Intelligence Artificielle
Qu’est-ce qu’un modèle de diffusion ?
Le modèle de diffusion est aujourd’hui l’un des moteurs les plus populaires de l’IA générative, en particulier pour créer des images à partir de texte. Cette approche a propulsé des outils comme Stable Diffusion, DALL·E ou Midjourney sur le devant de la scène, car elle génère des visuels détaillés et réalistes, tout en restant relativement stable à l’entraînement par rapport à d’autres familles de modèles. Comprendre ce qu’est un modèle de diffusion aide à saisir comment ces systèmes « imaginent » du contenu et pourquoi ils dominent la génération d’images moderne.
Modèle de diffusion, la définition simple
Un modèle de diffusion est un modèle génératif qui apprend à manipuler le bruit. Dans un premier temps, il s’entraîne à transformer progressivement une donnée claire, comme une image, en la recouvrant de bruit jusqu’à la rendre méconnaissable. Ensuite, il apprend l’opération inverse, retirer ce bruit étape par étape pour reconstruire l’information de départ. On peut l’imaginer comme une goutte d’encre qui se répand dans l’eau, le modèle observe la diffusion, puis s’exerce à remonter le film en sens inverse.
Une fois ce mécanisme appris, il devient capable de créer de nouvelles données à partir de rien. On part d’un simple nuage de bruit aléatoire, et le modèle l’affine progressivement, étape après étape, jusqu’à faire apparaître une image cohérente. Ce processus progressif rend la génération plus stable et plus réaliste que si le modèle tentait de produire le résultat final d’un seul coup.
Comment fonctionne un modèle de diffusion ?
Pendant l’entraînement, le modèle apprend deux choses, le chemin aller (transformer une image claire en bruit) et surtout le chemin retour (retirer le bruit par petites étapes). Techniquement, ces étapes suivent souvent une chaîne de Markov et s’optimisent avec des outils de probabilité comme l’inférence variationnelle, on ajuste le modèle pour qu’il reconstruise fidèlement les données d’origine à partir d’images de plus en plus bruitées. Une fois entraîné, le modèle de diffusion part d’un bruit gaussien et applique la séquence inverse pour générer un résultat crédible.
Dans la pratique, on combine fréquemment un encodeur de texte (qui comprend votre invite) avec un modèle de diffusion opérant dans un espace latent, un espace réduit et plus facile à manipuler que les pixels bruts. Cette formulation « latente » rend la génération plus rapide et plus économique en calcul, tout en conservant la finesse des détails.
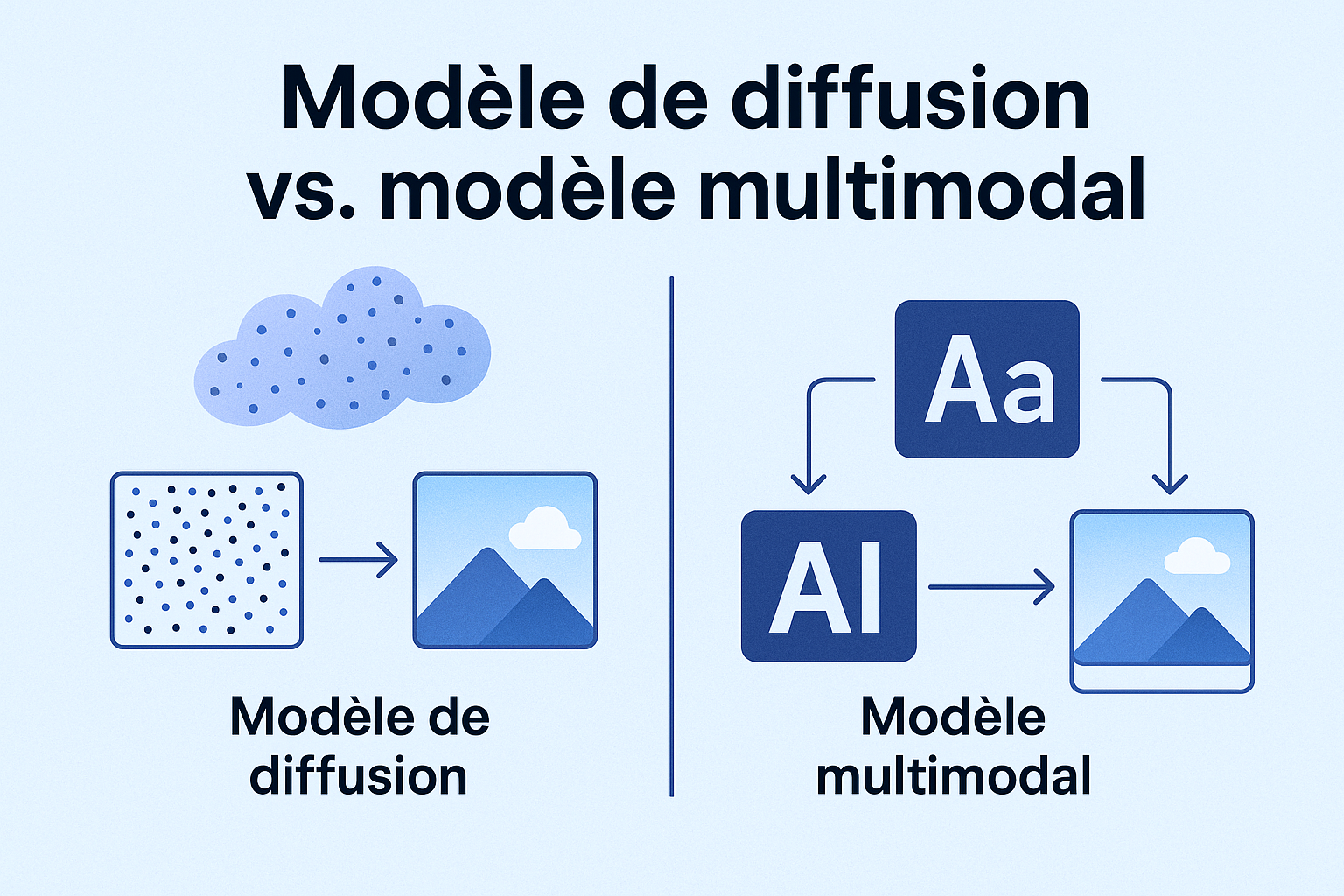
Modèle de diffusion vs modèle multimodal
Un modèle multimodal est un système capable de comprendre et/ou de produire plusieurs types de données à la fois, comme du texte, des images, du son ou de la vidéo. Il ne s’agit pas d’une méthode particulière, mais plutôt d’une compétence : relier différentes formes d’information au sein d’un même modèle.
Un modèle de diffusion, lui, s’appuie sur un processus spécifique pour générer du contenu. Son fonctionnement consiste à partir d’un nuage de bruit aléatoire et à l’affiner progressivement jusqu’à obtenir une sortie cohérente (souvent une image). On peut donc dire qu’il s’agit d’un modèle qui utilise le principe du « débruitage étape par étape » pour créer.
Les deux idées peuvent se croiser, par exemple, lorsqu’un système prend du texte comme entrée et produit une image, il est multimodal (parce qu’il relie deux modalités différentes) et il peut utiliser un modèle de diffusion comme moteur pour construire l’image finale. En résumé, la multimodalité décrit les types de données manipulés, tandis que la diffusion décrit le processus utilisé pour générer ces données.