Artificial Intelligence
FastVLM of Apple : A Model Vision Language Ultra-Efficient
Apple, often seen as discreet on the public artificial intelligence stage, is making a bold move with FastVLM, a new vision-language model (VLM) designed to understand images with unmatched speed. While most major players are focusing on text-based chatbots, Apple is betting on another frontier: real-time visual analysis, directly on devices. This is not just a technical breakthrough, it’s an open door to new experiences, from smart glasses to accessible assistants.
What is FastVLM and why it is important ?
A vision-language model (VLM) is an AI system capable of understanding both images and text, and answering natural language questions about visual content. For example, you show a street photo to a VLM and ask it: “What is written on this sign?” To function, these models combine a visual encoder (which transforms the image into interpretable data) and a large language model (LLM), responsible for generating the answer.
The problem? The higher the image resolution, the more accurate the model becomes—especially for reading text or recognizing small objects. But processing high-resolution images significantly slows down the system. This is known as the trade-off between accuracy and latency. And this is where FastVLM changes the game.


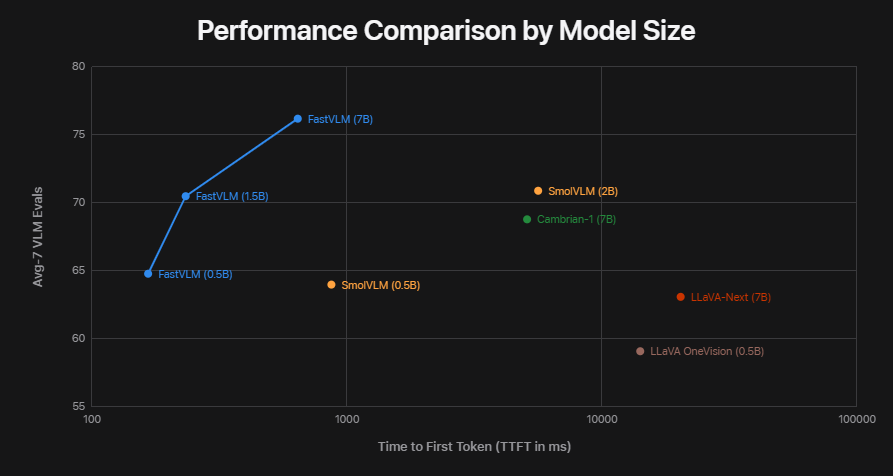
Developed by Apple researchers and presented at the CVPR 2025 conference, FastVLM is designed to deliver high accuracy without sacrificing speed. It achieves performance up to 85 times faster than comparable models like LLaVA-OneVision, while also being smaller and more resource-efficient. It can run in real time, even on an iPhone.

FastViTHD, the secret of the effectiveness of FastVLM
The key to FastVLM’s success lies in its visual encoder, called FastViTHD. Unlike traditional encoders based solely on Transformer-based networks (such as ViTs), FastViTHD adopts a hybrid architecture that combines convolutions and Transformer blocks. This combination drastically reduces the number of visual tokens—the fragments of information extracted from the image—while preserving a rich visual understanding.
Fewer tokens—that’s a double win: :
- The encoder visual works faster.
- The LLM has less data to process upstream, which reduces the time-to-first-token (TTFT), the waiting time until the response begins to appear.

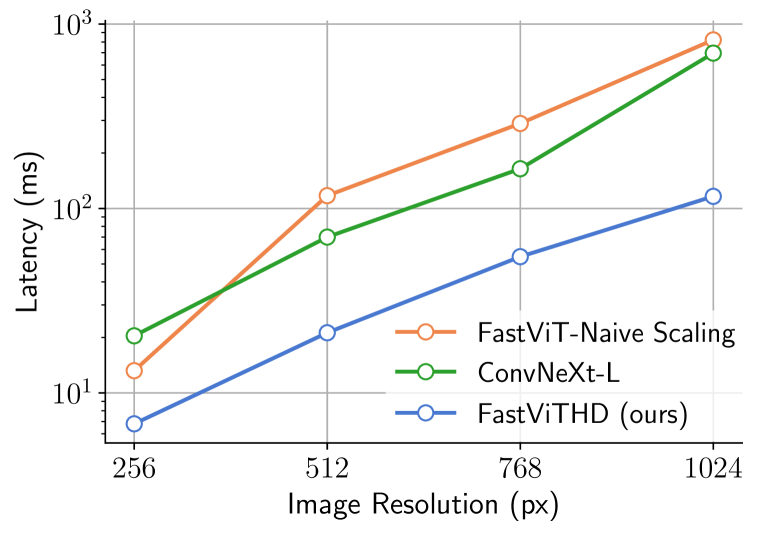
What makes FastVLM even more elegant is that it doesn’t need complex techniques like pruning (token trimming) or merging (token fusion). It achieves its performance simply by adjusting the input resolution. Less complexity, more reliability, a true innovation for production deployment.
Testable everywhere, designed for privacy
One of the most interesting aspects of FastVLM is its availability. Apple has released not only the models and code, but also a demonstration accessible directly in the browser via Hugging Face. You can connect your webcam and watch the model describe in real time what it sees: “A person is wearing a blue t-shirt,” “A cat is sleeping on the couch,” etc. Download FastVLM here.
And unlike many AI models that send your data to remote servers, FastVLM can run entirely locally, without an internet connection. This is a major step forward for privacy. Your images never leave your device. This approach fits perfectly with Apple’s philosophy, but it also opens the door to critical applications, assistants for the visually impaired, interface recognition in sensitive environments, or navigation in offline areas.
To specific applications and embedded
So, what is FastVLM for? Of course, it can generate automatic captions for videos or translate signs in real time while traveling. But the horizon is much broader. This technology is a key pillar for Apple’s future wearable devices, such as smart glasses. Imagine lenses that can continuously tell you what’s happening around you, who is greeting you, what a menu says, or whether you’re in the right line.
FastVLM also highlights a clear trend in AI: on-device optimization. Instead of sending everything to the cloud, the industry is moving toward smaller, faster models that can run on a smartphone, watch, or headset. Apple, with FastVLM and its framework MLX (specially optimized for chips Apple Silicon), place the bar very high.
Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel & Hadi Pouransari (2025). FastVLM: Efficient vision encoding for vision-language models (arXiv:2412.13303v2). arXiv
