Research
DS-STAR, a versatile agent : Google for data science
Generative artificial intelligence has already revolutionized the world of software development. Assistants like GitHub Copilot or traditional large language models excel at writing isolated functions or fixing syntax bugs. However, data science is a far more complex beast for AI to tame. It isn’t just about generating code that compiles, it demands deep contextual understanding, the ability to clean “messy” data, to formulate hypotheses, and, above all, to iterate in the face of unexpected results. It is precisely to bridge this gap that Google has unveiled DS-STAR, a new agent designed to master the entire data science lifecycle.
This research project marks a pivotal milestone. Whereas previous tools often acted as passive assistants, DS-STAR positions itself as an autonomous agent capable of reasoning, planning, and correcting its own mistakes to solve complex, Kaggle-style problems. Dive into the heart of this innovation, which promises to redefine how we interact with data.
A versatile agentic system, DS-STAR
To understand the innovation behind DS-STAR, one must first recognize the limitations of current large language models (LLMs) in data science. When asked to analyze a complex dataset, a standard LLM often “hallucinates” column names, uses incompatible libraries, or proposes overly simplistic modeling without genuinely exploring the data first. It behaves like a very fast intern who never double-checks their work.
DS-STAR represents a paradigm shift. It is a versatile agentic system that structures its approach. Before writing even a single line of Python code, the agent takes time to understand the user’s request and the data format. Rather than merely translating text into code, it acts as an analytical partner capable of managing long-horizon tasks, from initial exploratory data analysis (EDA) all the way to final predictive modeling.


This versatility is crucial. In real-world projects, a data scientist spends 80% of their time preparing data and performing feature engineering. DS-STAR is specifically trained to excel at these tedious yet essential tasks, delivering a level of robustness that general-purpose chatbots have never previously achieved.
The secret to performance : Planning, coding, check
The true magic of DS-STAR lies in its internal architecture, which mirrors the cognitive process of a human expert. Instead of attempting to solve everything in a single inference, a strategy that often fails for complex problems, Google has divided the agent’s intelligence into multiple specialized roles that collaborate. According to the research, this system operates through an iterative loop of planning and verification.

