Intelligence Artificielle
Large Language Models (LLM) : Comprendre ces géants de l’intelligence artificielle
Un Large Language Model, ou grand modèle de langage en français, est un modèle spécialisé dans la compréhension et la génération du langage humain.
Les grands modèles de langage ont bouleversé le paysage technologique ces dernières années. De ChatGPT à Gemini, ces systèmes capables de comprendre et de générer du texte comme un humain intriguent autant qu’ils fascinent. Mais derrière cette apparente magie se trouve une architecture bien précise et des principes scientifiques rigoureux. Explorons ensemble ce qui se cache vraiment derrière un LLM.
Qu’est-ce qu’un LLM exactement ?
Un Large Language Model, ou grand modèle de langage en français, représente une catégorie particulière de modèle d’intelligence artificielle spécialisé dans la compréhension et la génération du langage humain. Ces modèles sont entraînés sur des quantités phénoménales de données textuelles, ce qui leur permet d’apprendre les structures, les motifs et même les nuances subtiles du langage naturel.
La caractéristique fondamentale d’un LLM tient à sa taille colossale. Ces modèles se composent généralement de plusieurs milliards de paramètres, parfois même des centaines de milliards. Un LLM comme Llama 2 peut fonctionner avec un vocabulaire d’environ 32 000 tokens. Un token n’est pas exactement un mot, mais plutôt une unité d’information plus flexible qui peut représenter un mot complet, une partie de mot ou même un simple caractère.
Le principe de fonctionnement des LLM reste étonnamment simple dans son concept. Leur objectif principal consiste à prédire le token suivant dans une séquence, en se basant sur tous les tokens précédents. Cette prédiction successive, répétée des milliers de fois, permet de générer des textes cohérents et contextuellement pertinents.
L’architecture Transformer, le cœur des LLM
La quasi-totalité des LLM modernes repose sur une architecture appelée Transformer, introduite par Google avec son modèle BERT en 2018. Cette architecture a révolutionné le traitement du langage naturel grâce à son mécanisme d’attention particulièrement efficace.
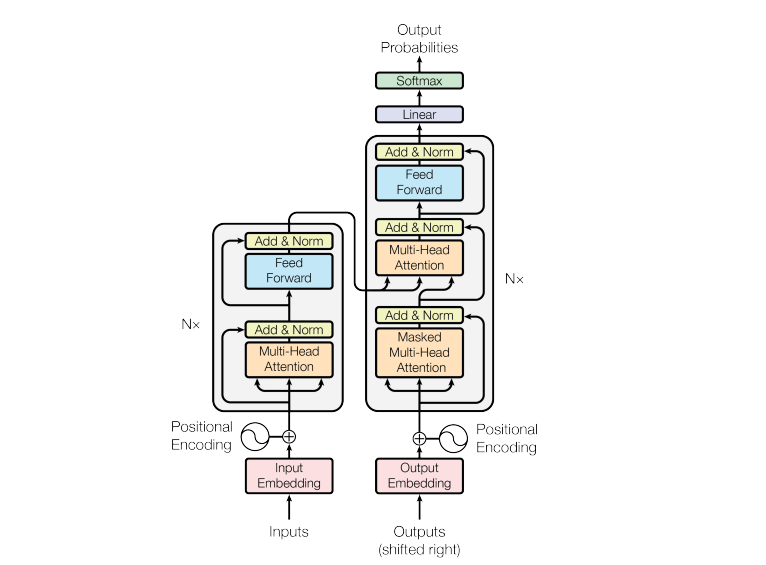
Un Transformer complet se compose de deux éléments principaux. L’encodeur convertit le texte d’entrée en une représentation intermédiaire dense, souvent appelée embedding. Cette représentation capture le sens profond du texte dans un format que la machine peut manipuler. Le décodeur prend ensuite cette représentation intermédiaire pour générer du texte de sortie utile, token par token.
Il existe trois grandes familles d’architectures basées sur les Transformers. Les modèles basés uniquement sur l’encodeur, comme BERT de Google, excellent dans les tâches de classification de texte, de recherche sémantique et de reconnaissance d’entités nommées. Les modèles basés sur le décodeur, comme la famille Llama de Meta, se concentrent sur la génération de nouveaux tokens et constituent la catégorie la plus courante de LLM modernes. Enfin, les modèles séquence-à-séquence combinent encodeur et décodeur pour des tâches comme la traduction.
