receives an entire novel or a long conversational exchange.
Why is context length a problem?
Even if an LLM can theoretically handle windows of tens or hundreds of thousands of tokens, its real-world effectiveness often decreases with length. The model naturally pays more attention to elements at the beginning or end of the context, while information placed in the middle risks being “drowned out,” a well-documented phenomenon known as lost-in-the-middle [1]. This limits its ability to extract precise facts from a long document or maintain coherence over extended dialogues.
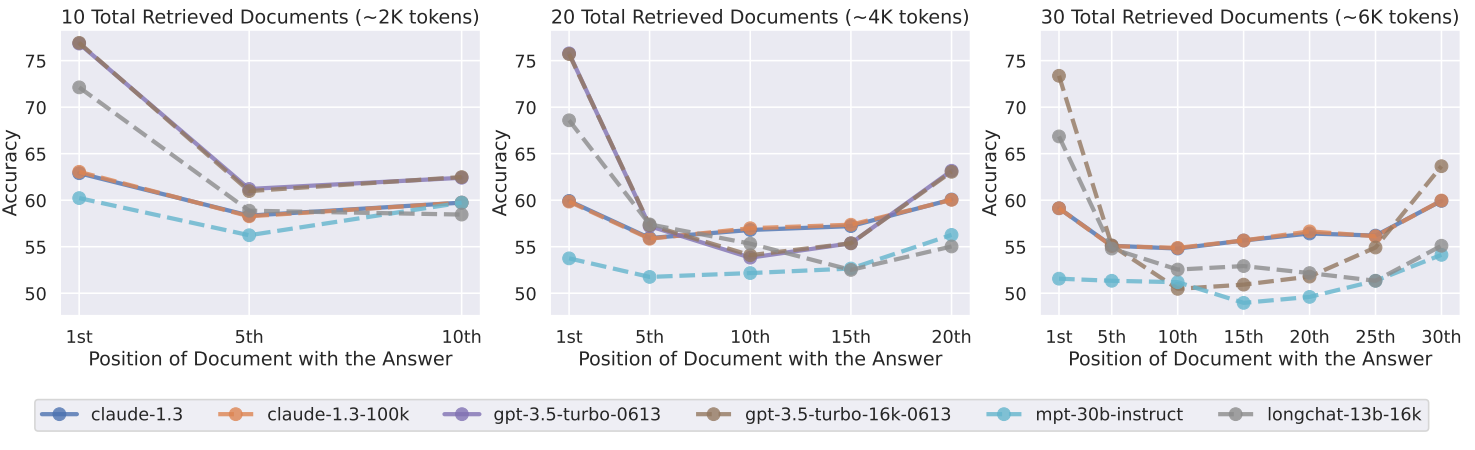
Furthermore, expanding the context window comes at a cost. Each additional token increases the required memory, processing time, and energy bill. Thus, the constraint is not only about the model’s maximum capacity, but also about the balance between performance, accuracy, and operational feasibility. It is in this context that alternative solutions like DeepSeek-OCR are emerging, which do not seek to enlarge the window, but rather to make each token much more informative.
DeepSeek introduces DeepSeek-OCR, a revolutionary VLM.
Faced with the structural limitations of large language models in processing long contexts, DeepSeek proposes a conceptual breakthrough with DeepSeek-OCR, a vision-language model (VLM) designed not to answer questions about images, but to efficiently compress text by treating it as an image. Rather than indefinitely expanding the context window, DeepSeek-OCR encodes textual information into a compact visual form, which a specialized decoder can then read back with remarkable accuracy. This approach transforms vision into a tool for computational efficiency, paving the way for LLMs capable of “memorizing” entire documents without overloading their resources.

