Revue de Recherche
Qwen3 ASR : Reconnaissance vocale multilingue open source
Qwen3 ASR, une nouvelle famille de modèles de reconnaissance vocale automatique
L’équipe Qwen d’Alibaba Cloud a frappé fort fin janvier 2026 en dévoilant Qwen3 ASR, une nouvelle famille de modèles de reconnaissance vocale automatique qui bouleverse le paysage de l’intelligence artificielle audio. Disponible à partir de fin janvier en open source sous licence Apache 2.0, cette solution promet de rivaliser avec les API commerciales les plus performantes tout en supportant 52 langues et dialectes. Une annonce qui consolide la position de Qwen comme famille de modèles d’IA open source la plus téléchargée au monde, avec plus de 700 millions de téléchargements cumulés sur Hugging Face.
Type de modèle Qwen3 ASR disponible
Qwen3 ASR se décline en trois variantes distinctes, chacune répondant à des cas d’usage spécifiques. Le modèle phare, Qwen3 ASR 1.7B, embarque 1,7 milliard de paramètres et vise les performances maximales. Pour les applications nécessitant un équilibre entre précision et efficacité, Qwen3 ASR 0.6B offre une alternative plus légère avec 600 millions de paramètres. Cette version compacte affiche des performances remarquables avec une latence moyenne de seulement 92 millisecondes et une capacité impressionnante de transcrire 2000 secondes d’audio en une seule seconde avec une concurrence de 128 requêtes simultanées.

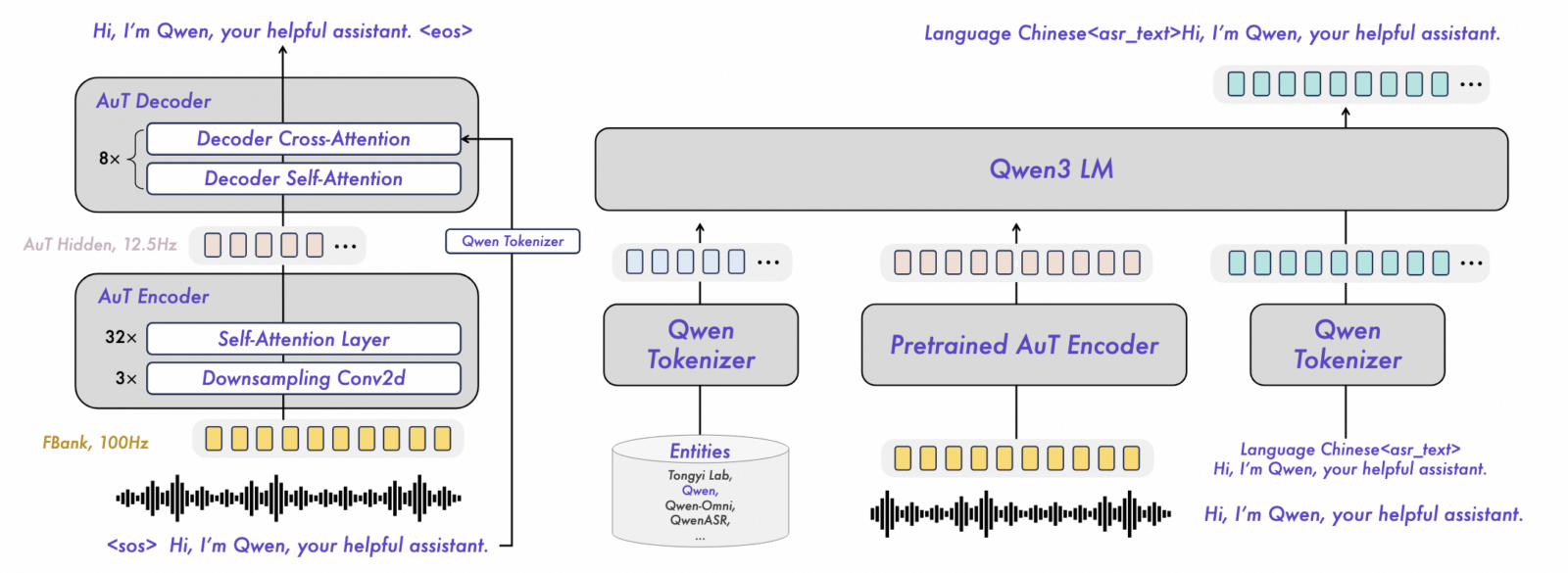
Cette conception intègre une fenêtre d’attention dynamique ajustable entre 1 et 8 secondes, permettant à Qwen3 ASR de fonctionner aussi bien en mode streaming avec de courts segments qu’en mode hors ligne pour de longues requêtes. Le modèle phare Qwen3 ASR 1.7B combine le modèle de langage Qwen3-1.7B avec un encodeur AuT de 300 millions de paramètres et une dimension cachée de 1024, reliés par un module de projection. [1]
La famille Qwen3 se distingue également par l’ajout de Qwen3 ForcedAligner 0.6B, un modèle innovant dédié à l’alignement forcé. Cette solution non autorégressive permet de prédire précisément les horodatages au niveau des mots ou des caractères pour 11 langues, ouvrant la voie à des applications de sous-titrage et de synchronisation audio-texte particulièrement sophistiquées.
