Revue de Recherche
ManiFlow et DiT-X: La manipulation robotique générale
Imaginez un robot capable d’apprendre à manipuler n’importe quel objet, dans n’importe quel environnement, simplement en observant des vidéos ou en écoutant des instructions humaines. Ce rêve de la robotique, longtemps réservé aux laboratoires les plus avancés, se rapproche grâce à une nouvelle approche baptisée ManiFlow. Ce système d’apprentissage par imitation visuomotrice promet de révolutionner la façon dont les robots interagissent avec le monde physique, en alliant rapidité, précision et une capacité inédite à généraliser ses compétences.
Qu’est-ce que ManiFlow, et pourquoi c’est une avancée majeure ?
ManiFlow n’est pas un robot, mais une politique de contrôle, c’est-à-dire un algorithme intelligent qui décide des mouvements à effectuer. Son objectif ? Générer des actions robotiques complexes et précises en se basant sur des entrées visuelles (images ou vidéos), des commandes en langage naturel (“prends la tasse bleue”) et des données proprioceptives (la position des articulations du robot). Jusqu’ici, les systèmes existants butaient souvent sur la lenteur de calcul ou la difficulté à s’adapter à des situations inédites.
L’innovation de ManiFlow réside dans sa méthode d’apprentissage. Plutôt que d’utiliser les modèles de diffusion classiques, souvent gourmands en ressources et nécessitant de nombreuses étapes de calcul, les chercheurs ont opté pour une technique appelée flow matching avec entraînement par cohérence. En termes simples, cela permet au modèle de produire des mouvements d’une qualité exceptionnelle en seulement 1 ou 2 étapes d’inférence. C’est un gain de vitesse considérable, crucial pour les applications en temps réel où chaque milliseconde compte.
L’architecture DiT-X : le cerveau multimodal de ManiFlow
Pour traiter efficacement la diversité des entrées, une image, une phrase, la position du bras, ManiFlow repose sur une architecture neuronale sur mesure nommée DiT-X. Il s’agit d’un dérivé des “Diffusion Transformers”, des modèles très puissants dans le domaine de la génération d’images et de vidéos. DiT-X intègre deux mécanismes clés, l’attention croisée adaptative et le conditionnement AdaLN-Zero.
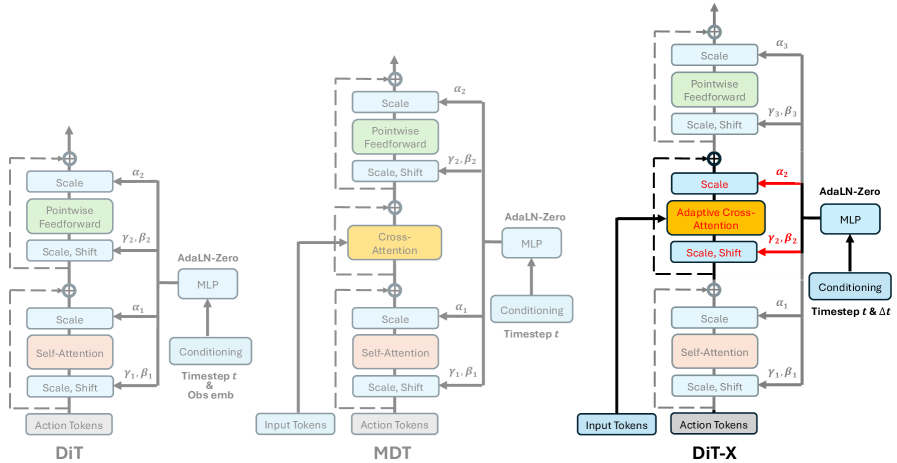
Ces termes techniques cachent une idée simple, mais puissante : permettre à chaque “token” d’action (représentant un mouvement du robot) d’interagir finement avec chaque élément des observations multimodales. Par exemple, quand le robot “voit” une tasse et entend “saisis-la”, DiT-X va établir un lien précis entre la position de la tasse dans l’image, le mot “saisis”, et les mouvements nécessaires de la main et du bras. Cette finesse d’interaction est ce qui permet à ManiFlow de gérer des tâches délicates avec une dextérité remarquable, que ce soit avec un bras, deux bras, ou même un robot humanoïde complet.
