





LLM
Comprendre LoRA et QLoRA : Des techniques du fine-tuning
Comprendre LoRA et QLoRA, c’est mettre un pied dans le monde fascinant du fine-tuning de modèles d’intelligence artificielle sans avoir besoin d’une ferme de GPU. Ces deux techniques permettent d’adapter un grand modèle de langage (LLM) à une nouvelle tâche, comme créer un chatbot spécialisé ou analyser des textes médicaux, tout en utilisant peu de ressources. En clair, elles offrent la possibilité de personnaliser un modèle existant sans devoir tout réentraîner depuis zéro.
Mais alors, c’est quoi LoRA ? Et que fait QLoRA ? LoRA, c’est une méthode simple qui ajoute de petites couches d’adaptation à un modèle déjà entraîné. QLoRA va encore plus loin, elle compresse le modèle de base pour le rendre plus léger, puis applique la même idée d’adaptation. Ce qui permet d’entraîner de très gros modèles sur une seule carte graphique tout en gardant des performances proches d’un entraînement complet. Ces techniques sont devenues essentielles pour quiconque veut expérimenter, apprendre ou innover avec l’IA, même sans gros moyens matériels.
C’est quoi un LLM ?
Un LLM, ou Large Language Model (grand modèle de langage), est un programme d’intelligence artificielle capable de comprendre et de produire du texte. Il a appris en lisant des milliards de mots pour prédire le mot suivant dans une phrase. C’est grâce à ce principe qu’il peut écrire, résumer, traduire ou même discuter avec nous.
Imaginez un LLM comme un cerveau numérique qui a lu presque toute la bibliothèque d’internet. Quand on lui parle, il se souvient de tout ce qu’il a vu dans le passé pour deviner la réponse la plus logique.
Ces modèles sont très puissants, mais aussi très lourds à entraîner, ils contiennent des milliards de paramètres, un peu comme des boutons à ajuster. C’est là que LoRA et QLoRA entrent en jeu, elles permettent d’adapter ce grand cerveau à une tâche précise, sans devoir tout réapprendre depuis zéro.
Fonctionnement de LoRA
LoRA (Low-Rank Adaptation), c’est une façon intelligente de rendre un grand modèle plus souple sans tout réentraîner. Normalement, pour apprendre une nouvelle tâche à un modèle (par exemple écrire des mails ou répondre à des questions médicales), il faudrait modifier des milliards de paramètres. Cela prend beaucoup de temps, de mémoire et d’argent.
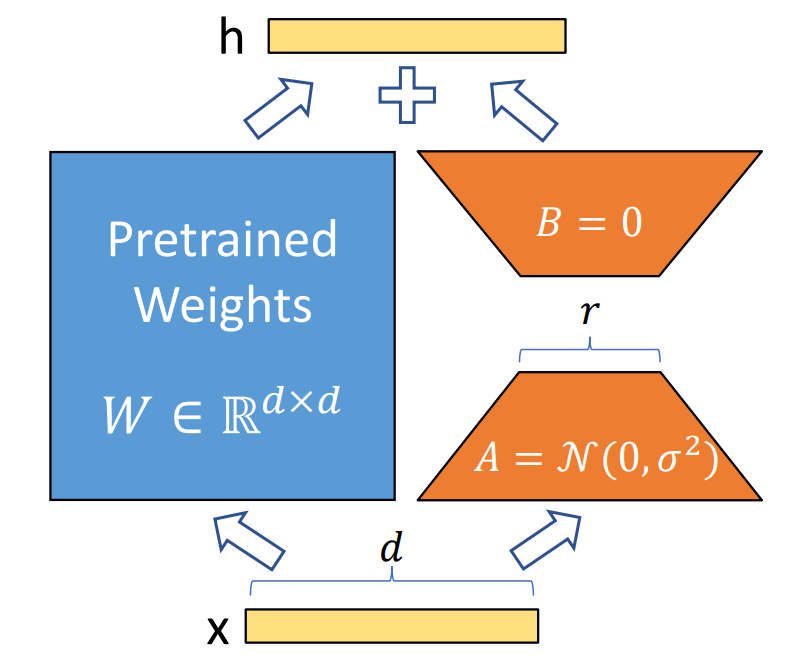
Pendant l’entraînement, ces matrices apprennent à ajuster légèrement la sortie du modèle (h) à partir de l’entrée (x), sans toucher aux poids de base, ce qui rend l’adaptation rapide et légère. Source [1]
