Revue de Recherche
DS-STAR, un agent polyvalent : Google pour la data science
L’intelligence artificielle générative a déjà bouleversé le monde du développement logiciel. Des assistants comme GitHub Copilot ou les modèles de langage classiques excellent pour écrire des fonctions isolées ou corriger des bugs de syntaxe. Cependant, la science des données (Data Science) est une bête bien plus complexe à dompter pour une IA. Elle ne se résume pas à produire du code qui compile ; elle exige une compréhension profonde du contexte, une capacité à nettoyer des données « sales », à formuler des hypothèses et, surtout, à itérer face à des résultats imprévus. C’est précisément pour combler ce fossé que Google a dévoilé DS-STAR, un nouvel agent conçu pour maîtriser l’ensemble du cycle de vie de la science des données.
Ce projet de recherche marque une étape charnière. Là où les outils précédents se contentaient souvent de jouer les assistants passifs, DS-STAR se positionne comme un agent autonome capable de raisonner, de planifier et de corriger ses propres erreurs pour résoudre des problèmes complexes de type Kaggle. Plongée au cœur de cette innovation qui promet de redéfinir notre interaction avec les données.
Système agentique polyvalent, DS-STAR
Pour comprendre l’innovation derrière DS-STAR, il faut d’abord saisir les limites des modèles de langage actuels (LLM) en science des données. Lorsqu’on demande à un LLM classique d’analyser un jeu de données complexe, il a tendance à « halluciner » des noms de colonnes, à utiliser des bibliothèques incompatibles ou à proposer une modélisation simpliste sans avoir véritablement exploré les données. Il agit comme un stagiaire très rapide, mais qui ne vérifierait pas son travail.
DS-STAR change de paradigme. Il s’agit d’un système agentique polyvalent qui structure son approche. Avant même d’écrire la première ligne de Python, l’agent prend le temps de comprendre la demande utilisateur et le format des données. Il n’est pas simplement un traducteur de texte vers code, plutôt partenaire analytique capable de gérer des tâches à long terme, de l’exploration initiale des données (EDA) jusqu’à la modélisation prédictive finale.


Cette polyvalence est cruciale. Dans un projet réel, un data scientist passe 80 % de son temps à préparer les données et à faire de l’ingénierie des fonctionnalités (feature engineering). DS-STAR est spécifiquement entraîné pour exceller dans ces tâches ingrates, mais essentielles, apportant une robustesse que les simples chatbots généralistes n’ont jamais réussi à atteindre jusqu’ici.
Le secret de la performance : Planifier, coder, vérifier
La véritable magie de DS-STAR réside dans son architecture interne, qui mime le processus cognitif d’un expert humain. Plutôt que d’essayer de tout résoudre en une seule inférence (ce qui échoue souvent pour des problèmes complexes), Google a divisé l’intelligence de l’agent en plusieurs rôles spécialisés qui collaborent. D’après les travaux de recherche, ce système s’articule autour d’une boucle itérative de planification et de vérification.

