Artificial Intelligence
FineVision : The dataset multimodal HuggingFace
Hugging Face continues to shape the future of artificial intelligence with a new major contribution, FineVision, a dataset of multimodal on an unprecedented scale. Composed of 24 million samples, this data set aims to become the reference for the training of the next models of vision language (VLM). Publicly available, FineVision multimodal mark a turning point in the quality, the diversity and rigor of construction of the data used for AI.
A dataset of multimodal thought for the finesse visual
What distinguishes FineVision of its predecessors, it is ambition in terms of volume and quality. For the build, the team HuggingFaceM4 was attended by more than 200 public datasets, combining and 17 million images, 89 million pairs question-and-answer, and not less than 10 billion tokens of response. In total, 5 terabytes of data, high-quality, which have been assembled.
But the feat is not only in the quantity. Each sample has been subject to a rigorous treatment, standardization of formats, removal of duplicates and low-quality data, and converting it to a systematic in pairs, question-answer, even for datasets that are initially non-dialogical. This uniformity is crucial to enable a learning fluid and coherent models.


This dataset FineVision is therefore a powerful tool to lead to models that are capable of responding to complex questions about an image, generate descriptions ultra-precise, or to detect anomalies in industrial settings or on medical.
Areas that were under-represented, man-machine interaction
FineVision is not limited to the images and descriptions of classic. team has identified a gap in the data-oriented user interface (GUI), essential for the cause of models able to interact with screens (browsers, applications, etc). To fill this void, a new set dedicated to the shares GUI has been created. It is based on datasets existing, including the specific formats have been standardized to a space of action generalized, allowing models to understand commands such as ‘ click on the button Play ‘ or ‘ do scroll to the bottom ‘.
This inclusion strategic shows that FineVision multimodal is thought not only to the understanding of images, but also to theaction in digital environments, a key capability for the wizards AI in the future.
Better models with FineVision
The ultimate goal of this data set FineVision ? Allow the open source community to develop models multimodal at the leading edge. And the results are revealing, in-depth testing (ablations) to show that the models trained on FineVision surpass all of the other on 11 benchmarks used, either in visual understanding, reasoning or text generation.

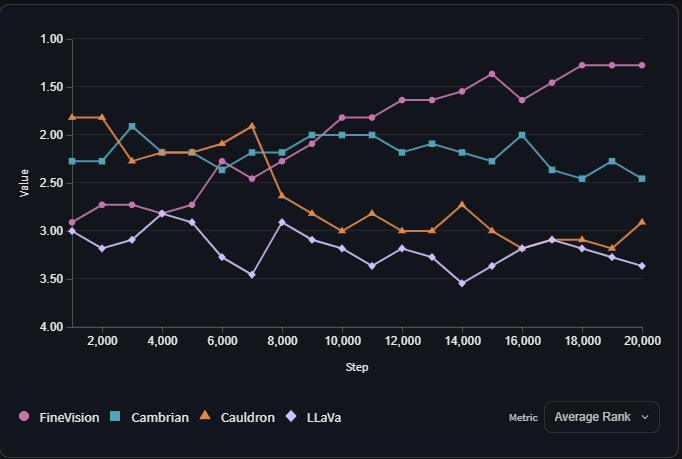
This superiority is explained by the diversity and the quality of the dataset multimodal, but also by its design transparent and traceable. Unlike some datasets opaques used by the big private players, FineVision is fully open, inspectable, and designed for the research reproducible.
An advanced key for the AI open and multimodal
The dataset FineVision is not only a technical tool, it is a manifesto for an RN open, rigorous, and accessible. By pooling, cleaning, and evaluating massive amounts of data visio-language, Hugging Face offers the community a powerful lever to innovate without having to rely on the giants of the tech.
With this data set FineVision, the bar is high now, the data quality is as important as the models. And if the future of AI multimodal relies on the ability to see, understand and act, FineVision multimodal is without doubt one of the bases the stronger to this day.
[1] Wiedmann, L., Zohar, O., Marafioti, A., Mahla, A., Frere, T., & von Werra, L. (2025). FineVision: Open Data Is All You Need. Hugging Face.
Zengdamo
10 September 2025 at 2h35
What stands out to me about FineVision is not just the massive scale, but the effort to balance quality with diversity across under-represented areas. It’ll be interesting to see how this dataset impacts bias reduction in future vision-language models, since cleaner and more representative training data often makes a bigger difference than model tweaks alone.