Intelligence Artificielle
Mediapipe pour la détection d’objets
La détection d’objets est une tâche fondamentale de la vision par ordinateur, qui consiste à localiser et classifier des objets dans une image ou un flux vidéo. TensorFlow et PyTorch dominent traditionnellement ce domaine, mais Google a développé MediaPipe, une bibliothèque multiplateforme optimisée pour les applications en temps réel sur mobile, web et desktop. Dans cet article, nous explorerons comment utiliser MediaPipe pour la détection d’objets, de l’installation à la mise en production.
Mediapipe, c’est quoi ?
MediaPipe est une bibliothèque open source développée par Google, conçue pour le traitement efficace de flux multimédias, notamment la vidéo, l’audio et les données capteurs. Elle se distingue par son approche modulaire basée sur des graphes de calcul, permettant de construire des pipelines complexes de traitement de données en temps réel.
À l’origine pensée pour la vision par ordinateur, MediaPipe propose aujourd’hui une suite complète de solutions prêtes à l’emploi, optimisées pour fonctionner sur une variété de plateformes , desktop, mobile (Android/iOS), et même sur le Web via WebAssembly. Ces solutions incluent notamment la détection de visages (Face Detection), la reconnaissance de gestes (Hand Tracking), la segmentation de pose humaine (Pose Estimation), et bien sûr la détection d’objets.
Les modèles qu’il embarque sont optimisés pour les appareils mobiles avec des contraintes de calcul, tout en conservant une précision acceptable. De plus, il prend en charge l’exécution sur CPU, GPU et divers accélérateurs matériels, ce qui le rend adapté à une large gamme d’applications en temps réel.
Environnement de développement pour la détection d’objet
Avant de commencer à coder avec MediaPipe, il est important de mettre en place un environnement adapté pour gérer les dépendances et faciliter l’exécution du code. Pour les débutants ou ceux qui souhaitent se concentrer uniquement sur la partie développement, Google Colab est une excellente option : il fournit un environnement préconfiguré avec la plupart des bibliothèques nécessaires, sans nécessiter d’installation locale. Cela permet de gagner du temps et d’éviter les problèmes de compatibilité.
Cependant, si vous préférez exécuter votre code en local, vous pouvez installer Jupyter Notebook via Anaconda, une distribution Python populaire qui simplifie la gestion des paquets scientifiques. Anaconda est disponible gratuitement sur le site officiel https://www.anaconda.com
Installation et mise à jour des dépendances
Avant de commencer à utiliser MediaPipe, il est essentiel de configurer correctement votre environnement en installant et mettant à jour certaines bibliothèques clés. Si vous travaillez dans Google Colab, vous pouvez exécuter directement les commandes suivantes dans une cellule pour préparer votre environnement
!python --version
!pip install --upgrade pip
!pip install --upgrade numpy
!pip install mediapipe-model-maker
!pip install --upgrade --force-reinstall "tensorflow>=2.12,<2.14"L’ajout de la contrainte tensorflow>=2.12,<2.14 permet d’éviter certains conflits pouvant survenir avec des versions plus récentes ou incompatibles de TensorFlow. MediaPipe Model Maker et d’autres bibliothèques complémentaires peuvent en effet ne pas encore être pleinement compatibles avec les dernières mises à jour.
Importation des dépendances
Une fois l’installation et la mise à jour des bibliothèques terminées avec succès, vous pouvez procéder à l’importation des modules nécessaires au développement de votre application de détection d’objets. Voici les instructions à exécuter dans une cellule Colab ou dans votre notebook local.