Performances Qwen3 ASR défient Whisper de OpenAI
Les tests révèlent que Qwen3 ASR 1.7B atteint l’état de l’art parmi les modèles open source et se montre compétitif face aux API commerciales les plus puissantes. Le modèle surpasse notamment Whisper large v3 d’OpenAI, largement considéré comme une référence du domaine, sur plusieurs benchmarks de référence. Cette prouesse s’explique par l’architecture sophistiquée de Qwen3, qui s’appuie sur le modèle fondamental Qwen3 Omni et bénéficie d’un encodeur audio AuT entraîné sur des volumes massifs de données vocales.

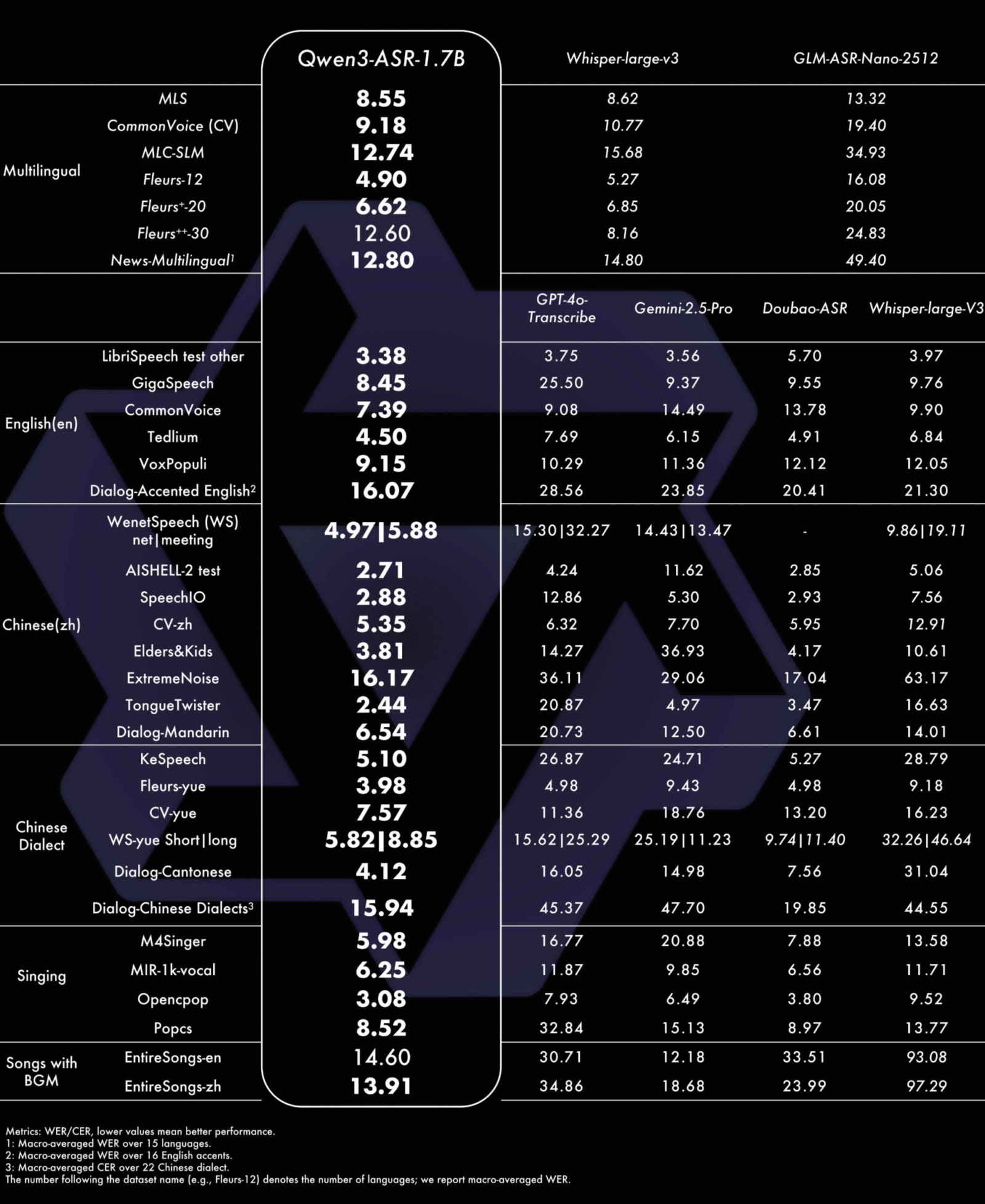
L’un des atouts majeurs de Qwen3 ASR réside dans sa robustesse exceptionnelle face aux environnements acoustiques complexes. Le modèle maintient une qualité de reconnaissance élevée même en présence de bruit ambiant important, de musique de fond ou de dialectes régionaux. Cette capacité à gérer des situations réelles difficiles le distingue des solutions concurrentes qui excellent souvent uniquement sur des enregistrements audio propres en laboratoire.