Avec LoRA, on gèle le modèle de base et on n’entraîne que de toutes petites pièces d’apprentissage ajoutées à des endroits clés. Ces pièces apprennent les ajustements utiles à votre tâche (ton, vocabulaire, style) sans toucher au reste du modèle. C’est un peu comme coller un petit module d’extension sur un gros logiciel, le cœur reste le même, mais il sait faire quelque chose de nouveau. En bon terme, on parle d’une méthode qui gèle les poids du modèle pré-entraîné et ajoute des matrices d’adaptation à bas rang dans chaque couche de l’architecture Transformer. Comme on ne met à jour qu’un tout petit volume de paramètres, l’entraînement est plus léger, plus rapide et consomme moins de mémoire. Ce qui permet d’adapter un grand modèle sans gros GPU, tout en préservant ce qu’il sait déjà.
Pourquoi une matrices d’adaptation à bas rang (Low-Rank) ?
LoRA utilise une matrice à bas rang parce qu’elle permet d’apprendre seulement l’essentiel des changements nécessaires au modèle, sans tout réentraîner. Un modèle de langage contient déjà beaucoup de connaissances générales, pour l’adapter à une tâche précise, il suffit de modifier quelques directions importantes dans ses calculs, pas tout le réseau. Une matrice à bas rang sert justement à cela, elle capture les variations principales, de manière simple et efficace.
À l’inverse, une matrice à haut rang contiendrait beaucoup plus d’informations et de détails, mais serait lourde à entraîner et très coûteuse en mémoire. Le choix du bas rang est donc un compromis intelligent , on garde la performance du modèle tout en rendant l’adaptation plus rapide, plus légère et accessible même avec peu de ressources.
Avantages de LoRA
L’un des grands atouts de LoRA est sa légèreté, on n’entraîne que des modules additionnels minuscules, ce qui réduit fortement la consommation de mémoire GPU et permet à des équipes avec peu de ressources d’expérimenter. En conséquence, les temps d’entraînement sont beaucoup plus rapides, souvent de l’ordre de quelques heures plutôt que plusieurs jours.
Un autre avantage clé est la modularité, vous pouvez créer plusieurs adapters spécifiques à différentes tâches (résumé, traduction, chatbot, domaine médical, etc.) et les activer selon le besoin, sans retravailler le modèle entier. Cela facilite aussi le partage ou la réutilisation sur d’autres projets. LoRA aide également à protéger les connaissances du modèle d’origine, comme on ne touche pas aux poids principaux, on réduit les risques d’effacement de ce que le modèle sait déjà (on évite le “catastrophic forgetting”). Cela rend l’adaptation plus robuste, surtout quand on dispose d’un petit jeu de données pour la tâche cible.
La quantification de modèle, c’est quoi ?
Afin de mieux comprendre QLoRA, parlons d’abord de la quantification. La quantification est une technique qui permet de réduire la taille d’un modèle sans trop perdre en qualité. En image, c’est comme passer d’une photo de très haute définition à une version plus légère, mais encore nette. Au lieu de stocker chaque valeur du modèle avec une grande précision (16 ou 32 bits), on utilise des valeurs plus petites, souvent 8 bits ou 4 bits. Ce qui fait que chaque paramètre occupe moins de mémoire et les calculs se font plus vite.
