Artificial Intelligence
Large Language Models (LLM): Understanding these giants of artificial intelligence
A Large Language Model is an AI model specialized in understanding and generating human language.
Large language models have revolutionized the technological landscape in recent years. From ChatGPT to Gemini, these systems capable of understanding and generating text like a human intrigue as much as they fascinate. But behind this apparent magic lies a precise architecture and rigorous scientific principles. Let’s explore together what truly lies behind an LLM.
What exactly is an LLM?
A Large Language Model represents a particular category of artificial intelligence model specialized in understanding and generating human language. These models are trained on phenomenal amounts of textual data, allowing them to learn the structures, patterns, and even subtle nuances of natural language.
The fundamental characteristic of an LLM lies in its colossal size. These models generally consist of several billions of parameters, sometimes even hundreds of billions. An LLM like Llama 2 can operate with a vocabulary of approximately 32,000 tokens. A token is not exactly a word, but rather a more flexible unit of information that can represent a complete word, a part of a word, or even a single character.
The operating principle of LLMs remains surprisingly simple in concept. Their primary goal is to predict the next token in a sequence, based on all preceding tokens. This successive prediction, repeated thousands of times, allows for the generation of coherent and contextually relevant texts.
The Transformer Architecture, the Heart of LLMs
Almost all modern LLMs are based on an architecture called Transformer, introduced by Google with its BERT model in 2018. This architecture revolutionized natural language processing thanks to its particularly effective attention mechanism.

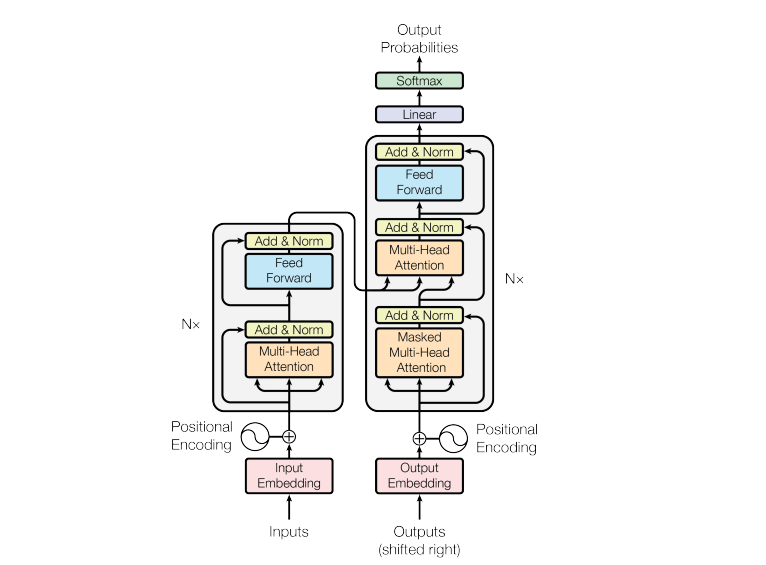
A complete Transformer consists of two main elements. The encoder converts the input text into a dense intermediate representation, often called an embedding. This representation captures the deep meaning of the text in a format that the machine can manipulate. The decoder then takes this intermediate representation to generate useful output text, token by token.
There are three major families of Transformer-based architectures. Models based solely on the encoder, such as Google’s BERT, excel in tasks like text classification, semantic search, and named entity recognition. Decoder-based models, like Meta’s Llama family, focus on generating new tokens and represent the most common category of modern LLMs. Finally, sequence-to-sequence models combine encoder and decoder for tasks like translation.
Among the most well-known LLMs on the market are OpenAI’s GPT-4, Meta’s Llama, Google’s Gemma, and Mistral. Each has its specificities, but all share this fundamental Transformer-based architecture.
Tokens, the Alphabet of Machines
To understand how an LLM works, one must grasp the concept of a token. Contrary to what one might think, language models do not work directly with whole words. For efficiency reasons, they break down text into smaller units called tokens.


This tokenization often works at the sub-word level. For example, the tokens “interest” and “ing” can combine to form “interesting“, or “ed” can be added to create “interested“. This approach allows the model to efficiently manage an immense vocabulary while remaining flexible in the face of rare or unknown words.
Each LLM also has special model-specific tokens. These tokens structure text generation and notably indicate the beginning or end of a sequence. The end-of-sequence token, or EOS, plays a particularly crucial role: it signals to the model that it can stop its generation. Depending on the providers, these special tokens vary considerably. GPT-4 uses <|endoftext|>, while Llama 3 employs <|eot_id|> and SmolLM2 prefers <|im_end|>.
Attention: The Secret to Contextual Understanding
The attention mechanism represents the major innovation of Transformers. This system allows the model to determine which words in a sentence are most important for understanding another word. Let’s take the sentence: “The animal did not cross the street because it was too tired.” The pronoun “it” raises a question: does it refer to the animal or the street?
The self-attention mechanism evaluates the relevance of each word relative to the pronoun. In this example, the model will assign a high score to the word “animal” because it is the logical reference for the pronoun “it”. If the sentence ended with “too wide” instead of “too tired”, the attention would naturally fall on “street”.

