Revue de Recherche
Génération de vidéos longues : MoC, Mixture of Contexts
La génération de vidéos longues est l’un des défis brûlants de l’IA générative. Les modèles actuels savent produire de courts clips de bonne qualité, mais peinent dès qu’il faut tenir la cohérence d’une histoire sur des dizaines de secondes ou plusieurs minutes. Une équipe mêlant Stanford, ByteDance Seed et d’autres institutions propose une piste ambitieuse, MoC ( Mixture of Contexts), un mécanisme d’“attention parcimonieuse” qui traite la mémoire longue comme un problème de recherche interne dans l’historique vidéo. Publié le 28 août 2025, ce travail repositionne la génération de vidéos longues comme une question d’accès sélectif au bon contexte au bon moment.
Pourquoi la génération de vidéos longues est difficile ?
Les modèles vidéo modernes reposent souvent sur des Diffusion Transformers avec une attention dense, dont le coût explose quadratiquement avec la longueur de la séquence. À l’échelle d’une minute en 480p, on parle de plus de 180 000 tokens, rendant l’entraînement et l’inférence très coûteux, voire intractables. Les approches classiques contournent le problème en compressant le passé (résumés, keyframes, latents) ou en imposant des patrons d’attention clairsemés et fixes. Mais ces compromis sacrifient des détails, n’apprennent pas ce qui compte vraiment à l’instant T, et finissent par casser la cohérence narrative sur la durée. MoC change de point de vue, il apprend à router dynamiquement l’attention vers quelques morceaux de contexte réellement utiles.
MoC, Mixture of Contexts
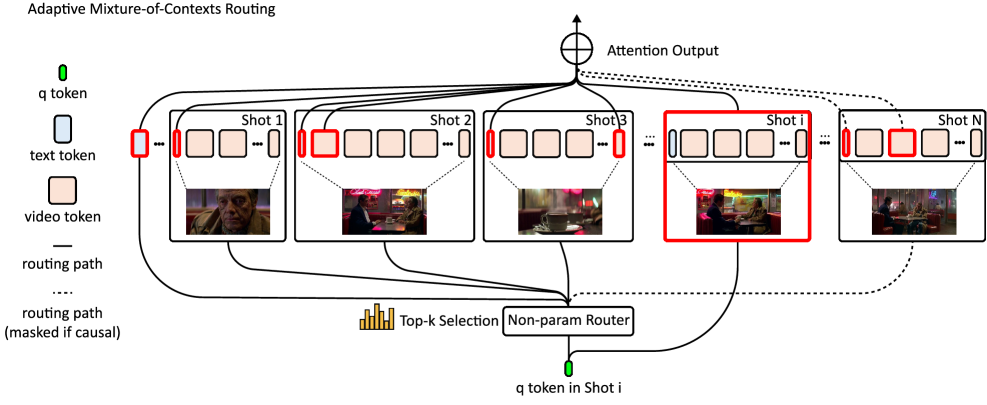
Concrètement, MoC découpe le flux multi-modal (texte + vidéo) en “chunks” alignés sur des frontières naturelles (images, plans, segments de texte). Pour chaque requête d’attention, le modèle sélectionne quelques chunks informatifs via un top-k appris, tout en gardant deux ancres obligatoires, les liens vers tous les tokens texte et une fenêtre locale intra-plan pour préserver la fidélité. Un masque causal évite les boucles d’information et stabilise les roll-outs sur des séquences de l’ordre de la minute. Résultat, l’attention devient quasi linéaire dans le nombre de contextes réellement récupérés, plutôt que quadratique dans toute la séquence. Cette Mixture of Contexts se greffe sur une DiT sans changer sa recette d’entraînement, et alloue le calcul aux événements saillants qui portent l’identité, l’action et la mise en scène.
Dans la pratique, l’équipe montre aussi un “outer loop routing”, une présélection coarse des grands segments avant l’attention fine. Cette hiérarchie permet d’étendre les contextes à très grande échelle, jusqu’à multiplier par 2 à 3 le nombre de plans générables de manière robuste.
Ce que MoC change pour la vidéo générative
MoC s’inscrit dans la continuité de travaux comme Long Context Tuning (LCT), qui étend la fenêtre de contexte pour apprendre la cohérence multi-plans… mais en attention dense, donc avec un plafond de coûts. En apprenant la parcimonie, Mixture of Contexts apporte un levier de scalabilité indispensable à la génération de vidéos longues, la mémoire devient un problème de retrieval, pas de force brute. On s’ouvre alors des usages concrets, storyboards animés, publicité multi-scènes, éducation narrative, prévisualisation ciné ou jeux, et simulation plus stable sur la durée. Les auteurs rappellent toutefois les risques d’abus (désinformation, contenus non consentis) et prônent des garde-fous classiques, gated release, filtrage de prompts, watermarking.
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, Maneesh Agrawala, Lu Jiang, & Gordon Wetzstein. (2025, August 28). Mixture of Contexts for Long Video Generation. arXiv.