
Robotique
DINOv2 à la NASA : Vision planétaire
De petits rovers capables de “voir” et de comprendre leur environnement comme de grands : c’est l’idée derrière DINOv2 chez la NASA. Le Jet Propulsion Laboratory (JPL) s’appuie sur ce modèle de vision pour offrir à ses robots une perception plus fiable, un prérequis pour se déplacer, repérer des zones d’intérêt et prioriser les observations loin de la Terre, là où la connexion est rare et les terrains sont inconnus. L’initiative illustre la rencontre entre modèles fondation de vision et exploration planétaire, avec l’objectif d’augmenter l’autonomie scientifique sur le terrain.
DINOv2, un “langage visuel” généraliste pour l’espace
Créé par Meta AI, DINOv2 apprend sans annotations humaines et produit des représentations visuelles universelles utilisables pour de multiples tâches, de la reconnaissance de scènes à la segmentation ou à l’estimation de la profondeur. En clair, le modèle fournit un “langage visuel” commun qui reste pertinent quand le décor change, un atout majeur pour des destinations comme Mars ou la Lune, où les données d’entraînement sont, par définition, limitées. Les auteurs montrent que l’auto-supervision à grande échelle sur des images variées suffit à obtenir des features robustes, performantes sans ajustement lourd et capables de se transférer d’un contexte à l’autre. Pour l’exploration planétaire, DINOv2 coche donc la case de la généralisation et de la sobriété en données annotées.
JPL met en place un moteur de perception unifié
Pour exploiter DINOv2 sur des robots réels, JPL a conçu la Visual Perception Engine, un cadre logiciel qui branche un modèle fondation (DINOv2) à plusieurs “têtes” spécialisées. À partir d’une même image de caméra, le système extrait les caractéristiques visuelles avec DINOv2, puis déclenche des modules qui, chacun, produisent une sortie utile à la mission : profondeur monoculaire pour comprendre la géométrie de la scène, segmentation sémantique pour distinguer sol, rochers ou ciel, et détection d’objets pour identifier des cibles. Cette approche factorisée évite de dupliquer l’effort d’analyse et simplifie la maintenance d’une mission à l’autre.
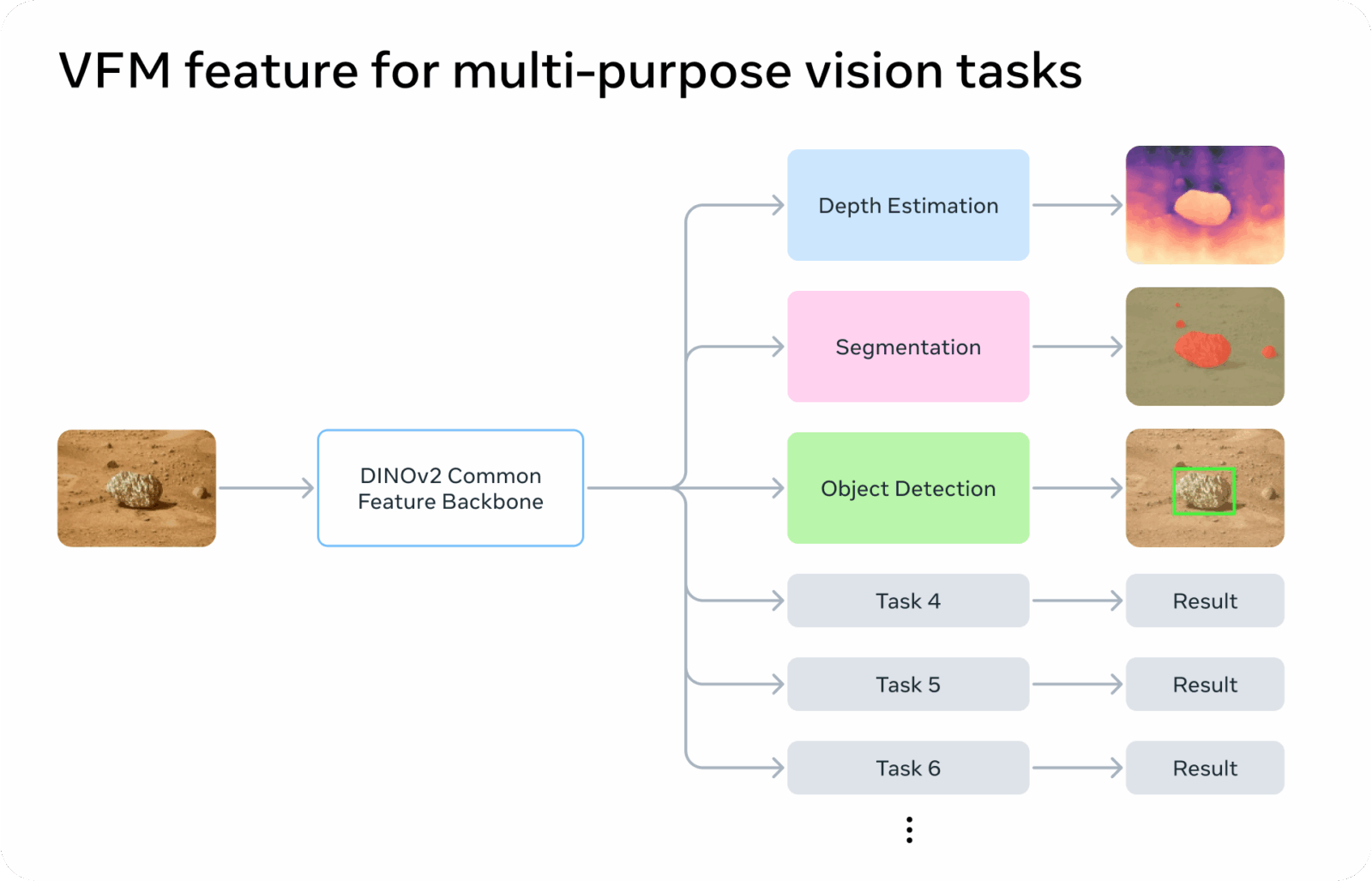
JPL diffuse ce moteur sous licence open source et fournit une intégration ROS 2 pour l’écosystème robotique. Pour les équipes qui développent des rovers, des drones ou des plateformes expérimentales, cela signifie qu’il devient possible de réutiliser DINOv2 comme brique commune de perception et d’ajouter (ou remplacer) des têtes selon le besoin scientifique, sans réécrire toute la pile. L’ouverture du code et de la documentation facilite aussi l’audit et l’adoption par la communauté.
Une vraie avancée pour l’exploration planétaire
Sur une autre planète, la latence des communications impose d’embarquer davantage d’intelligence à bord. Avec DINOv2 chez la NASA, la perception devient plus robuste face aux variations d’éclairage, de texture et de milieu, ce qui améliore la navigation autonome et réduit les risques d’impasse. Surtout, l’unification autour d’un même noyau visuel permet d’aligner la priorisation scientifique sur le terrain, un robot peut décider plus vite où aller, quoi regarder, et quand envoyer un résumé aux équipes au sol.
Cette évolution s’inscrit dans une tendance lourde de l’IA. L’usage de modèles fondation en vision comme socle pour des systèmes embarqués. Ce qui se joue ici dépasse Mars. Les mêmes principes valent pour la robotique terrestre, inspection d’infrastructures, agriculture, secours, où la connectivité est incertaine et les scènes changent sans cesse. DINOv2, déjà éprouvé en recherche, devient une brique industrielle crédible pour des applications de terrain exigeantes, avec un chemin clair de la preuve de concept à l’opérationnel.











