Large Language Model
Understand LoRA and QLoRA : Fine-Tuning Techniques
Understanding LoRA and QLoRA means stepping into the fascinating world of fine-tuning artificial intelligence models without needing a GPU farm. These two techniques make it possible to adapt a large language model (LLM) to a new task, such as creating a specialized chatbot or analyzing medical texts, while using very few resources. In short, they allow you to customize an existing model without having to retrain it entirely from scratch.
So, what exactly are LoRA and QLoRA? LoRA is a simple method that adds small adaptation layers to a pre-trained model. QLoRA goes even further, it compresses the base model to make it lighter, then applies the same adaptation idea. This makes it possible to train very large models on a single graphics card while maintaining performance close to that of full-scale training. These techniques have become essential for anyone who wants to experiment, learn, or innovate with AI,even without powerful hardware resources.
What is an LLM?
An LLM, or Large Language Model, is an artificial intelligence program capable of understanding and generating text. It has learned by reading billions of words to predict the next word in a sentence. Thanks to this principle, it can write, summarize, translate, or even have conversations with us.
Imagine an LLM as a digital brain that has read almost the entire library of the internet. When we talk to it, it recalls everything it has seen before to guess the most logical answer. These models are extremely powerful but also very heavy to train; they contain billions of parameters, a bit like knobs to be fine-tuned. This is where LoRA and QLoRA come in,they make it possible to adapt this large brain to a specific task without having to relearn everything from scratch.
How LoRA Works
LoRA (Low-Rank Adaptation) is a smart way to make a large model more flexible without retraining everything. Normally, to teach a model a new task (for example, writing emails or answering medical questions), you would have to modify billions of parameters. That takes a lot of time, memory, and money.
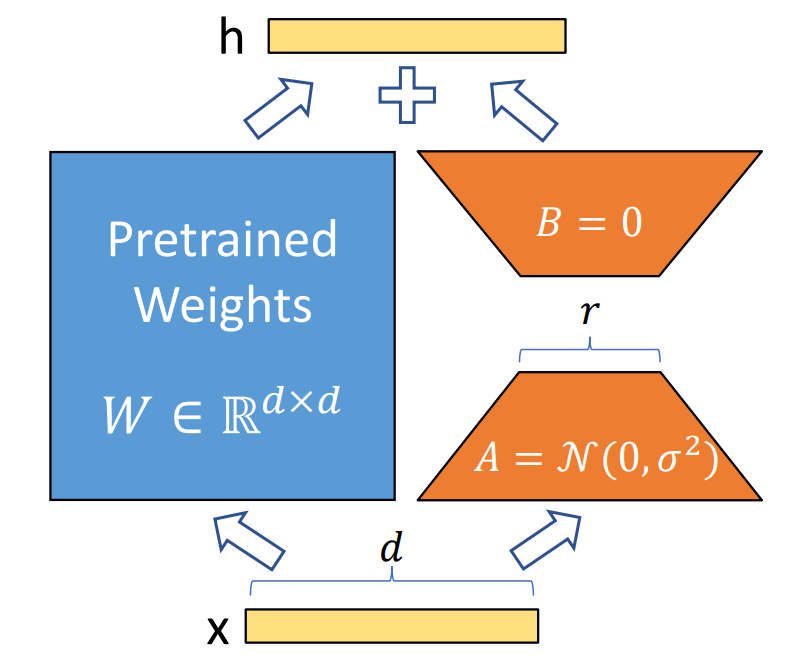
With LoRA, the base model is frozen, and only small learning components are trained at key points. These components learn the useful adjustments for your task (tone, vocabulary, style) without touching the rest of the model. It’s a bit like attaching a small extension module to a large piece of software, the core stays the same, but it gains a new capability. In technical terms, this method freezes the weights of the pre-trained model and adds low-rank adaptation matrices within each layer of the Transformer architecture. Since only a tiny portion of parameters is updated, training becomes lighter, faster, and more memory-efficient. This makes it possible to adapt a large model without powerful GPUs while preserving what it already knows.
