Artificial Intelligence
VLP & VLM : Understand patterns vision-language
Do you ever dream of talking to a machine… by showing him a photo of your cat and asking him to write a poem on it ? Welcome to the world of VLM, these templates AI merging the vision and language to describe, understand, and sometimes even create ! In this article, we will lift the veil on their operation, their training methods and the different types that exist. The all-explained simply, with just enough of geek attitude to make you want to dive into the world of models of vision-language.
What is a VLM ?
A VLM (Vision-Language Model) is a model of artificial intelligence able to understand and manipulate both visual data (images, videos) and text (sentences, questions, descriptions). In contrast to a model of classical view that simply say ‘this is a dog’ with a percentage of confidence, a VLM can go much further, describe the scene in detail, answer questions about what he sees, or even connect this visual content to external information. To be clear, it is as if the AI had botheyes and a mouth.
The VLM does not come out of nowhere, they rely on a pre-training vision-language (VLPS) that teaches them how to connect pixels and words with millions of paired image–to-text. Once trained, they can perform a multitude of tasks : image captioning (generation of legends), visual question answering (answer questions about an image)… and much more. This blend of vision and language makes them particularly powerful for applications ranging frome-commerce to smart assistants, through scientific analysis.
How does a VLP ?
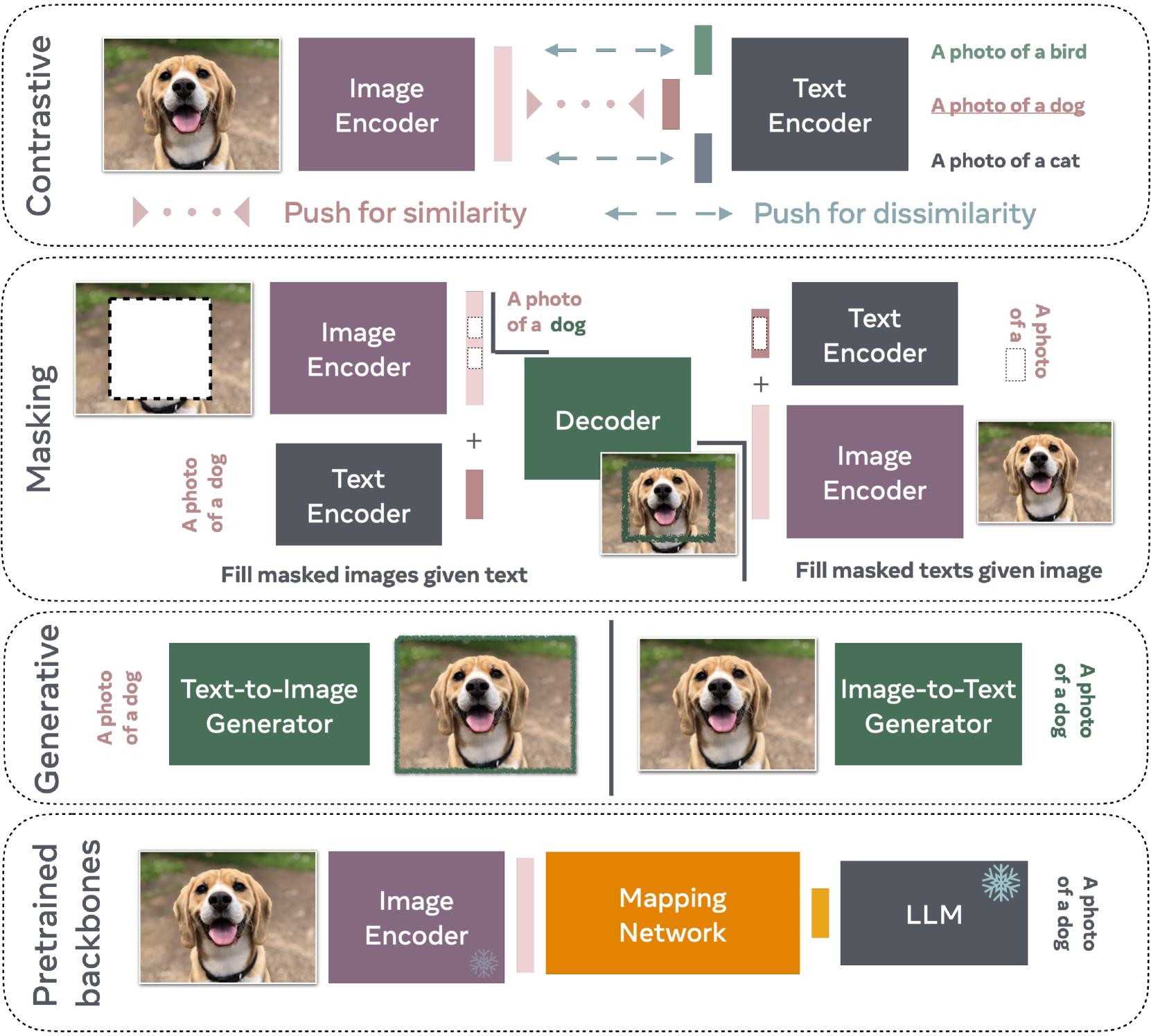
A VLP (Vision-Language Pretraining) is the learning stage that gives a future model vision-language the ability to relate what he sees to what he reads. During this pre-workout, it feeds the model with millions (or even billions) of paired image–to-text. The image goes through an encoder visual (often Vision to Transform or a neural network convolutional), which cutting into small areas and transforms each part in a vector digital. In parallel, the associated text is split into tokens by a tokenizer and then turned into vectors using an encoder of language (type-BERT or T5).
The magic happens when these two flows, visual and text are projected in the same space of representation. The model learns to approximate the vectors of an image and its correct text, and to remove those that do not match. To achieve this, several tasks of training are used : image-text matching (to guess if the image and the text go together), masked language modeling (guess the words missing thanks to the image), or masked region modeling (predicting what is hidden in a part of the image through the text). It is this step of VLPS , which gives VLM their “intuition” multimodal, which is essential to then describe, reply, or create.

The different types of VLM
All of the VLM are not the same thing, and there are several “families” according to their main objective. First, there is the descriptive models, specializing in the understanding and the generation of text from images. They are used for example to produce captions (image captioning), summarizing an illustrated article (multimodal summarization), or to answer questions about a picture (visual question answering). Models such as BLIP, BLIP-2 or LLaVA belong to this category.
Then, we have the creative designs, which work in the other direction, from a text, they generate a realistic image or artistic. This family includes the famous DALL·E, Stable Streaming and Image,. Even if their ultimate goal is the generation of visual, they are based on the same fundamental principles of alignment, text–image learned during pre-training vision-language (VLPS). Finally, there are models versatile able to converse in a way multimodal, alternating understanding and creation, sometimes also integrating the audio and the video, one more step towards wizards truly universal.
Practical Applications of the VLM
The VLM are already all around us, often without realizing it. In thee-commerce, they describe products automatically from photos, improving the ‘search by image’. In the media, they summarize the articles illustrated or generate the captions to make the content accessible. In scientific research, they help to analyze medical images by linking them to report or to detect abnormalities in visual data complexity. It is also found in the virtual assistants are able to answer questions about an image sent by the user, or still in education, where they explain patterns and graphs to students. In short, the VLM transform each image into a gateway to information.
Image credits to the a : Bordes, F., Pang, R. Y., Ajay A., et al (2024). an Introduction to Vision-Language Modeling arXiv:2405.17247v1, license arXiv.org.