








News
Google Gemini Embedding 2 for Multimodal Semantic Search
Google launches Gemini Embedding 2: record-breaking performance on benchmarks, support for 5 modalities, and native integration into a single embedding space.
In the constantly evolving ecosystem of artificial intelligence, Google has just taken a major step with the launch of Gemini Embedding 2, its first natively multimodal embedding model. This innovation redefines how machines understand and organize information across different media types. For developers and companies leveraging AI, this advancement opens up unprecedented opportunities in semantic search and data analysis.
Announcing Gemini Embedding 2 ✨ the first fully multimodal embedding model built on the Gemini architecture. Now available in preview via the Gemini API and Vertex AI.
— Google for Developers (@googledevs) March 10, 2026
The new model provides semantic understanding across 100+ languages — and support for modalities across text,… pic.twitter.com/gAlVQ5fPaV
Understanding embeddings and their role in modern AI
Before exploring the specificities of Gemini Embedding 2, it is worth clarifying the concept of embedding. In the field of machine learning, an embedding is a numerical representation that transforms complex data such as text, images, or sound into mathematical vectors. These vectors capture the semantic meaning of the content and allow algorithms to compare, classify, and search for information efficiently.
Traditionally, embedding models focused on a single modality. One model processed only text, another only images. This fragmented approach required complex pipelines to manage multiple data types simultaneously. Gemini Embedding 2 breaks with this limitation by offering a unified architecture capable of simultaneously processing text, images, videos, audio, and PDF documents within a common embedding space. This convergence significantly simplifies technical architectures while improving the precision of contextual understanding.
Major new features of Gemini Embedding 2
Version 2 of Gemini Embedding introduces several remarkable innovations. Built on Google’s Gemini architecture, it inherits the cutting-edge multimodal understanding capabilities developed by DeepMind. The model now supports five distinct modalities with impressive technical specifications: up to 8192 tokens for text, 6 images per query in PNG and JPEG formats, 120 seconds of video in MP4 or MOV, audio processed natively without intermediate transcription, and PDF documents up to 6 pages.
The most significant innovation lies in the model’s ability to process interleaved inputs. Specifically, Gemini Embedding 2 can simultaneously analyze an image accompanied by a textual description in a single query, thus capturing complex relationships between different media types. This approach better reflects how humans perceive information, where text and visuals mutually enrich each other.