Why use a low-rank adaptation matrix?
LoRA uses a low-rank matrix because it allows the model to learn only the essential changes needed without retraining everything. A language model already holds a vast amount of general knowledge, so to adapt it to a specific task, it’s enough to adjust a few important directions in its computations rather than the entire network. A low-rank matrix does exactly that, it captures the main variations in a simple and efficient way.
In contrast, a high-rank matrix would contain much more information and detail but would be heavy to train and very memory-intensive. Choosing a low rank is therefore a smart compromise, it preserves the model’s performance while making adaptation faster, lighter, and accessible even with limited resources.
Advantages of LoRA
One of LoRA’s biggest strengths is its lightness, only tiny additional modules are trained, which greatly reduces GPU memory usage and allows teams with limited resources to experiment. As a result, training times are much faster, often a matter of hours instead of several days.
Another key advantage is modularity, you can create multiple adapters tailored to different tasks (summarization, translation, chatbots, medical domain, etc.) and activate them as needed without retraining the entire model. This also makes sharing or reusing them across projects much easier. LoRA also helps preserve the original model’s knowledge, since the main weights remain untouched, it reduces the risk of erasing what the model already knows (avoiding “catastrophic forgetting”). This makes adaptation more robust, especially when working with a small dataset for the target task.
What is model quantization?
To better understand QLoRA, let’s first talk about quantization. Quantization is a technique used to reduce the size of a model without significantly losing quality. Visually, it’s like turning a very high-resolution photo into a lighter version that still looks sharp. Instead of storing each model value with high precision (16 or 32 bits), smaller values are used, often 8 bits or 4 bits. This means each parameter takes up less memory, and computations run faster.
Thanks to this idea, a model that originally weighed around 60 GB can shrink to about 15 GB while keeping similar results. For those without powerful graphics cards, this is a real game-changer, it allows very large models to run on modest hardware. That’s exactly what QLoRA takes advantage of : first quantifying the model to make it lighter, then adapting it with small learning additions, just like LoRA.
Difference Between Low-Rank (LoRA) and Quantization
Low-Rank (used in LoRA) reduces the complexity of what is being learned, the base model remains unchanged, and only small modules are trained to capture the essential information for the new task. Quantization (at the core of QLoRA) reduces the model’s memory size by storing its numbers with lower precision (for example, 4 bits instead of 16) without altering the model’s overall logic.
| Concept | LoRA (Low-Rank) | Quantization (QLoRA) |
|---|---|---|
| Goal | Reduce the complexity of what needs to be learned | Reduce the model’s memory size |
| What’s modified | Small adapters added to the frozen model | The numeric precision of the weights (e.g., 4 bits) |
| Main effect | Fewer parameters to train, faster training | Lighter model, more efficient computations |
| Analogy | Learning the main melody of a song | Compressing the audio so it takes up less space |
| Link with QLoRA | Adaptation technique | Compression step before adaptation |
How QLoRA Works
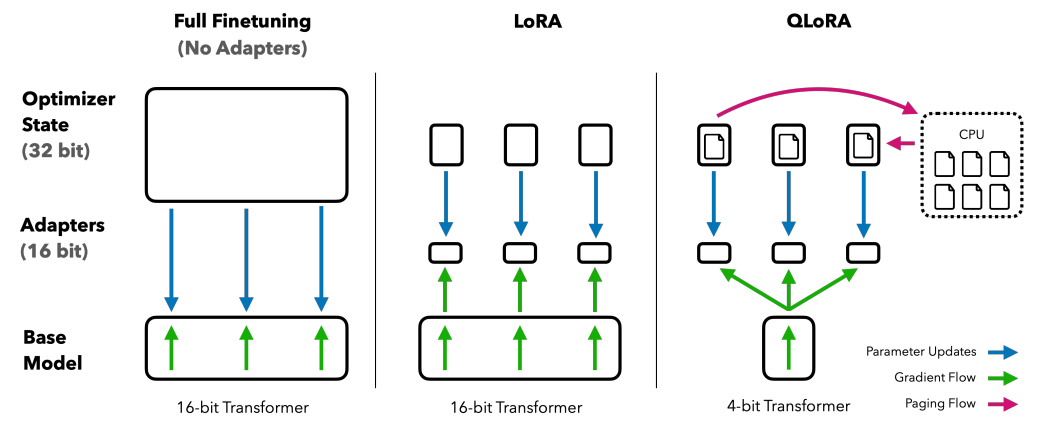
QLoRA (Quantized Low-Rank Adapter) builds on the same principle as LoRA but goes even further to save memory. Before adding its small learning layers, QLoRA quantizes the model, that is, it makes it lighter by reducing the precision of the numbers it processes. Thanks to this step, a very large model can fit into a much smaller graphics card without losing much performance. Once the model is quantized, QLoRA applies the same mechanism as LoRA, it freezes the compressed model and adds small adaptation modules that learn the new information needed for the task. Training therefore remains fast, inexpensive, and achievable on limited hardware.
