
Algorithme
Word Embedding : De Word2Vec à FastText
L’ère du traitement automatique du langage a connu des avancées remarquables grâce aux word embeddings. Ces plongements lexicaux permettent aux machines de comprendre et de manipuler le langage humain de manière plus efficace en capturant les relations sémantiques entre les mots. Depuis l’introduction de Word2Vec par Google en 2013, jusqu’à l’émergence de FastText par Facebook en 2016, les word embeddings ont évolué pour offrir des représentations plus précises et nuancées des mots. Cet article explore l’évolution des word embeddings, en mettant l’accent sur Word2Vec et FastText, et examine pourquoi le word embedding est devenu une référence incontournable dans le domaine du traitement de texte.
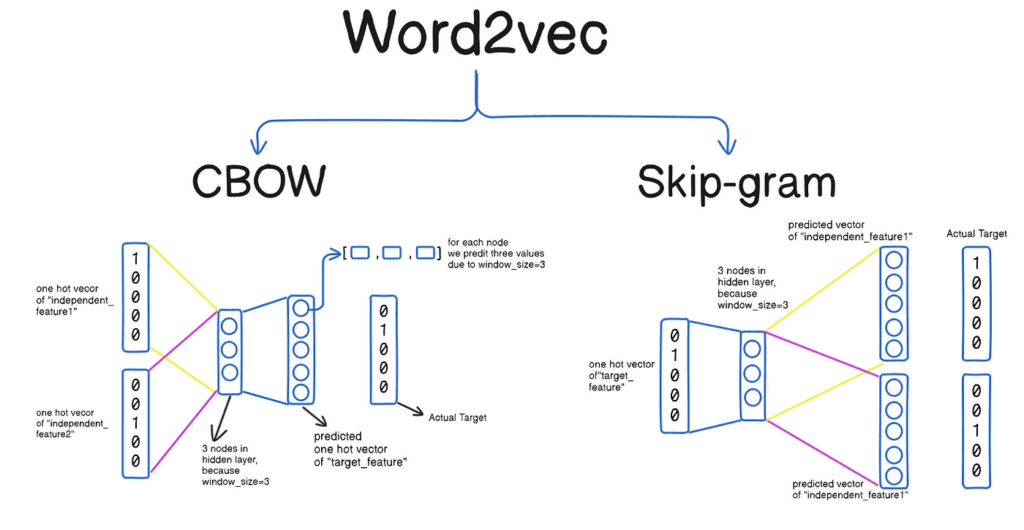
Qu’est-ce que Word2Vec et comment l’utilise-t-on ?
Word2Vec est un modèle de réseaux de neurones développé par une équipe de Google sous la direction de Tomas Mikolov. Il s’agit d’un algorithme permettant de transformer les mots en vecteurs numériques de dimension fixe, capturant ainsi les relations sémantiques entre les mots. Word2Vec fonctionne principalement selon deux architectures : le Continuous Bag of Words (CBOW) et le Skip-gram.
Le modèle CBOW prédit un mot cible à partir de son contexte, c’est-à-dire les mots environnants, tandis que le modèle Skip-gram fait le contraire en utilisant un mot pour prédire son contexte. En apprenant à prédire les mots contextuels, Word2Vec parvient à placer des mots similaires dans un espace vectoriel proche, facilitant ainsi la détection de similarités sémantiques.
L’utilisation de Word2Vec est vaste dans le traitement automatique du langage. Il est couramment employé pour des tâches telles que la classification de texte, la traduction automatique, l’analyse de sentiments, et la détection de similarités entre documents. En fournissant des représentations numériques des mots, Word2Vec permet aux modèles de machine learning de traiter le texte de manière plus efficace et significative.

C’est quoi FastText et quelle est son utilité ?
FastText est une extension de Word2Vec développée par Facebook AI Research (FAIR). Alors que Word2Vec traite chaque mot comme une entité distincte, FastText améliore cette approche en décomposant les mots en sous-mots ou n-grammes. Cette méthode permet de capturer des informations morphologiques et de mieux gérer les mots rares ou inconnus.
Par exemple, le mot « chatting » est décomposé en sous-mots tels que « chat », « hat », « att », etc. Ces n-grammes sont ensuite utilisés pour enrichir la représentation vectorielle du mot complet. Cette approche permet à FastText de mieux comprendre les variations morphologiques des mots et d’améliorer la qualité des plongements lexicaux pour des langues avec une riche morphologie.
L’utilité de FastText réside dans sa capacité à générer des word embeddings plus robustes et précis, notamment pour des applications nécessitant une compréhension fine des variantes des mots. Il est particulièrement utile dans des contextes multilingues et pour les langues avec de nombreuses déclinaisons. FastText est également apprécié pour sa rapidité et son efficacité, ce qui le rend adapté à de grandes quantités de données textuelles.
Quelle est la relation entre FastText et Word2Vec ?
FastText et Word2Vec partagent une base commune en ce sens qu’ils utilisent tous deux des réseaux de neurones pour générer des word embeddings. Cependant, la principale différence réside dans la manière dont ils traitent les mots. Word2Vec considère chaque mot comme une unité distincte, ce qui peut poser des problèmes pour les mots rares ou nouveaux. En revanche, FastText décompose les mots en n-grammes, permettant ainsi une meilleure généralisation et une gestion plus efficace des out-of-vocabulary (OOV).
Cette relation symbiotique signifie que FastText est une amélioration progressive de Word2Vec, visant à résoudre certaines de ses limitations tout en conservant ses points forts. Les deux modèles utilisent des techniques similaires pour capturer les relations sémantiques entre les mots, mais FastText offre une flexibilité accrue grâce à l’incorporation des sous-mots. Cela permet à FastText de fournir des représentations plus riches et plus nuancées, tout en restant fidèle à l’approche initiale de Word2Vec.
En quoi le Word Embedding est une référence dans le traitement de texte ?
Le word embedding est devenu une référence dans le domaine du traitement automatique du langage grâce à sa capacité à transformer le texte en une forme que les machines peuvent traiter efficacement. Les plongements lexicaux permettent de capturer les relations sémantiques et contextuelles entre les mots, ce qui est essentiel pour de nombreuses tâches de NLP (Natural Language Processing).
L’un des principaux avantages du word embedding est sa capacité à réduire la dimensionnalité des données textuelles tout en préservant les informations sémantiques importantes. Cela permet aux modèles de machine learning de traiter le texte plus rapidement et avec une meilleure précision. De plus, les word embeddings facilitent le transfert d’apprentissage, où un modèle pré-entraîné sur un large corpus peut être adapté à des tâches spécifiques avec moins de données.
En outre, les word embeddings comme Word2Vec et FastText ont démontré leur efficacité à capturer des analogies et des relations complexes entre les mots, telles que « roi » est à « reine » ce que « homme » est à « femme ». Cette capacité à comprendre et à manipuler les relations sémantiques est cruciale pour des applications avancées telles que la traduction automatique, la génération de texte, et la recherche d’information.












