Revue de Recherche
FineVision : Le dataset multimodal de HuggingFace
Hugging Face continue de façonner l’avenir de l’intelligence artificielle avec une nouvelle contribution majeure, FineVision, un dataset multimodal d’une ampleur inédite. Composé de 24 millions d’échantillons, ce jeu de données vise à devenir la référence pour entraîner les prochains modèles de vision langage (VLM). Disponible publiquement, FineVision multimodal marque un tournant dans la qualité, la diversité et la rigueur de construction des données utilisées pour l’IA.
Un dataset multimodal pensé pour la finesse visuelle
Ce qui distingue FineVision de ses prédécesseurs, c’est son ambition en termes de volume et de qualité. Pour le construire, l’équipe HuggingFaceM4 a réuni plus de 200 jeux de données publics, combinant ainsi 17 millions d’images, 89 millions de paires question-réponse, et pas moins de 10 milliards de tokens de réponse. Au total, ce sont 5 téraoctets de données hautement qualitatives qui ont été assemblés.
Mais l’exploit ne réside pas seulement dans la quantité. Chaque échantillon a fait l’objet d’un traitement rigoureux, normalisation des formats, suppression des doublons et des données de faible qualité, puis conversion systématique en paires question-réponse, même pour les datasets initialement non dialogiques. Cette uniformisation est cruciale pour permettre un apprentissage fluide et cohérent des modèles.

Ce dataset FineVision est donc un outil puissant pour entraîner des modèles capables de répondre à des questions complexes sur une image, de générer des descriptions ultra-précises, ou encore de détecter des anomalies dans des contextes industriels ou médicaux.
Domaines sous-représentés, interaction homme-machine
FineVision ne se limite pas aux images et descriptions classiques. L’équipe a identifié un manque dans les données orientées interface utilisateur (GUI), essentielles pour entraîner des modèles capables d’interagir avec des écrans (navigateurs, applications, etc.). Pour combler ce vide, un nouveau sous-ensemble dédié aux actions GUI a été créé. Il repose sur des datasets existants, dont les formats spécifiques ont été normalisés vers un espace d’action généralisé, permettant aux modèles de comprendre des commandes comme « clique sur le bouton Play » ou « fais défiler vers le bas ».
Cette inclusion stratégique montre que FineVision multimodal est pensé non seulement pour la compréhension d’images, mais aussi pour l’action dans des environnements numériques, une capacité clé pour les assistants IA futurs.
Des modèles plus performants grâce à FineVision
L’objectif ultime de ce jeu de données FineVision ? Permettre à la communauté open source de développer des modèles multimodaux à la pointe. Et les résultats sont parlants, des tests approfondis (ablations) montrent que les modèles entraînés sur FineVision surpassent tous les autres sur 11 benchmarks courants, que ce soit en compréhension visuelle, raisonnement ou génération de texte.
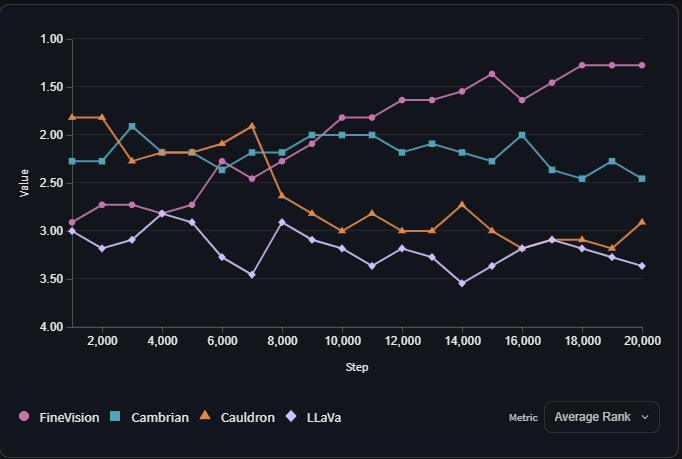
Cette supériorité s’explique par la diversité et la qualité du dataset multimodal, mais aussi par sa conception transparente et évaluable. Contrairement à certains datasets opaques utilisés par les grands acteurs privés, FineVision est entièrement ouvert, inspectable, et conçu pour la recherche reproductible.
Une avancée clé pour l’IA ouverte et multimodale
Le dataset FineVision n’est pas qu’un outil technique, c’est un manifeste pour une IA ouverte, rigoureuse et accessible. En mutualisant, nettoyant et évaluant massivement des données visio-linguistiques, Hugging Face offre à la communauté un levier puissant pour innover sans dépendre des géants de la tech.
Avec ce jeu de données FineVision, la barre est haute, désormais, la qualité des données est aussi cruciale que celle des modèles. Et si l’avenir de l’IA multimodale repose sur la capacité à voir, comprendre et agir, FineVision multimodal en est sans doute l’un des socles les plus solides à ce jour.
[1] Wiedmann, L., Zohar, O., Marafioti, A., Mahla, A., Frere, T., & von Werra, L. (2025). FineVision: Open Data Is All You Need. Hugging Face.