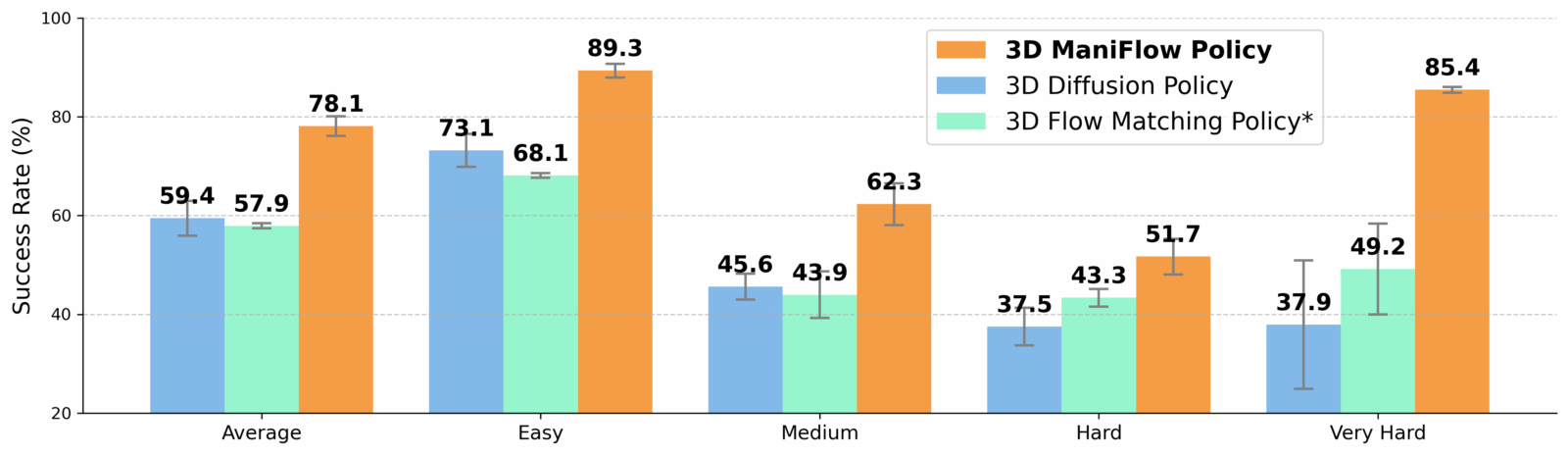
Les résultats parlent d’eux-mêmes. Dans les tests en simulation, ManiFlow surpasse systématiquement les méthodes précédentes. Mais le plus impressionnant se passe dans le monde réel, les taux de réussite des tâches manipulatoires ont été presque doublés par rapport aux meilleures approches existantes. Le système montre aussi une robustesse étonnante face à des objets jamais vus auparavant ou à des changements de décor, signe d’une véritable capacité de généralisation.
ManiFlow, vers des robots plus autonomes
La publication de ManiFlow arrive à un moment charnière. L’industrie et la recherche en robotique cherchent désespérément des solutions capables de s’adapter à des environnements non structurés, comme un entrepôt en désordre, un domicile ou un hôpital, sans avoir besoin d’être reprogrammées pour chaque nouvel objet ou chaque nouvelle tâche. ManiFlow répond précisément à ce besoin.

Son approche, qui combine imitation, multimodalité et génération rapide d’actions, s’inscrit dans la tendance plus large de l’IA vers des modèles “généralistes”. À l’instar des grands modèles de langage (LLM) qui peuvent répondre à une infinité des questions, ManiFlow vise à devenir un “LLM de la manipulation physique”. Sa capacité à monter en puissance avec des jeux de données plus larges suggère qu’il pourrait devenir encore plus performant à mesure que l’on accumulera des données d’interactions robotiques.
[1] Yan, G., Zhu, J., Deng, Y., Yang, S., Qiu, R., Cheng, X., Memmel, M., Krishna, R., Goyal, A., Wang, X., & Fox, D. (2025). ManiFlow: A general robot manipulation policy via consistency flow training. arXiv.