Revue de Recherche
FastVLM de Apple : Un Modèle Vision Language Ultra-Efficace
Apple, souvent perçu comme discret sur la scène de l’intelligence artificielle grand public, frappe fort avec FastVLM, un nouveau modèle vision-language (VLM) conçu pour comprendre les images avec une rapidité inégalée. Alors que la plupart des grands acteurs se concentrent sur des chatbots textuels, Apple mise sur une autre frontière, l’analyse visuelle en temps réel, directement sur les appareils. Ce n’est pas seulement une avancée technique, c’est une porte ouverte vers de nouvelles expériences, des lunettes intelligentes aux assistants accessibles.
Qu’est-ce que FastVLM et pourquoi c’est important ?
Un modèle vision-language (VLM) est un système d’IA capable de comprendre à la fois des images et du texte, et de répondre à des questions posées en langage naturel sur un contenu visuel. Par exemple, vous montrez une photo de rue à un VLM et vous lui demandez : « Qu’y a-t-il écrit sur ce panneau ? ». Pour fonctionner, ces modèles combinent un encodeur visuel (qui transforme l’image en données compréhensibles) et un grand modèle linguistique (LLM), chargé de générer la réponse.
Le problème ? Plus la résolution de l’image est élevée, plus le modèle est précis, surtout pour lire du texte ou reconnaître de petits objets. Mais traiter des images haute résolution ralentit considérablement le système. C’est ce qu’on appelle le dilemme entre précision et latence. Et c’est là que FastVLM change la donne.

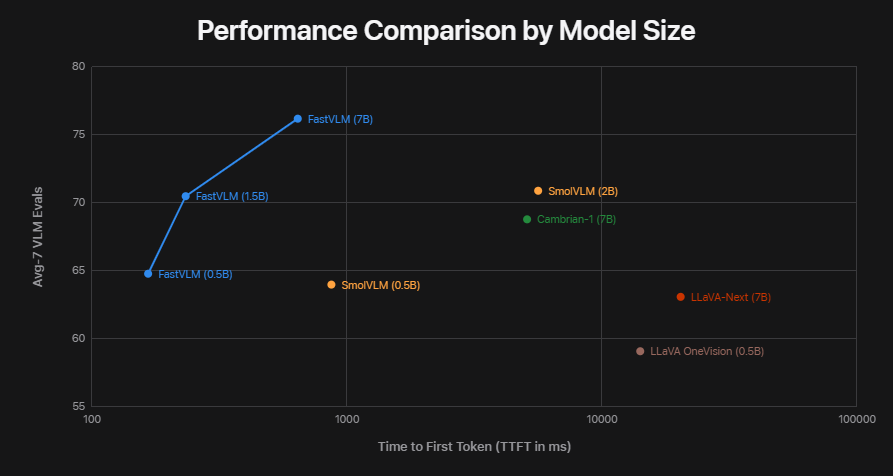
Développé par les chercheurs d’Apple et présenté lors de la conférence CVPR 2025, FastVLM est conçu pour offrir une haute précision sans sacrifier la vitesse. Il atteint des performances jusqu’à 85 fois plus rapides que des modèles comparables comme LLaVA-OneVision, tout en étant plus petit et plus économe en ressources. Il peut fonctionner en temps réel, même sur un iPhone.
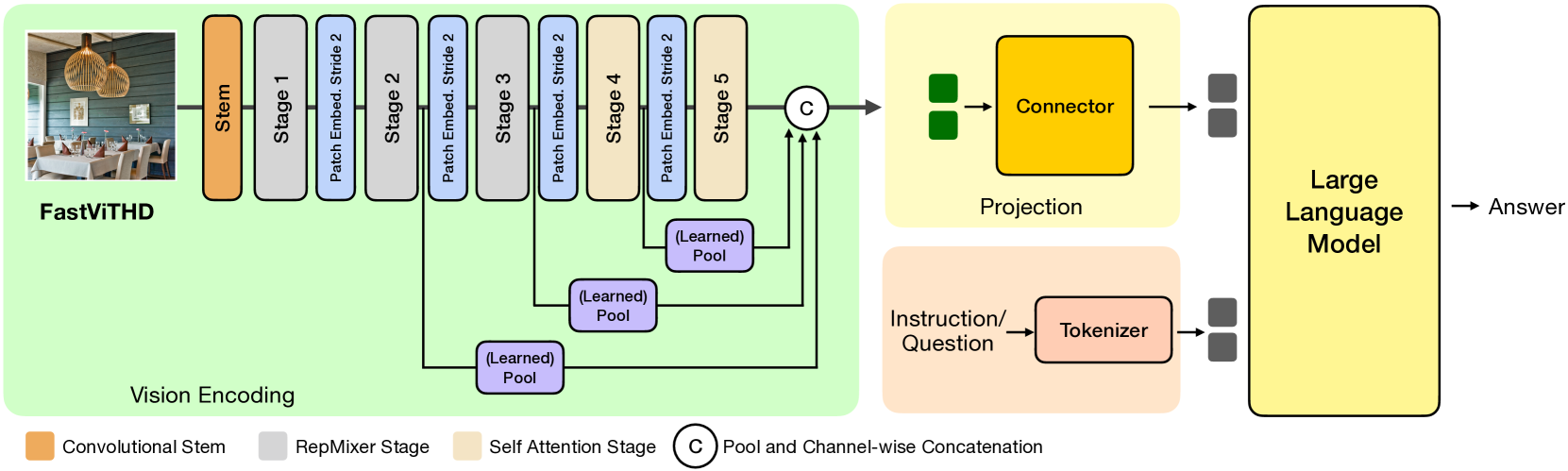
FastViTHD, le secret de l’efficacité de FastVLM
La clé du succès de FastVLM réside dans son encodeur visuel, nommé FastViTHD. Contrairement aux encodeurs classiques basés uniquement sur des réseaux de type Transformer (comme les ViT), FastViTHD adopte une architecture hybride, mêlant convolutions et blocs Transformer. Cette combinaison permet de réduire drastiquement le nombre de tokens visuels, les fragments d’information extraits de l’image, tout en conservant une riche compréhension visuelle.