Grâce à cette idée, un modèle qui pesait par exemple 60 Go peut ne plus en faire qu’environ 15 Go, tout en gardant des résultats proches. Pour ceux qui n’ont pas de grosses cartes graphiques, c’est un vrai changement, on peut faire tourner de très grands modèles sur du matériel modeste. C’est exactement ce que va exploiter QLoRA, quantifier d’abord le modèle pour le rendre léger, puis l’adapter avec de petits ajouts d’apprentissage, comme avec LoRA.
Différence entre Low-Rank (LoRA) et Quantification
Le Low-Rank (utilisé par LoRA) réduit la complexité de ce qu’on apprend, on garde le modèle de base tel quel et on n’entraîne que de petits modules qui capturent l’essentiel pour la nouvelle tâche.
La quantification (au cœur de QLoRA) réduit la taille mémoire du modèle en stockant ses nombres avec moins de précision (par ex. 4 bits au lieu de 16), sans changer la logique globale.
| Concept | LoRA (Low-Rank) | Quantification (QLoRA) |
|---|---|---|
| Objectif | Réduire la complexité des changements à apprendre | Réduire la taille mémoire du modèle |
| Ce qu’on modifie | De petits adapters ajoutés au modèle gelé | La précision numérique des poids (ex. 4 bits) |
| Effet principal | Moins de paramètres à entraîner, entraînement plus rapide | Modèle plus léger, calculs plus économiques |
| Analogie | Apprendre la mélodie principale d’une chanson | Compresser l’audio pour qu’il prenne moins de place |
| Lien avec QLoRA | Technique d’adaptation | Étape d’allègement avant l’adaptation |
Fonctionnement de QLoRA
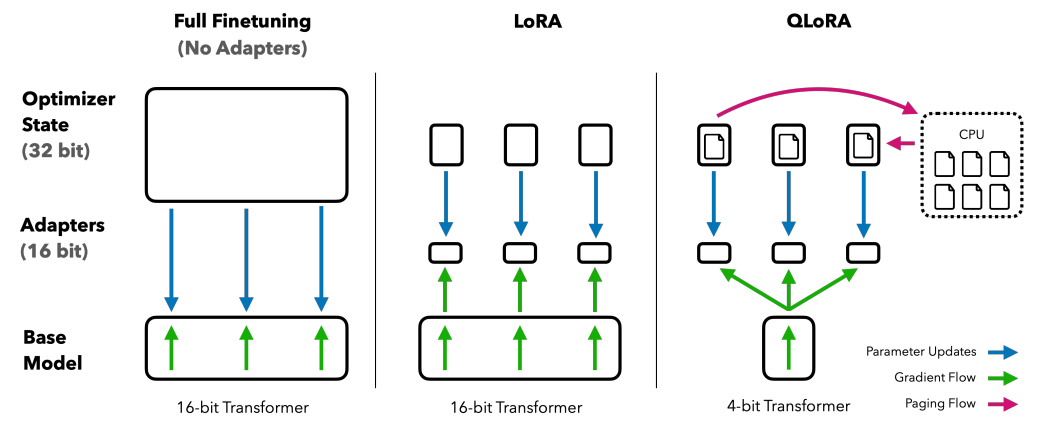
QLoRA (Quantized Low-Rank Adapter) reprend le même principe que LoRA, mais va encore plus loin pour économiser la mémoire. Avant d’ajouter ses petites couches d’apprentissage, QLoRA quantifie le modèle, c’est-à-dire qu’il le rend plus léger en réduisant la précision des nombres qu’il manipule. Grâce à cette étape, un très grand modèle peut tenir dans une carte graphique beaucoup plus petite, sans perdre beaucoup en performance. Une fois le modèle quantifié, QLoRA applique le même mécanisme que LoRA, il gèle le modèle compressé et y ajoute de petits modules d’adaptation qui apprennent les nouvelles informations utiles à la tâche. L’entraînement reste donc rapide, peu coûteux, et réalisable sur du matériel limité.