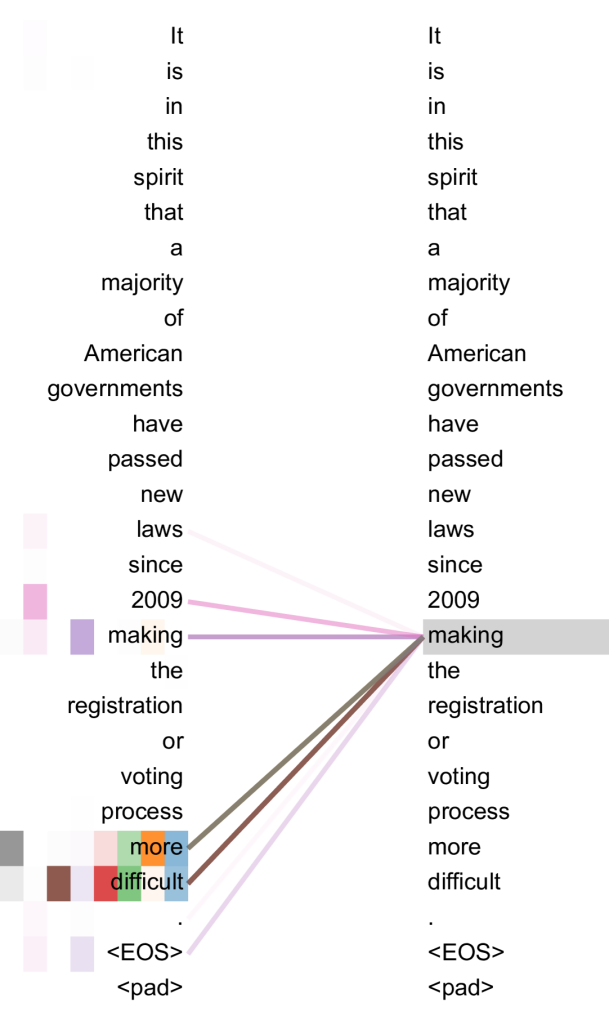
This self-attention works bidirectionally in encoders, examining words located before and after the target word. Decoders, on the other hand, use unidirectional attention since they generate text token by token and cannot “see” future words.
Modern LLMs stack multiple layers of self-attention, each composed of multiple attention heads. This multilayer architecture allows the model to develop a progressively more abstract and nuanced understanding of the text. The first layers focus on basic syntax, while the deep layers capture more sophisticated concepts like sentiment or thematic links.
How are LLMs trained?
Training an LLM is a colossal undertaking requiring months of computation, considerable electrical resources, and cutting-edge expertise in machine learning. The initial phase relies on self-supervised learning using the masked prediction technique. The model trains on enormous text corpora where certain tokens are deliberately hidden, and it must learn to predict them.
For example, if the system encounters the masked sentence “Oranges are traditionally ___ by hand”, it will gradually learn that “harvested” or “picked” are probable answers. This repetition over billions of examples allows the model to understand deep linguistic structures.
An additional phase called instruction tuning then refines the model’s ability to follow specific instructions, thereby improving its practical utility.
What are LLMs concretely used for?
The applications of large language models cover an impressive spectrum of use cases. In the conversational domain, they power sophisticated chatbots capable of maintaining natural and contextually coherent dialogues. For content generation, they produce articles, summaries, translations, or even computer code.
LLMs also excel in information extraction, document classification, or sentiment analysis. In the context of intelligent agents, they serve as a central brain, interpreting user instructions, maintaining conversational context, and deciding which tools to activate to accomplish a task.
Advantages and Limitations of LLMs
Large language models exhibit impressive capabilities. They generate clear text adapted to different audiences, demonstrate remarkable versatility, and can handle complex tasks requiring deep contextual understanding.
However, these models are not without problems. Hallucinations remain their major Achilles’ heel. They can produce factually incorrect information with disconcerting confidence. Their training and use consume considerable computational and energy resources, raising legitimate environmental concerns. Like all machine learning systems, they can also reproduce and amplify biases present in their training data.
Open-Source LLMs: A Democratization Underway
Facing proprietary models like GPT-5, a strong trend towards open-source LLMs is emerging. Models like Mistral or Hugging Face’s SmolLM offer accessible alternatives that developers can adapt to their specific needs. This democratization allows more actors to benefit from these advanced technologies without exclusively depending on a few large companies.

What to remember about LLMs?
Large language models represent a major technological advancement that is transforming how we interact with machines. Their Transformer architecture, based on sophisticated attention mechanisms, allows them to understand and generate language with impressive quality.
Despite their current limitations, notably hallucinations and their energy cost, these models continue to evolve rapidly. Understanding their operation becomes essential for anyone interested in the future of artificial intelligence and its practical applications in our digital daily lives.
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762. https://doi.org/10.48550/arXiv.1706.03762