Moins de tokens, c’est une double victoire :
- L’encodeur visuel travaille plus vite.
- Le LLM a moins de données à traiter en amont, ce qui réduit le time-to-first-token (TTFT), le temps d’attente avant que la réponse commence à s’afficher.
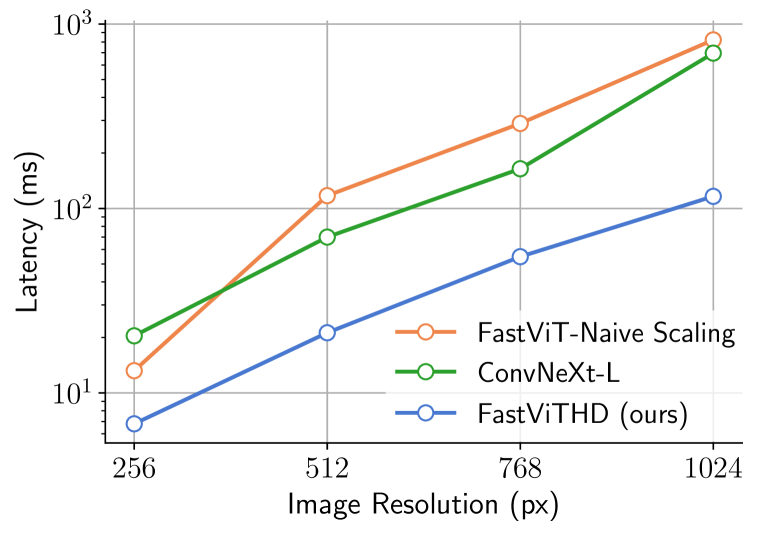
Ce qui rend FastVLM encore plus élégant, c’est qu’il n’a pas besoin de techniques complexes comme le pruning (élagage de tokens) ou le merging (fusion de tokens). Il obtient ses performances simplement en ajustant la résolution d’entrée. Moins de complexité, plus de fiabilité, une vraie innovation pour le déploiement en production.
Testable partout, conçu pour la confidentialité
L’un des aspects les plus intéressants de FastVLM, c’est sa disponibilité. Apple a publié non seulement les modèles et le code, mais aussi une démonstration accessible directement dans le navigateur via Hugging Face. Vous pouvez y connecter votre webcam et voir le modèle décrire en temps réel ce qu’il voit : « Une personne porte un t-shirt bleu », « Un chat dort sur le canapé », etc. Télécharger FastVLM ici.
Et contrairement à de nombreux modèles d’IA qui envoient vos données vers des serveurs distants, FastVLM peut fonctionner entièrement en local, sans connexion internet. C’est une avancée majeure pour la confidentialité. Vos images ne quittent jamais votre appareil. Cette approche s’inscrit parfaitement dans la philosophie d’Apple, mais elle ouvre aussi des portes à des applications critiques, assistants pour malvoyants, reconnaissance d’interface dans des environnements sensibles, ou encore navigation dans des zones hors ligne.
Vers des applications concrètes et embarquées
Alors, à quoi sert FastVLM ? Bien sûr, il peut générer des sous-titres automatiques pour des vidéos ou traduire des panneaux en temps réel pendant un voyage. Mais l’horizon est bien plus large. Cette technologie est un pilier essentiel pour les futurs dispositifs portables d’Apple, comme des lunettes intelligentes. Imaginez des verres capables de vous dire, en continu, ce qui se passe autour de vous, qui vous salue, ce que dit un menu, ou si vous êtes dans la bonne file d’attente.
FastVLM montre aussi une tendance claire en IA, l’optimisation on-device. Plutôt que de tout envoyer au cloud, l’industrie s’oriente vers des modèles plus petits, plus rapides, capables de fonctionner sur smartphone, montre ou casque. Apple, avec FastVLM et son framework MLX (spécialement optimisé pour les puces Apple Silicon), place la barre très haut.
Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel & Hadi Pouransari (2025). FastVLM: Efficient vision encoding for vision language models (arXiv:2412.13303v2). arXiv