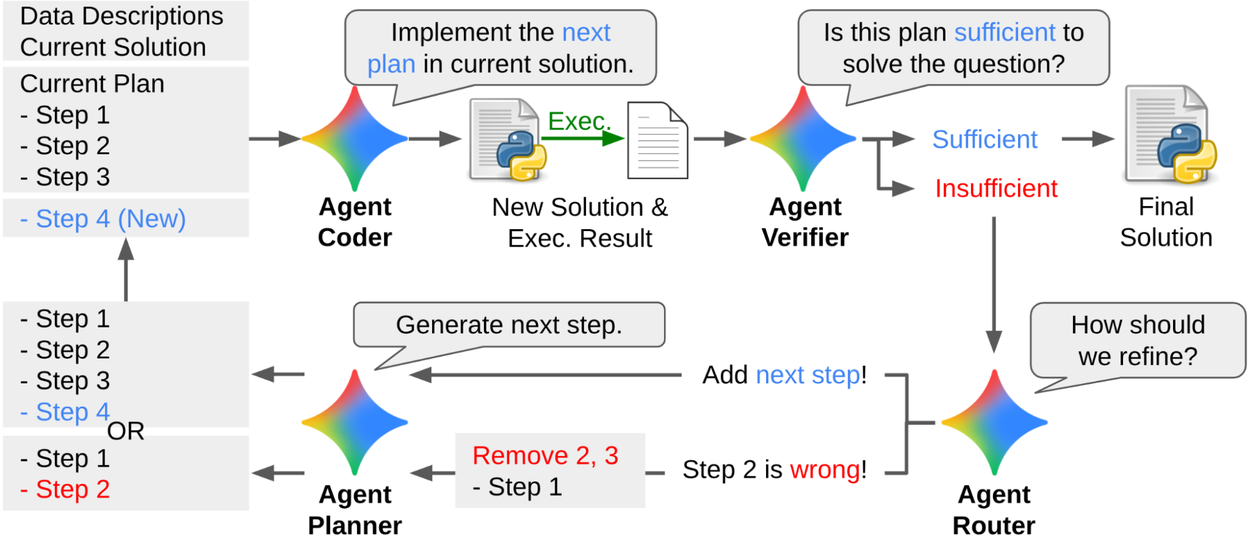
Imagine a virtual team composed of four interdependent specialists, designed to mirror the rigor of an expert analyst using tools like Google Colab. The process begins with the Planner agent, whose role is to decompose a vague objective (e.g., “Improve the accuracy of this sales forecasting model”) into logical, executable steps. It does not write code; instead, it designs a structured strategy, leveraging intermediate results to refine its reasoning before proceeding to each subsequent step.
The Coder agent then takes over, transforming the plan into an executable script while ensuring the code is functional and aligned with the defined objectives.
Next, the Verifier agent, an LLM-based judge, evaluates objectively whether the generated code truly solves the original problem. Unlike a simple performance metric (e.g., an accuracy score), it analyzes intermediate outputs to determine whether the underlying strategic plan is satisfactory or requires adjustments.
If the Verifier deems the plan insufficient, the Router agent intervenes: it identifies which steps must be modified, removed, or added, then redirects the cycle back to the Planner for a new iteration. This iterative self-correction mechanism (or grounding) mirrors the workflow of a human expert progressively refining their solution by testing each step.
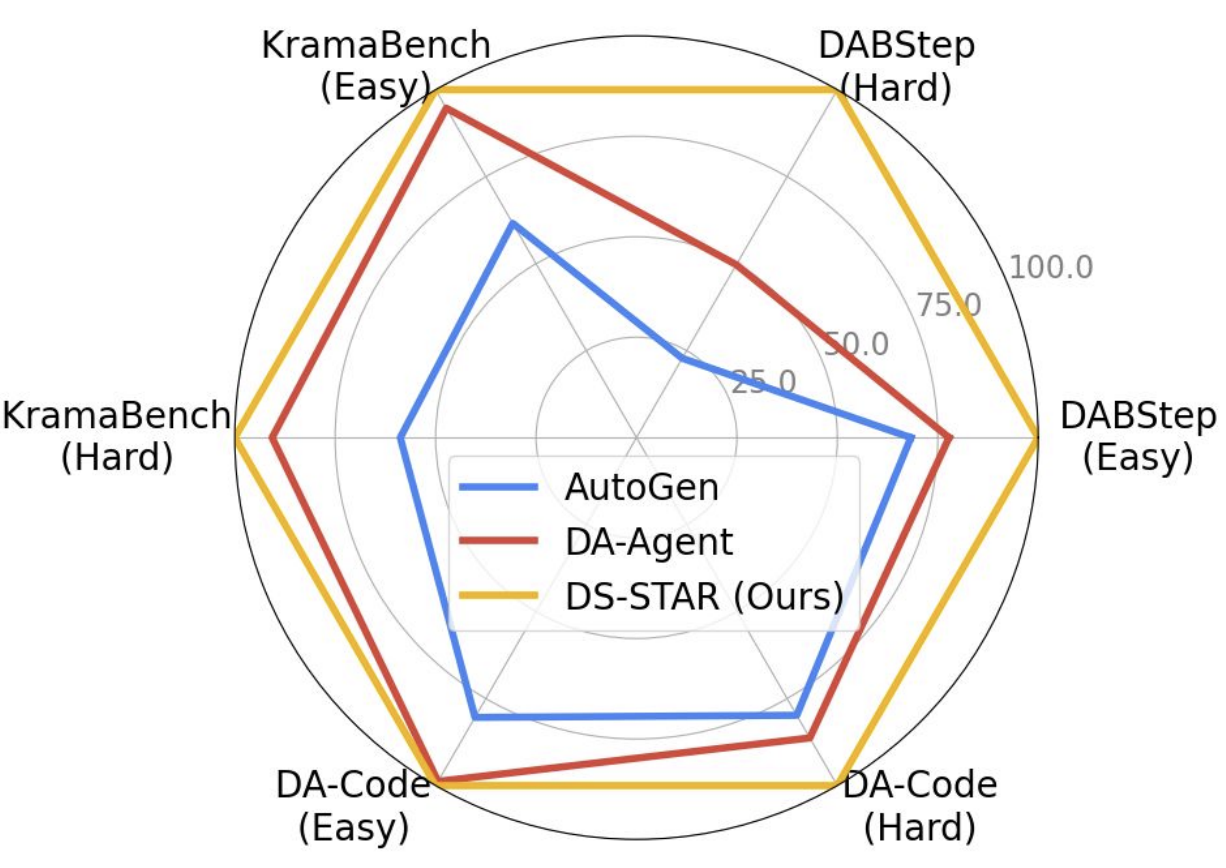
This loop (plan → code → verify → route) repeats up to 10 times maximum, balancing thoroughness and efficiency. At the end of the process, DS-STAR delivers a final solution validated through critical iterative refinements, enabling it to achieve exceptional performance on benchmarks such as DABench, KramaBench, and DA-Code, significantly outperforming competing approaches like DA-Agent and AutoGen

The data science assisted by AI
The emergence of tools like DS-STAR does not signal the end of the data scientist profession, but rather its evolution toward a strategic supervisory role. By automating the “grunt work”, data cleaning, model unit testing, basic hyperparameter selection, this agent frees up time for higher-level, business-oriented thinking. For experts, this translates into a massive productivity gain. For web developers or tech-savvy novices, it opens a gateway to advanced data analysis, making techniques previously requiring years of experience suddenly accessible.
However, this power also brings new responsibilities. The agent’s ability to make autonomous decisions about data processing raises important questions about verifiability. Even though DS-STAR is designed to be transparent in its planning and execution, human users must maintain a critical eye on the methodological choices made by the AI.
With DS-STAR, Google is making a bold move, delivering far more than just a code assistant. By embedding planning and verification at the core of the data science workflow, they offer a glimpse into the future of autonomous agents: systems capable of persistence and reasoning in the face of the uncertainty inherent in real-world data. We are entering an era where the data science agent becomes a full-fledged collaborator, fundamentally transforming how we turn raw data into actionable insights.
[1] Nam, J., Yoon, J., Chen, J., & Pfister, T. (2025). DS-STAR: Data Science Officer via Iterative Planning and Verification. arXiv. https://doi.org/10.48550/arXiv.2509.21825
[2] DS-STAR: A state-of-the-art versatile data science officer