import os
import json
import tensorflow as tf
# Vérification de la version de TensorFlow
assert tf.__version__.startswith('2'), "Assurez-vous d'utiliser TensorFlow 2.x"
# Importation du module de détection d’objets de MediaPipe
from mediapipe_model_maker import object_detectorLes données pour la détection d’objets
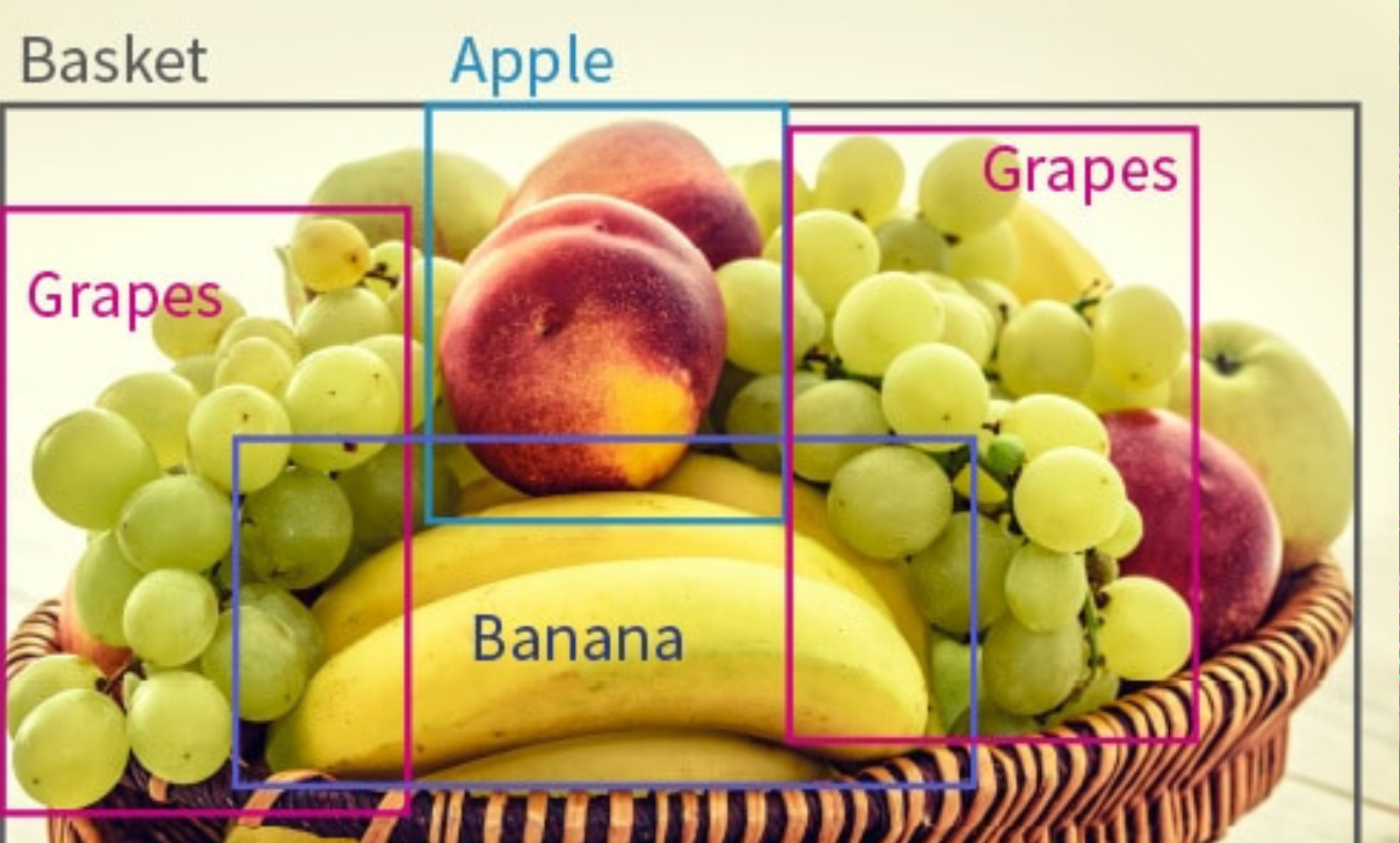
Pour entraîner un modèle de détection d’objets performant, il est indispensable de disposer d’un jeu de données correctement étiqueté, c’est-à-dire des images accompagnées de métadonnées indiquant la position et la classe des objets présents.
En pratique, ce jeu de données doit être divisé en trois sous-ensembles :
- Train : pour l’entraînement du modèle.
- Validation : pour ajuster les hyperparamètres et surveiller le surapprentissage.
- Test : pour évaluer les performances finales du modèle de manière objective.
