Artificial Intelligence
What is a model of diffusion ?
The diffusion model is today one of the engines of the most popular AI generative, in particular, to create images from text. , This approach has powered tools such as Stable Diffusion, DALL·E or Midjourney on the front of the stage, because it generates detailed graphics and realistic, while remaining relatively stable in the training compared to other families of models. Understand what is a diffusion model helps to understand how these systems ‘think’ of the content and why they dominate the generation of images modern.
Diffusion model, the simple definition
A diffusion model is a generative model that learns to manipulate the sound. In a first time, it leads to a gradual change in a given clear, as an image, as in the covering of noise up to make it unrecognizable. Then, he learns the inverse operation, remove the noise, step-by-step to reconstruct the initial information. One can imagine it as a drop of ink spreading in the water, the model observes the broadcast, and then carries on to go up the film in the opposite direction.
Once the mechanism has been learned, it becomes able to create new data from scratch. We share a simple cloud of random noise, and the model refines gradually, step by step, up to the emergence of a coherent picture of. This progressive process makes the generation of more stable and more realistic than if the model was attempting to produce the final result of a single blow.
How does a model of diffusion ?
During training, the model learns two things, the way to go (turn a clear picture noise) and, especially, the way back (to remove noise in small steps). Technically, these steps often follow a Markov chain, and optimize with tools of probability as the behind variational inference, we adjust the model to reconstruct accurately the original data from images more and more noisy. Once trained, the model of scattering from a gaussian noise and applies the reverse sequence to generate a credible result.
In practice, it combines frequently a text encoder (which includes your prompt) with a diffusion model operating in a space latent, less space and easier to handle than the raw pixel. This formulation of ‘latent’ makes the generation of faster and more economic calculation, while retaining the fine detail.
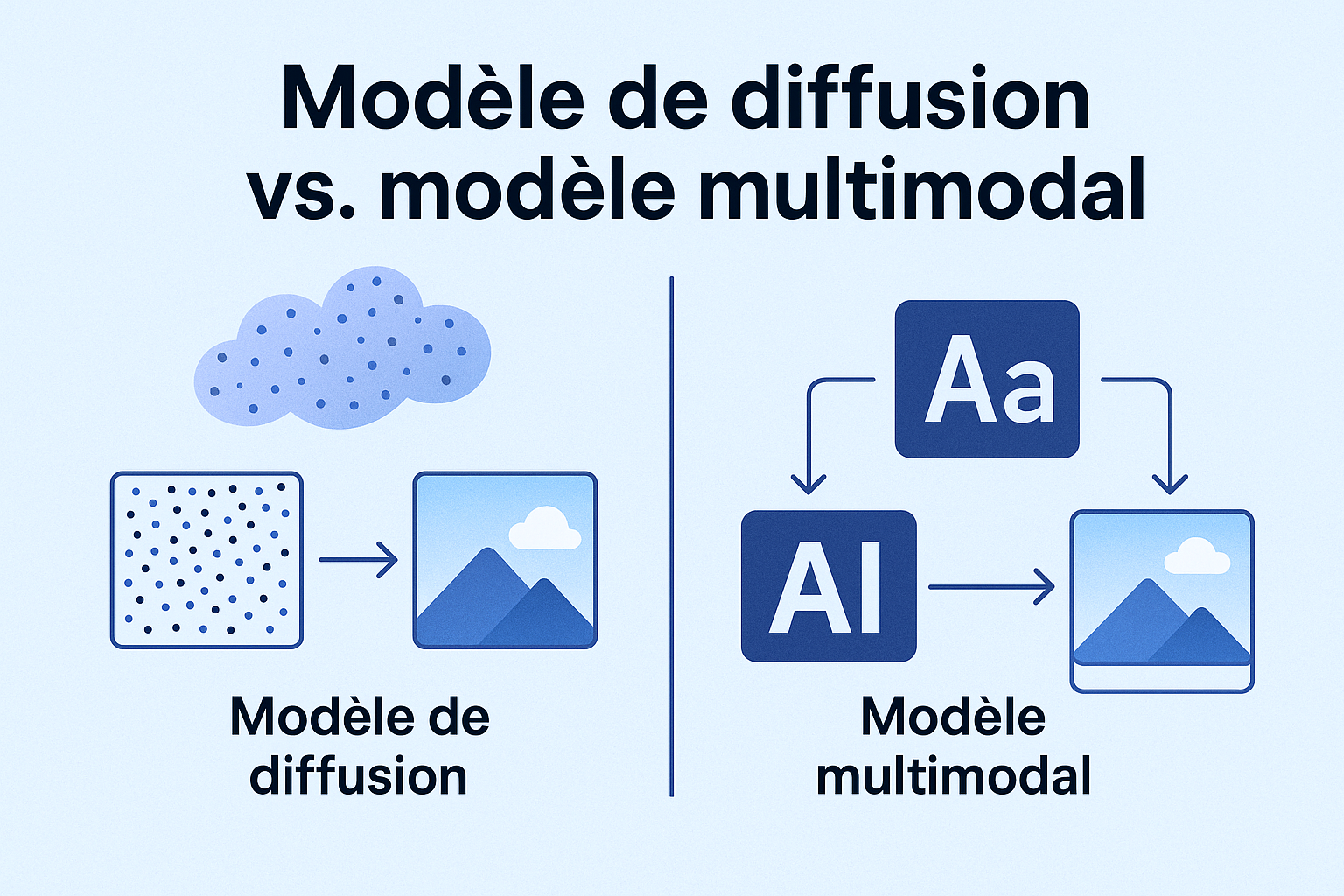
Diffusion model vs. model multimodal
A model multi-modal system is a system capable of understanding and/or to produce multiple types of data, such as text, images, audio or video. It is not a particular method, but rather a skill : linking various forms of information within a single model.
A diffusion model is based on a specific process for generating content. Its operation consists in starting from a cloud of random noise and to refine it gradually until you get an output consistent (often an image). So we can say that it is a model that uses the principle of denoising step-by-step to create.
The two ideas can be crossed, for example, when a system takes text as input and produces an image, it is multimodal (because it connects two different ways) and it can use a diffusion model as an engine to build the final image. In summary, the multimodality describes the types of data handled, while the diffusion describes the process used to generate these data.