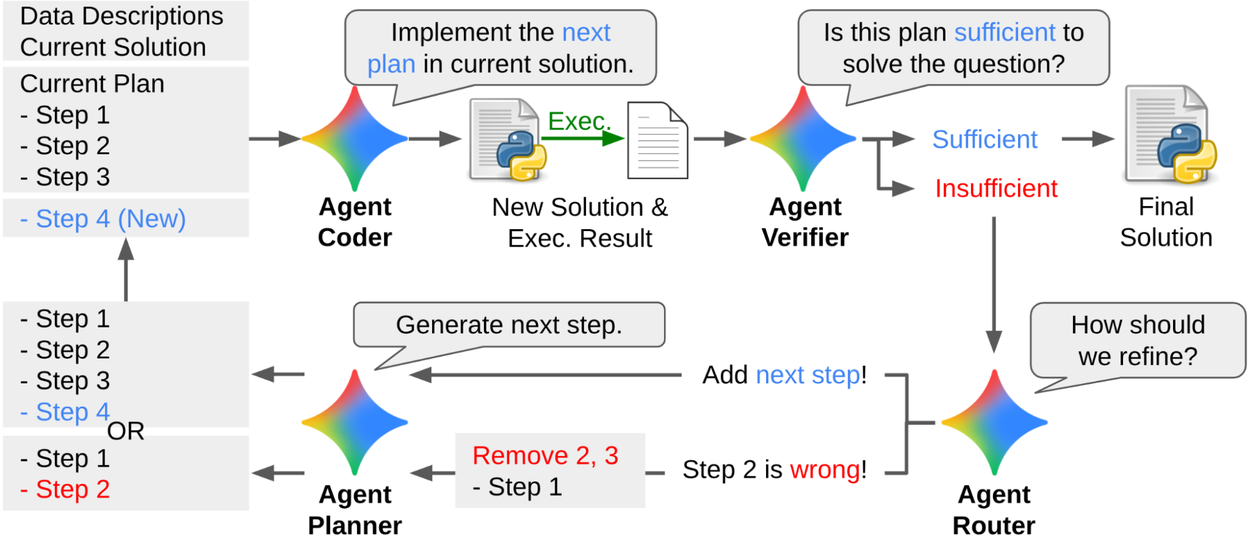
Imaginez une équipe virtuelle composée de quatre spécialistes interdépendants, conçue pour imiter la rigueur d’un analyste expert utilisant des outils comme Google Colab. Le processus débute avec le Planificateur (Planner), dont le rôle est de décomposer un objectif vague (par exemple, « Améliore la précision de ce modèle de prévision des ventes ») en étapes logiques et exécutables. Il ne code pas, il conçoit une stratégie structurée, en s’appuyant sur des résultats intermédiaires pour ajuster son raisonnement avant chaque étape suivante.
Le Codeur (Coder) prend ensuite le relais, il transforme le plan en un script exécutable, en veillant à ce que le code soit fonctionnel et aligné avec les objectifs définis.
Vient ensuite le Vérificateur (Verifier), un juge basé sur un LLM, dont la mission est d’évaluer objectivement si le code produit résout réellement le problème initial. Contrairement à une simple mesure de performance (comme un score de précision), il analyse les résultats intermédiaires et détermine si le plan stratégique sous-jacent est satisfaisant ou nécessite des ajustements.
Si le Vérificateur juge le plan insuffisant, le Routeur (Router) intervient. Il identifie quelles étapes doivent être modifiées, supprimées ou ajoutées, puis réoriente le cycle vers le Planificateur pour une nouvelle itération. Ce mécanisme d’auto-correction itérative (ou grounding) reproduit la démarche d’un expert humain qui affine progressivement sa solution en testant chaque étape.
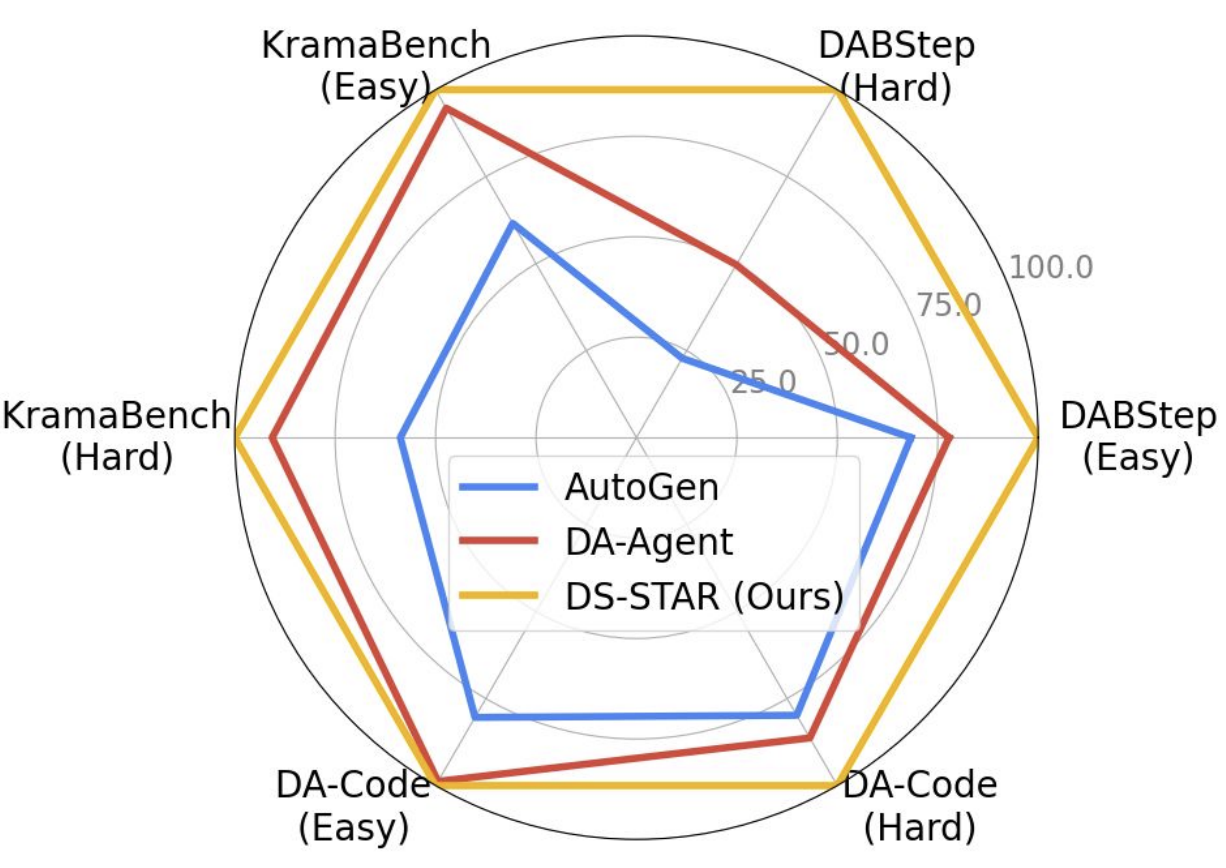
Cette boucle (planifier → coder → vérifier → router) se répète jusqu’à 10 fois maximum, garantissant un équilibre entre rigueur et efficacité. À l’issue de ce processus, DS-STAR génère une solution finale validée par des allers-retours critiques, ce qui lui permet d’atteindre des performances exceptionnelles sur des benchmarks tels que DABench, KramaBench et DA-Code, surpassant nettement des approches concurrentes comme DA-Agent et AutoGen.