L’étiquetage (ou annotation) des objets est une étape cruciale, car une mauvaise qualité des annotations impactera directement la précision du modèle. Des outils tels que LabelImg permettent de réaliser cette tâche manuellement. Toutefois, pour cette démonstration, nous allons utiliser un dataset déjà prêt, fourni par Google, afin de se concentrer sur l’entraînement du modèle.

Ajoutez le code suivant à une cellule de votre notebook pour télécharger et extraire le jeu de données :
# Télécharger et extraire le dataset d'exemple
!wget https://storage.googleapis.com/mediapipe-tasks/object_detector/android_figurine.zip
!unzip android_figurine.zip
# Définir les chemins vers les dossiers d'entraînement et de validation
train_dataset_path = "android_figurine/train"
validation_dataset_path = "android_figurine/validation"Chargement et conversion des données annotées
Une fois les images et leurs métadonnées prêtes, il faut les convertir dans un format compatible avec MediaPipe Model Maker. Dans notre cas, les annotations sont fournies au format JSON, l’un des formats courants pour la détection d’objets. Ce format encode notamment les coordonnées des boîtes englobantes et les classes associées, à l’instar des fichiers XML.
Heureusement, MediaPipe propose une méthode pratique pour charger automatiquement un dossier structuré selon ce format : from_coco_folder().
Voici comment charger les ensembles d’entraînement et de validation :
# Définition des chemins vers les datasets
train_dataset_path = "/content/android_figurine/train"
validation_dataset_path = "/content/android_figurine/validation"
# Chargement des données au format Pascal VOC
train_data = object_detector.Dataset.from_coco_folder(
train_dataset_path,
cache_dir="/tmp/od_data/train"
)
validation_data = object_detector.Dataset.from_coco_folder(
validation_dataset_path,
cache_dir="/tmp/od_data/validation"
)
# Affichage des tailles des ensembles de données
print("Taille du jeu d'entraînement :", train_data.size)
print("Taille du jeu de validation :", validation_data.size)Il est essentiel de respecter le format attendu en fonction de l’organisation du dossier.
Choix du modèle et entraînement
Une fois les données prêtes, nous pouvons passer à l’entraînement du modèle. Mais avant cela, une question cruciale se pose : quel modèle allons-nous utiliser ?
MediaPipe propose plusieurs modèles préentraînés optimisés pour différents besoins : rapidité, précision, taille mémoire, etc. Le choix du modèle est une étape déterminante, car il aura un impact direct sur les performances, la latence et la capacité du modèle à bien généraliser.
Dans notre cas, nous allons opter pour le modèle MOBILENET_MULTI_AVG, un modèle léger et efficace, adapté aux environnements contraints comme les applications mobiles ou les déploiements temps réel. Vous pouvez consulter la liste complète des modèles proposés par MediaPipe pour la détection d’objets dans la documentation officielle.
Configuration des hyperparamètres
Une fois le modèle choisi, il faut définir les hyperparamètres de l’entraînement. Ces derniers influencent fortement la qualité du modèle final. Voici un exemple de configuration basique avec un batch size de 8 et 10 époques d’entraînement :
# Choix du modèle supporté
spec = object_detector.SupportedModels.MOBILENET_MULTI_AVG
# Définition des hyperparamètres
hparams = object_detector.HParams(
batch_size=8,
epochs=10,
export_dir='exported_model' # Répertoire de sauvegarde du modèle entraîné
)
# Options de l'entraîneur
options = object_detector.ObjectDetectorOptions(
supported_model=spec,
hparams=hparams
)Les performances peuvent varier considérablement selon les hyperparamètres. N’hésitez pas à faire plusieurs essais (batch size, learning rate, nombre d’époques) pour trouver la configuration optimale en fonction de votre jeu de données. Vous trouverez à cette adresse les différents hyperparamètres et le type de valeur qu’elles prennent.