En pratique, QLoRA permet d’adapter des modèles géants (comme ceux de plusieurs dizaines de milliards de paramètres) sur un seul GPU ou même sur un ordinateur personnel haut de gamme. Cette approche ouvre la porte à beaucoup plus de développeurs, chercheurs ou passionnés qui souhaitent personnaliser des modèles puissants sans infrastructure complexe.
Pour faire simple, QLoRA = quantification + LoRA. On réduit la taille du modèle pour qu’il tienne en mémoire, puis on l’adapte efficacement à une nouvelle tâche. C’est cette combinaison qui fait de QLoRA une solution très populaire pour le fine-tuning moderne des grands modèles de langage.
Avantages de QLoRA
Le principal avantage de QLoRA est sa grande efficacité mémoire. En quantifiant le modèle avant de l’adapter, il devient possible de travailler avec des modèles très puissants sur un seul GPU, ou même sur un ordinateur personnel haut de gamme. Cela ouvre la voie à un fine-tuning accessible à tous, sans besoin d’une grosse infrastructure.
QLoRA garde aussi la qualité du modèle très proche de celle d’un entraînement complet. Même si les poids sont réduits en précision, la méthode conserve l’essentiel des capacités du modèle de base. On obtient donc un bon équilibre entre performance et légèreté. Un autre atout est la vitesse d’entraînement, comme pour LoRA, seuls de petits modules d’adaptation sont mis à jour, ce qui réduit fortement le temps de calcul. Et parce que le modèle est plus compact, tout le processus est encore plus fluide.
LoRA vs QLoRA : comment choisir ?
LoRA et QLoRA partagent la même idée, adapter un grand modèle sans avoir à tout réentraîner. La différence se joue surtout sur la mémoire disponible et la taille du modèle que tu veux utiliser. Si votre modèle tient déjà en mémoire (par exemple un modèle de 7 ou 13 milliards de paramètres) et que vous disposez d’un GPU avec une bonne capacité, LoRA suffit largement. Elle est simple à mettre en place, rapide à entraîner et te permettra de créer plusieurs adapters sans complication.
En revanche, si votre carte graphique est limitée ou que vous voulez adapter un modèle plus grand (comme 30B, 65B ou plus), alors QLoRA est la meilleure option. En quantifiant d’abord le modèle, QLoRA réduit considérablement la mémoire nécessaire tout en gardant d’excellentes performances. C’est la méthode idéale quand on veut tirer parti de modèles puissants avec un matériel modeste.
Pour faire simple :
- LoRA à privilégier quand vous avez assez de mémoire et que vous voulez aller vite.
- QLoRA à choisir quand la VRAM est limitée ou que vous voulez travailler avec des modèles géants.
Comment utiliser LoRA ou QLoRA ?
Aujourd’hui, il existe plusieurs outils qui facilitent énormément l’utilisation de LoRA et QLoRA pour adapter un modèle de langage à une tâche précise. Ces outils permettent d’éviter toute la complexité technique du fine-tuning classique, et de se concentrer sur l’objectif final, faire en sorte que votre modèle apprenne exactement ce que vous voulez.
Parmi les plus utilisés, on trouve Unsloth, une solution très populaire qui permet de fine-tuner facilement un LLM avec LoRA ou QLoRA, en quelques lignes de code. Unsloth gère automatiquement la préparation du modèle, la quantification, l’entraînement et même le suivi des performances, ce qui le rend idéal pour les débutants comme pour les utilisateurs avancés.
Dans un prochain article, je partagerai avec vous le processus complet pour fine-tuner facilement un modèle de langage sur des tâches spécifiques (comme le résumé, le chat ou la classification) en utilisant LoRA, QLoRA et Unsloth. Ce guide pratique montrera comment transformer un modèle de base en un outil vraiment personnalisé, sans avoir besoin d’un supercalculateur.
[1] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models (arXiv preprint arXiv:2106.09685).
[2] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient finetuning of quantized LLMs (arXiv preprint arXiv:2305.14314).