DeepSeek chose OCR as the basis for its contextual compression
OCR (Optical Character Recognition) is a technology that converts text within an image, such as a document scan, a photo of a whiteboard, or a screenshot, into usable digital text. Traditionally, OCR was a two-step pipeline: first detecting text regions, then recognizing the characters. Today, thanks to advances in vision-language models (VLMs), this task can be performed end-to-end by a single model, which “reads” an image as a human would. What makes OCR particularly interesting is that it establishes a natural bridge between vision and language; an image of text contains the same information as a sequence of tokens, but in a spatial and compact form.
It is precisely this duality that guided DeepSeek’s choice. Rather than treating text solely as a linear sequence of symbols, the team saw in OCR an ideal testbed for a new idea: using the visual modality not to describe images, but to compress text. By encoding a document as an image, its structure is preserved while drastically reducing the number of tokens required for its representation. OCR thus becomes a mechanism for contextual compression, where the “reading” of the text by a model becomes an operation of visual decoding. This approach paves the way for systems capable of handling very long contexts without overloading resources, a decisive advantage for future LLMs.
Architecture of DeepSeek-OCR
DeepSeek-OCR is based on a simple yet ingenious end-to-end architecture, divided into two main stages: a visual encoder (DeepEncoder), which transforms the document into a compact representation, and a multimodal decoder (DeepSeek3B-MoE-A570M), which converts this representation back into text.
The encoder is designed to process high-resolution images without overloading memory, thanks to a combination of local and global attention, along with a convolutional compression module that drastically reduces the number of visual tokens before their final processing.
The decoder, on the other hand, uses a Mixture of Experts (MoE) architecture to efficiently interpret these visual tokens and generate text with high precision, even after significant compression. This flow allows the system to compress textual information while preserving its essence, paving the way for lighter and faster models.
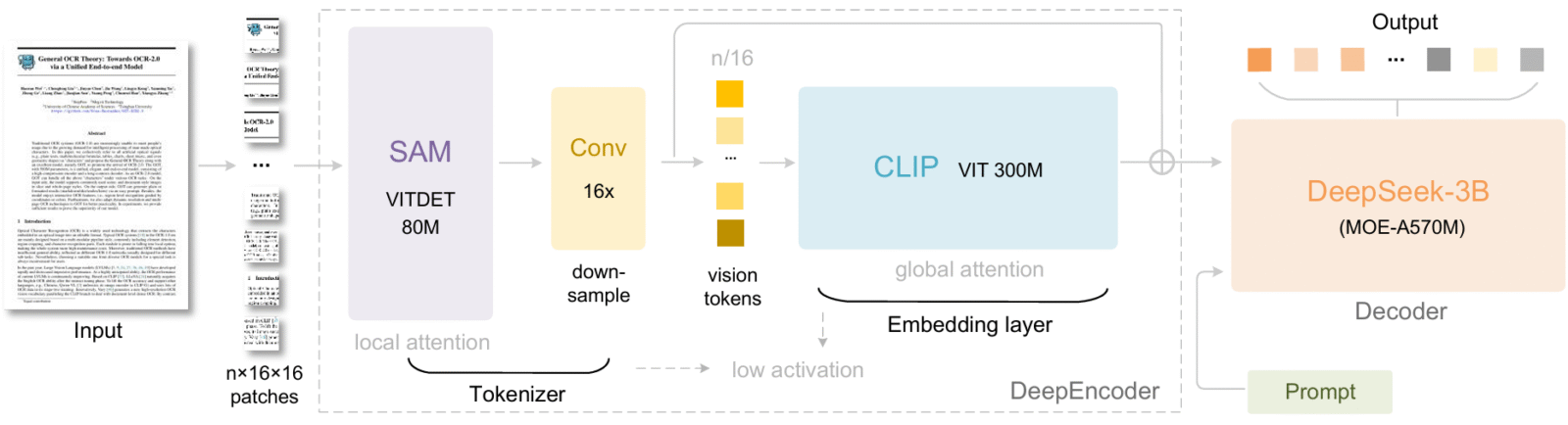
DeepEncoder Encoder, the core of DeepSeek-OCR
The compression engine of DeepSeek-OCR is DeepEncoder. Its goal is simple yet ambitious: to transform a document, whether plain text, PDF, or a scanned image, into an ultra-compact visual representation called vision tokens, while preserving the essential information. To achieve this, it does not treat text as a linear sequence of words but as a structured image, where the arrangement of titles, paragraphs, and tables is as important as the content itself.