The model also incorporates the Matryoshka Representation Learning technique, which allows for dynamically adjusting output dimensions. With 3072 dimensions by default, developers can reduce this size to 1536 or 768 dimensions according to their needs, thereby optimizing the balance between performance and storage costs.
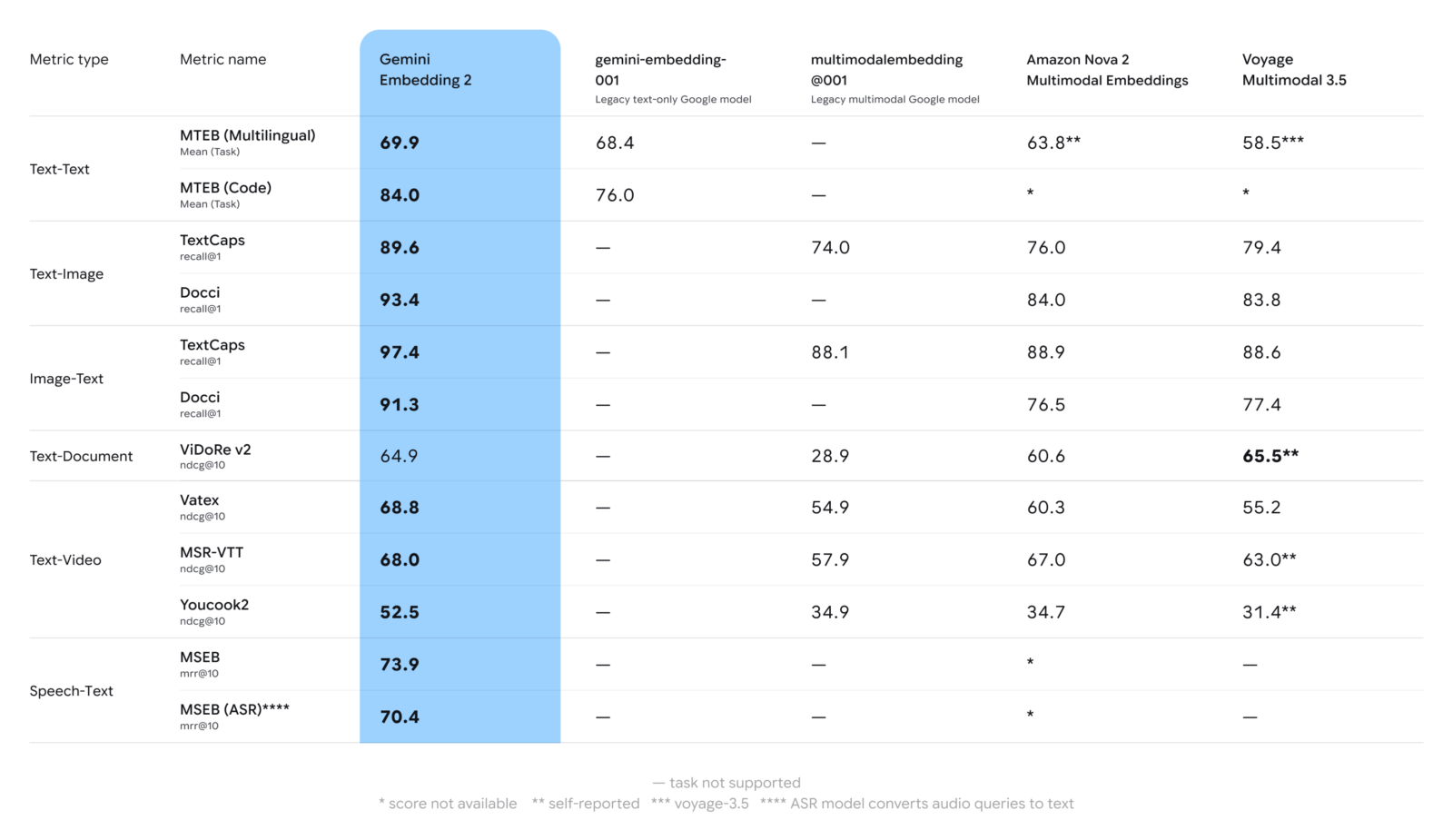
Record performance on benchmarks
Google states that Gemini Embedding 2 sets a new performance standard in the multimodal domain. Published benchmarks show that the model outperforms competing solutions on text search, image analysis, and video understanding tasks. This measurable improvement is not a mere marginal gain but represents a qualitative leap in the precision of semantic search.
The model’s audio capabilities deserve special attention. Unlike traditional approaches that require prior textual transcription, Gemini Embedding 2 processes audio data directly, thus preserving tonal and contextual nuances often lost during text conversion. This feature opens up promising applications in multimedia content analysis, recommendation systems, and automatic classification of audio-visual libraries.
Practical Implementation of Gemini Embedding 2
For developers wishing to integrate this technology, Google offers two main access points: the Gemini API and Vertex AI. The public preview phase already allows for experimentation with the model and building prototypes. Interactive notebooks are available on Colab to facilitate getting started, while integration with popular frameworks like LangChain, LlamaIndex, Haystack, or Weaviate simplifies adoption in existing projects.
Practical use cases cover a wide spectrum. Retrieval-augmented generation particularly benefits from multimodality, allowing language model responses to be enriched with relevant visual contexts. Semantic search engines can now process complex queries mixing several media types, while sentiment analysis systems gain precision by combining text with visual or audio elements.
Towards Truly Multimodal AI
Gemini Embedding 2 marks a significant step in the evolution towards AI systems capable of understanding the world in all its multimodal richness. By unifying text, image, video, audio, and documents into a single semantic space, Google offers developers a powerful tool to build smarter and contextually aware applications. This technical convergence simplifies architectures while opening new creative possibilities to leverage the diversity of data that surrounds us.
[1] Gemini Embedding 2: Our first natively multimodal embedding model