Parmi les LLM les plus connus du marché, on retrouve GPT-4 d’OpenAI, Llama de Meta, Gemma de Google, ou encore Mistral. Chacun possède ses spécificités, mais tous partagent cette architecture fondamentale basée sur les Transformers.
Les tokens, l’alphabet des machines
Pour comprendre comment fonctionne un LLM, il faut saisir le concept de token. Contrairement à ce qu’on pourrait penser, les modèles de langage ne travaillent pas directement avec des mots entiers. Pour des raisons d’efficacité, ils découpent le texte en unités plus petites appelées tokens.

Cette tokenisation fonctionne souvent au niveau des sous-mots. Par exemple, les tokens « intéress » et « ant » peuvent se combiner pour former « intéressant« , ou « é » peut s’ajouter pour créer « intéressé« . Cette approche permet au modèle de gérer efficacement un vocabulaire immense tout en restant flexible face à des mots rares ou inconnus.
Chaque LLM possède également des tokens spéciaux propres au modèle. Ces tokens structurent la génération du texte et indiquent notamment le début ou la fin d’une séquence. Le token de fin de séquence, ou EOS, joue un rôle particulièrement crucial : il signale au modèle qu’il peut arrêter sa génération. Selon les fournisseurs, ces tokens spéciaux varient considérablement. GPT-4 utilise <|endoftext|>, tandis que Llama 3 emploie <|eot_id|> et SmolLM2 préfère <|im_end|>.
L’attention : le secret de la compréhension contextuelle
Le mécanisme d’attention représente l’innovation majeure des Transformers. Ce système permet au modèle de déterminer quels mots d’une phrase sont les plus importants pour comprendre un autre mot. Prenons la phrase : « L’animal n’a pas traversé la rue parce qu’il était trop fatigué. » Le pronom « il » pose question : fait-il référence à l’animal ou à la rue ?
Le mécanisme d’auto-attention évalue la pertinence de chaque mot par rapport au pronom. Dans cet exemple, le modèle attribuera un score élevé au mot « animal » car c’est la référence logique du pronom « il ». Si la phrase se terminait par « trop large » au lieu de « trop fatigué », l’attention se porterait naturellement sur « rue ».
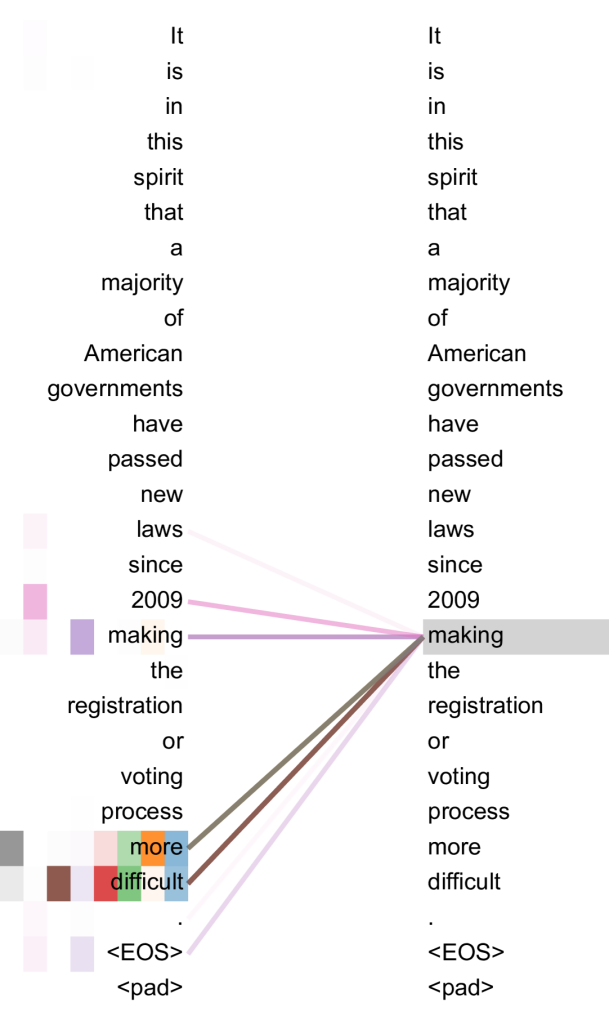
Cette auto-attention fonctionne de manière bidirectionnelle dans les encodeurs, examinant les mots situés avant et après le mot ciblé. Les décodeurs, en revanche, utilisent une attention unidirectionnelle puisqu’ils génèrent le texte token par token et ne peuvent pas « voir » les mots futurs.