The architecture of DeepEncoder is based on three key blocks arranged in series. It begins with SAM (Segment Anything Model)[3], a model specialized in fine-grained image analysis that identifies relevant regions of the document such as text, formulas, and graphics with high precision. These regions are then heavily compressed by a 16× convolutional module, composed of two successive layers that reduce the number of visual tokens by a factor of 16, for example from 4096 to 256 for a 1024×1024-pixel image.
Finally, CLIP (Contrastive Language Image Pre-training)[4], more precisely CLIP-large (with its initial embedding layer removed, since it no longer receives pixels but already structured visual tokens), processes these compressed fragments and transforms them into a rich vector representation. This compact yet expressive vector representation is then used as input by the decoder (DeepSeek3B-MoE). Thanks to it, the model can reconstruct the original text with remarkable accuracy, even after strong compression.
DeepSeek3B-MoE, the multimodal decoder behind DeepSeek-OCR
The decoder of DeepSeek-OCR is DeepSeek3B-MoE-A570M, a 3-billion-parameter language model based on a Mixture of Experts (MoE) architecture. Unlike traditional dense models, this system activates only a portion of its parameters at a time, specifically 570 million during inference, which gives it remarkable computational efficiency while maintaining high expressive capacity.
Specially trained for OCR tasks, it does not receive plain text but rather a compact vector representation from DeepEncoder, a sequence of vision tokens that encode the document in a compressed visual form. Its role is to “reread” this mental image and faithfully reconstruct the original text, including its structure and semantic content.
Thanks to this design, DeepSeek3B-MoE acts as a bridge between vision and language. It does more than recognize characters; it understands spatial context, interprets chemical formulas, decodes charts, and reproduces multilingual text, all from an ultra-condensed input. Once the visual tokens are injected into the decoder, it generates the complete textual output autoregressively, token by token, just like a standard LLM would do from a textual prompt.
Deep Parsing, DeepSeek-OCR understanding beyond text
DeepSeek-OCR goes beyond simple optical character recognition through a feature called Deep Parsing. When given a specific prompt, the model no longer merely transcribes the visible words. It analyzes the semantic structure of what it sees, then converts these elements into usable structured formats such as HTML tables, Markdown, or specialized notations like SMILES for molecules.
Although DeepSeek-OCR is primarily designed for contextual compression and advanced OCR, researchers have also given it some ability to understand general images beyond simple text. As shown in the figure below, for example, it can identify a “teacher” in a class photo, describe the elements of food packaging, or even recognize an image containing text in Chinese.

LLMs capable of “reading” entire documents without saturating their memory?
DeepSeek-OCR is a first step toward building a new generation of language models. By transforming text into a compact visual representation (via DeepEncoder) and then accurately rereading it with an MoE decoder, it proves that it is possible to compress up to 20 times more context while preserving a large portion of the information. At 10x compression, accuracy reaches 97%. Even at 20x, it remains around 60%, which is a remarkable result for such an efficient system.