Lancer l’entraînement du modèle
Maintenant que le modèle est choisi et que les options d’entraînement sont définies, nous pouvons lancer l’entraînement. Cela se fait simplement à l’aide de la méthode ObjectDetector.create(), en lui fournissant les jeux de données et les options de configuration :
# Lancement de l'entraînement du modèle
model = object_detector.ObjectDetector.create(
train_data=train_data,
validation_data=validation_data,
options=options
)Cette étape peut prendre plusieurs minutes selon la taille de votre dataset et les ressources disponibles. Durant l’entraînement, vous verrez s’afficher des métriques comme la perte (loss) et la précision (accuracy) qui permettent de suivre l’évolution du modèle. Une fois l’entraînement terminé, le modèle sera automatiquement sauvegardé dans le répertoire spécifié par export_dir
Évaluation du modèle
Une fois l’entraînement terminé, il est crucial d’évaluer la performance de votre modèle pour savoir s’il est prêt à être utilisé en production. Dans un contexte rigoureux, l’évaluation doit être faite sur un jeu de test totalement indépendant, c’est-à-dire un ensemble de données que le modèle n’a jamais vu ni pendant l’entraînement, ni pendant la validation. Dans notre cas, pour simplifier la démonstration, nous utiliserons le jeu de validation comme base d’évaluation. Cela reste acceptable ici à des fins pédagogiques, mais à éviter dans un vrai projet.
Voici comment procéder à l’évaluation de votre modèle :
# Évaluation du modèle sur les données de validation
loss, coco_metrics = model.evaluate(validation_data, batch_size=4)
# Affichage des résultats
print(f"Validation loss: {loss}")
print(f"Validation COCO metrics: {coco_metrics}")Exportation du modèle et tests réels
Une fois que l’évaluation est terminée et que les métriques obtenues sont satisfaisantes, vous pouvez procéder à l’exportation de votre modèle afin de l’utiliser dans des contextes réels (mobile, desktop, web, etc.). MediaPipe simplifie cette étape avec une méthode dédiée :
from google.colab import files
model.export_model()
!ls exported_model
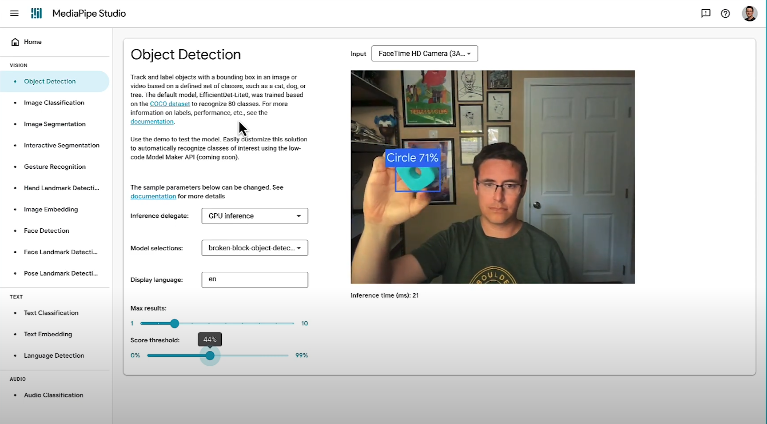
files.download('exported_model/model.tflite')Pour des tests rapides et visuels, vous pouvez utiliser MediaPipe Studio, une plateforme en ligne fournie par Google qui vous permet de tester vos modèles .tflite directement dans le navigateur. C’est un excellent moyen de valider votre modèle sans écrire une seule ligne de code supplémentaire.
Bilan et perspectives d’utilisation
Le parcours que nous venons de suivre montre à quel point il est aujourd’hui simple et accessible de construire un système de détection d’objets performant, même sans expertise approfondie en deep learning. Grâce à MediaPipe, Google propose un outil complet, efficace et multiplateforme, qui démocratise l’usage de la vision par ordinateur dans des projets concrets et en temps réel.
L’ensemble du projet présenté ici, incluant toutes les étapes suivantes :
- Préparer un environnement de travail fiable (Colab ou local)
- Utiliser un dataset annoté au JSON
- Choisir un modèle optimisé (comme MobileNet)
- Configurer l’entraînement avec des hyperparamètres adaptés
- Évaluer la performance du modèle à l’aide de métriques standardisées
- Exporter le modèle au format TFLite
- Tester rapidement le modèle via MediaPipe Studio
est disponible dans son intégralité ici : Mediapipe Model-Algo-mania. Cette approche modulaire permet de passer du prototype à l’application réelle en quelques étapes seulement. Que ce soit pour une application mobile de reconnaissance d’objets, un robot autonome ou un système de surveillance, MediaPipe fournit les outils nécessaires à chaque étape du projet.