In practice, QLoRA makes it possible to adapt giant models (those with tens of billions of parameters) on a single GPU or even on a high-end personal computer. This approach opens the door to many more developers, researchers, and enthusiasts who want to customize powerful models without complex infrastructure.
Simply put, QLoRA = quantization + LoRA. The model’s size is reduced so it fits into memory, then it’s efficiently adapted to a new task. This combination is what makes QLoRA such a popular solution for modern fine-tuning of large language models.
Advantages of QLoRA
The main advantage of QLoRA is its high memory efficiency. By quantizing the model before adapting it, it becomes possible to work with very powerful models on a single GPU, or even on a high-end personal computer. This paves the way for fine-tuning that’s accessible to everyone, without the need for heavy infrastructure.
QLoRA also keeps the model’s quality very close to that of full training. Even though the weights are reduced in precision, the method preserves the core capabilities of the base model. You get a good balance between performance and lightness. Another benefit is training speed : as with LoRA, only small adaptation modules are updated, which greatly reduces compute time. And because the model is more compact, the whole process is even smoother.
LoRA vs QLoRA : How to choose ?
LoRA and QLoRA share the same idea, adapting a large model without having to retrain everything. The difference mainly comes down to available memory and the size of the model you want to use. If your model already fits in memory (for example, a 7B or 13B model) and you have a GPU with good capacity, LoRA is more than enough. It is simple to set up, fast to train, and will let you create multiple adapters without complication.
Conversely, if your graphics card is limited or you want to adapt a larger model (such as 30B, 65B, or more), then QLoRA is the better option. By quantizing the model first, QLoRA significantly reduces the required memory while maintaining excellent performance. It is the ideal method when you want to take advantage of powerful models with modest hardware.
To make it simple :
- LoRA is preferred when you have enough memory and you want to go fast.
- QLoRA is the right choice when VRAM is limited or when you want to work with very large models.
How to use LoRA or QLoRA ?
Today, there are several tools that make it much easier to use LoRA and QLoRA to adapt a language model to a specific task. These tools help you avoid the technical complexity of traditional fine-tuning and focus on the end goal, making your model learn exactly what you want.
Among the most widely used is Unsloth, a very popular solution that lets you fine-tune an LLM with LoRA or QLoRA in just a few lines of code. Unsloth automatically handles model preparation, quantization, training, and even performance tracking, which makes it ideal for both beginners and advanced users.
In a future article, I will share the full process for easily fine-tuning a language model on specific tasks (such as summarization, chat, or classification) using LoRA, QLoRA, and Unsloth. This practical guide will show how to turn a base model into a truly customized tool without needing a supercomputer.
[1] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models (arXiv preprint arXiv:2106.09685).
[2] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient finetuning of quantized LLMs (arXiv preprint arXiv:2305.14314).