Une couverture linguistique impressionnante
Avec le support de 30 langues et 22 dialectes chinois, Qwen3 ASR affiche une ambition résolument mondiale. Le modèle gère également les accents anglais de multiples régions géographiques, garantissant une reconnaissance fiable quelle que soit la provenance de l’orateur. Cette polyvalence linguistique s’accompagne d’une fonctionnalité d’identification automatique de la langue, permettant au système de détecter et transcrire l’audio sans nécessiter de configuration préalable.

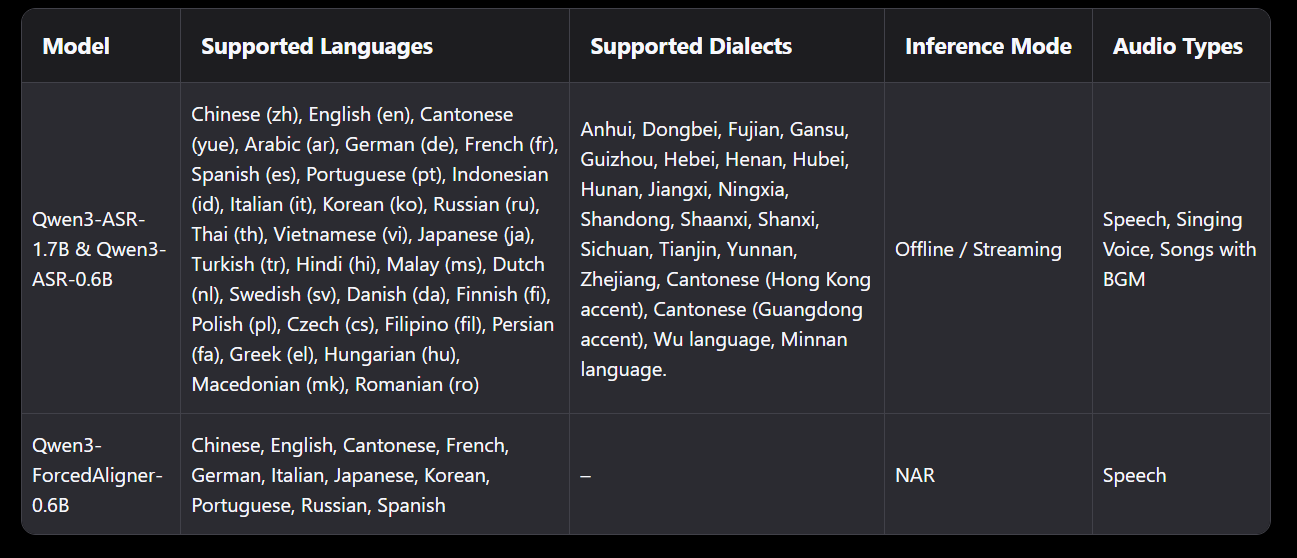
L’approche tout-en-un adoptée par Qwen simplifie considérablement le déploiement pour les développeurs. Plus besoin de jongler entre plusieurs modèles spécialisés ou de construire des pipelines complexes : un seul modèle Qwen3 ASR suffit pour gérer l’identification linguistique, la transcription multilingue et même la détection de segments non vocaux.
Un modèle open source qui ouvre de nouvelles perspectives
La publication de Qwen ASR s’inscrit dans l’offensive d’Alibaba Cloud sur le terrain de l’intelligence artificielle open source. Avec près de 400 modèles Qwen rendus accessibles et plus de 180 000 versions dérivées créées par la communauté, l’entreprise rivalise directement avec Meta et ses modèles Llama.
L’ouverture sous licence Apache 2.0 autorise une utilisation commerciale sans restriction, facilitant l’adoption par les entreprises désireuses d’intégrer des capacités de reconnaissance vocale avancées sans dépendre de services propriétaires coûteux. Les applications couvrent un spectre large : sous-titrage automatique, assistants vocaux, transcription de réunions, centres d’appels et accessibilité pour les personnes malentendantes.
[1]Shi, X., Wang, X., Guo, Z., Wang, Y., Zhang, P., Zhang, X., Guo, Z., Hao, H., Xi, Y., Yang, B., Xu, J., Zhou, J., & Lin, J. (2026). Qwen3-ASR Technical Report. arXiv preprint arXiv:2601.21337v2. https://doi.org/10.48550/arXiv.2601.21337
[2] Qwen3-ASR & Qwen3-ForcedAligner is Now Open Sourced: Robust, Streaming and Multilingual!
Télécharger les modèles de la famille QwenASR sur HugginFace