La data science assistée par IA
L’arrivée d’outils comme DS-STAR ne signifie pas la fin du métier de data scientist, mais plutôt sa mutation vers un rôle de supervision stratégique. En automatisant le « grunt work », le nettoyage, les tests unitaires de modèles, la sélection de base des hyperparamètres, cet agent libère du temps pour la réflexion métier. Pour un expert, c’est un gain de productivité immense. Pour un développeur web ou un néophyte passionné de tech, c’est une porte d’entrée vers l’analyse de données avancée, rendant accessibles des techniques qui demandaient auparavant des années d’expérience.
Cependant, cette puissance implique aussi de nouvelles responsabilités. La capacité de l’agent à prendre des décisions autonomes sur le traitement des données soulève la question de la vérifiabilité. Même si DS-STAR est conçu pour être transparent dans ses plans et ses exécutions, l’utilisateur humain doit garder un œil critique sur les choix méthodologiques opérés par l’IA.
Google frappe fort avec DS-STAR en proposant bien plus qu’un simple assistant de code. En intégrant la planification et la vérification au cœur du processus, ils offrent un aperçu de l’avenir des agents autonomes. Des systèmes capables de persévérance et de raisonnement face à l’incertitude des données réelles. Nous entrons dans une ère où l’agent pour la science des données devient un collaborateur à part entière, transformant radicalement notre manière de transformer la donnée brute en information exploitable.
[1] Nam, J., Yoon, J., Chen, J., & Pfister, T. (2025). DS-STAR: Data Science Agent via Iterative Planning and Verification. arXiv. https://doi.org/10.48550/arXiv.2509.21825
[2] DS-STAR: A state-of-the-art versatile data science agent