Les LLM modernes empilent plusieurs couches d’auto-attention, chacune composée de multiples têtes d’attention. Cette architecture multicouche permet au modèle de développer une compréhension progressivement plus abstraite et nuancée du texte. Les premières couches se concentrent sur la syntaxe de base, tandis que les couches profondes capturent des concepts plus sophistiqués comme le sentiment ou les liens thématiques.
Comment les LLM sont-ils entraînés ?
L’entraînement d’un LLM constitue une entreprise titanesque nécessitant des mois de calcul, des ressources électriques considérables et une expertise pointue en apprentissage automatique. La phase initiale repose sur un apprentissage autosupervisé utilisant la technique des prédictions masquées. Le modèle s’entraîne sur d’énormes corpus de textes où certains tokens sont volontairement cachés, et il doit apprendre à les prédire.
Par exemple, si le système rencontre la phrase masquée « Les oranges sont traditionnellement ___ à la main », il apprendra progressivement que « récoltées » ou « cueillies » constituent des réponses probables. Cette répétition sur des milliards d’exemples permet au modèle de comprendre les structures linguistiques profondes.
Une phase supplémentaire appelée instruction tuning affine ensuite la capacité du modèle à suivre des consignes spécifiques, améliorant ainsi son utilité pratique.
À quoi servent concrètement les LLM ?
Les applications des grands modèles de langage couvrent un spectre impressionnant de cas d’usage. Dans le domaine conversationnel, ils alimentent des chatbots sophistiqués capables de maintenir des dialogues naturels et contextuellement cohérents. Pour la génération de contenu, ils produisent des articles, des résumés, des traductions ou même du code informatique.
Les LLM excellent également dans l’extraction d’informations, la classification de documents ou l’analyse de sentiments. Dans le contexte des agents intelligents, ils servent de cerveau central, interprétant les instructions utilisateurs, maintenant le contexte conversationnel et décidant quels outils activer pour accomplir une tâche.
Avantages et limites des LLM
Les grands modèles de langage présentent des capacités impressionnantes. Ils génèrent du texte clair et adapté à différentes audiences, démontrent une polyvalence remarquable et peuvent gérer des tâches complexes nécessitant une compréhension contextuelle profonde.
Cependant, ces modèles ne sont pas exempts de problèmes. Les hallucinations restent leur talon d’Achille majeur. Ils peuvent produire des informations factuellement incorrectes avec une assurance déconcertante. Leur entraînement et leur utilisation consomment des ressources computationnelles et énergétiques considérables, soulevant des questions environnementales légitimes. Comme tous les systèmes d’apprentissage automatique, ils peuvent également reproduire et amplifier des biais présents dans leurs données d’entraînement.
LLM Open-Source : une démocratisation en marche
Face aux modèles propriétaires comme GPT-5, une tendance forte vers les LLM open-source émerge. Des modèles comme Mistral ou SmolLM d’Hugging Face offrent des alternatives accessibles que les développeurs peuvent adapter à leurs besoins spécifiques. Cette démocratisation permet à davantage d’acteurs de bénéficier de ces technologies avancées sans dépendre exclusivement de quelques grandes entreprises.
Que retenir des LLMs ?
Les grands modèles de langage représentent une avancée technologique majeure qui transforme notre façon d’interagir avec les machines. Leur architecture Transformer, basée sur des mécanismes d’attention sophistiqués, leur permet de comprendre et de générer du langage avec une qualité impressionnante.
Malgré leurs limites actuelles, notamment les hallucinations et leur coût énergétique, ces modèles continuent d’évoluer rapidement. Comprendre leur fonctionnement devient essentiel pour quiconque s’intéresse à l’avenir de l’intelligence artificielle et à ses applications pratiques dans notre quotidien numérique.
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762. https://doi.org/10.48550/arXiv.1706.03762