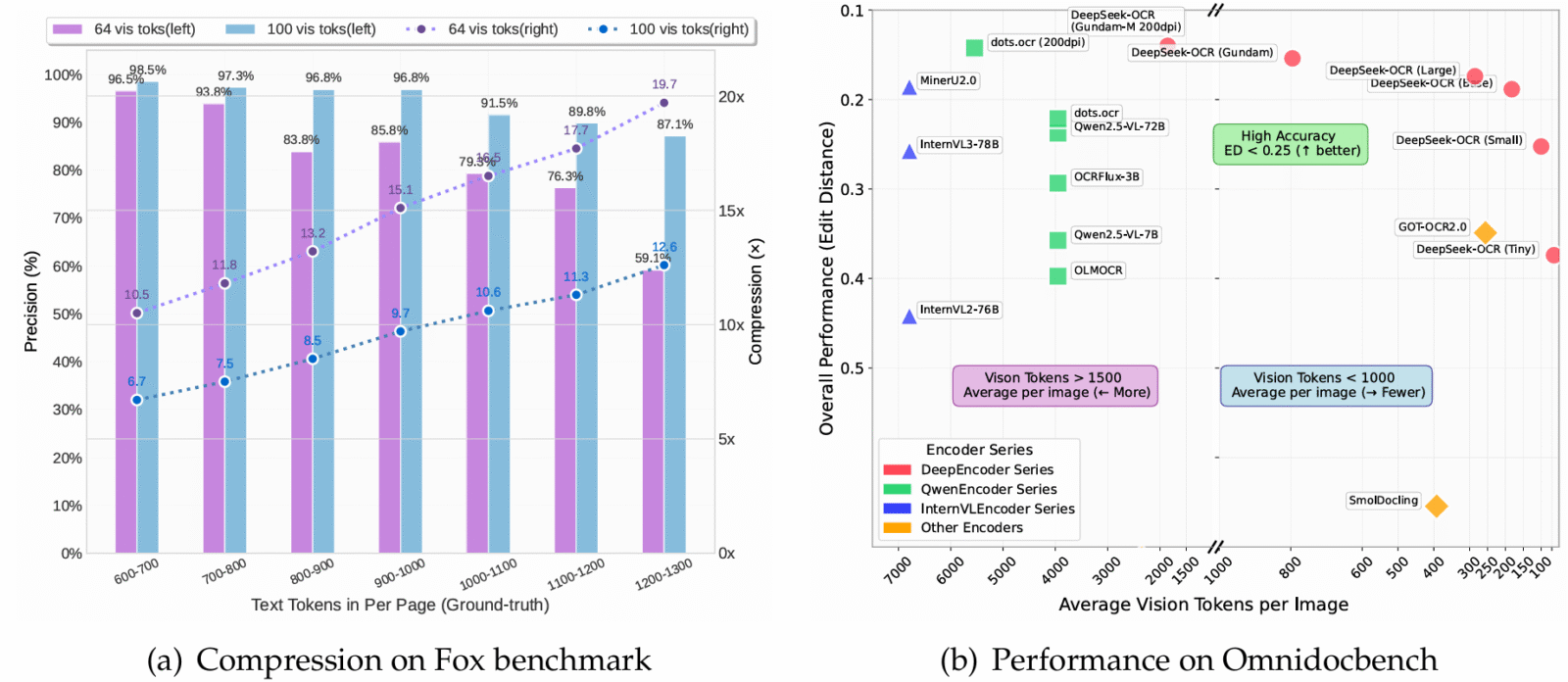
On benchmarks such as OmniDocBench, it surpasses competitors that consume far more tokens. This represents a paradigm shift where vision becomes an ally in making LLMs lighter, faster, and above all, smarter.
[1] Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the Middle: How Language Models Use Long Contexts (arXiv preprint arXiv:2307.03172).
[2] Wei, H., Sun, Y., & Li, Y. (2025). DeepSeek-OCR: Contexts Optical Compression (arXiv preprint arXiv:2510.18234).
[3] Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., & Girshick, R. (2023). Segment Anything (arXiv preprint arXiv:2304.02643).
[4] Chen, H.-Y., Lai, Z., Zhang, H., Wang, X., Eichner, M., You, K., Cao, M., Zhang, B., Yang, Y., & Gan, Z. (2024). Contrastive Localized Language-Image Pre-Training (arXiv preprint arXiv:2410.02746).