Intelligence Artificielle
Word Embedding : Comment l’IA apprend des mots ?
Pourquoi « chat » et « chien » semblent-ils proches pour nous, mais totalement opaques pour une machine ? Avant les réseaux neuronaux modernes, les ordinateurs voyaient surtout les mots comme des identifiants, sans nuances ni proximité. Le Word Embedding (ou plongement lexical) a changé la donne : il transforme chaque mot en un vecteur de nombres qui capture une partie de son sens et de son usage. Cette idée simple, représenter les mots par des points dans un espace, est devenue l’une des briques essentielles du traitement automatique du langage (NLP), et elle reste au cœur des modèles d’IA contemporains. Comprendre le word embedding, c’est mettre la main sur la clé qui a permis de passer des sacs de mots rudimentaires aux systèmes de dialogue et moteurs de recherche actuels.
Comprendre le Word Embedding : c’est quoi et pourquoi c’est utile ?
Un word embedding est une manière de transformer les mots en vecteurs numériques de taille fixe, placés dans un espace géométrique où la proximité reflète des similitudes d’usage. Contrairement à l’encodage « one-hot », qui attribue à chaque mot un identifiant isolé sans relation avec les autres, l’embedding capture des proximités sémantiques et syntaxiques, deux mots qui apparaissent dans des contextes comparables auront des vecteurs proches, suivant l’hypothèse distributionnelle selon laquelle « un mot est défini par les contextes dans lesquels il apparaît ».
Cette intuition, issue de la linguistique formelle, a été concrétisée en intelligence artificielle par des modèles comme Word2Vec, qui entraînent un petit réseau de neurones sur de vastes corpus. Le principe est simple : le modèle apprend à prédire un mot à partir de son contexte (ou inversement), et les poids internes du réseau deviennent les représentations vectorielles des mots.
Au fil de l’entraînement, ces vecteurs s’organisent dans l’espace : les mots comme roi et reine se retrouvent voisins, tandis que certaines directions capturent des relations régulières, comme masculin/féminin ou singulier/pluriel. On peut se représenter ce phénomène comme une carte où chaque mot est une ville : la distance entre deux villes traduit leur substituabilité dans une phrase, et les directions révèlent des motifs analogiques. Ainsi, le word embedding fournit une structure géométrique qui agit comme une boussole pour les algorithmes, leur permettant de manipuler non seulement des symboles, mais aussi les relations de sens qui les unissent.

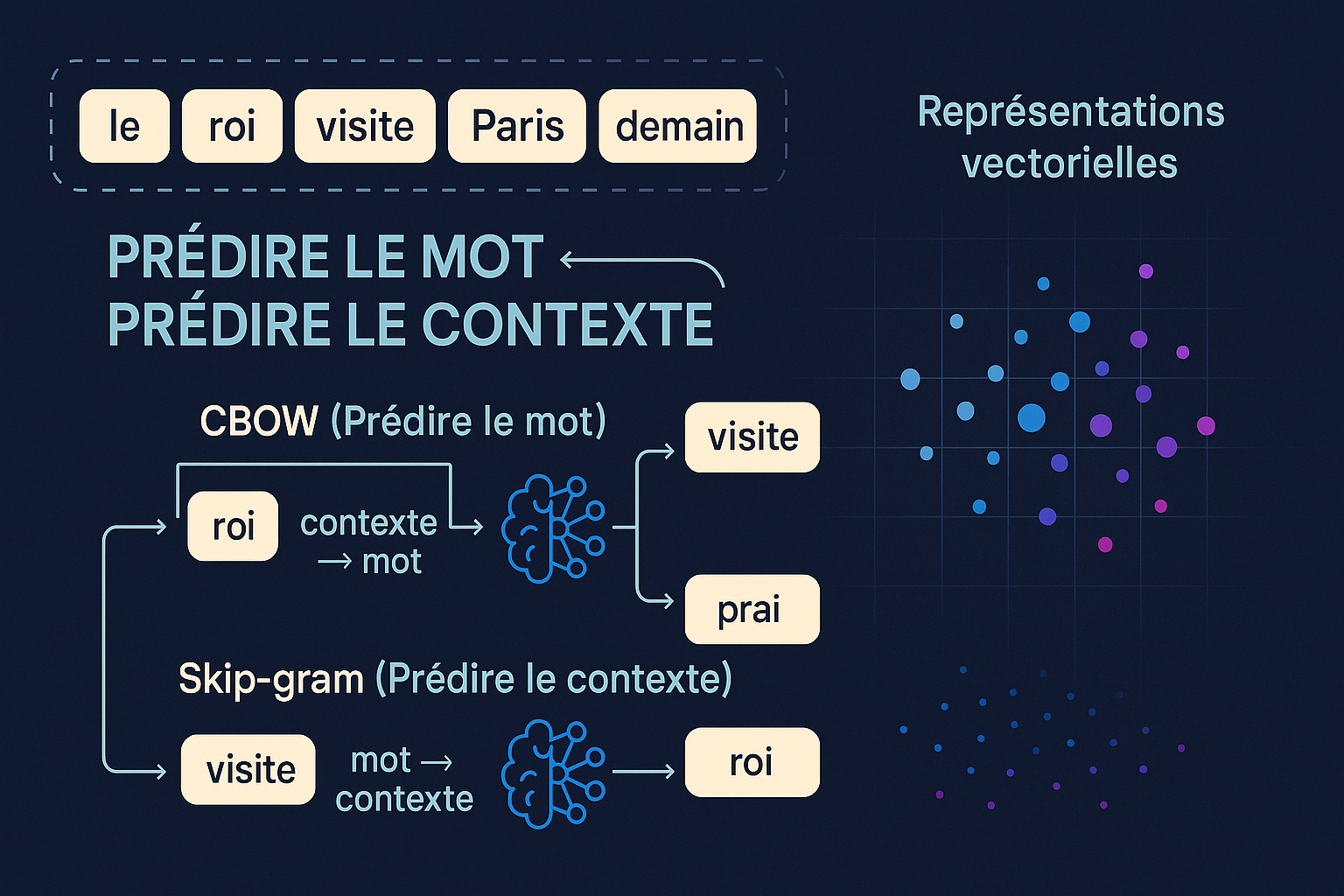
Comment ça marche concrètement ?
Pour transformer un texte brut en représentations vectorielles exploitables, on entraîne des modèles capables de prédire un mot à partir de son contexte ou, à l’inverse, de prédire le contexte à partir d’un mot. Deux approches devenues classiques avec Word2Vec, CBOW (Continuous Bag-of-Words) et Skip-gram, réalisent ce travail en apprenant des embeddings (représentation d’un modal, un mot, une phrase, une image, out autre sous la forme d’un vecteur de nombres réels) comme produit secondaire de la tâche de prédiction.
Dans les deux cas, l’objectif n’est pas seulement de réussir ces prédictions ponctuelles, mais surtout de construire, en arrière-plan, des représentations vectorielles où les mots qui coapparaissent fréquemment dans des contextes similaires sont rapprochés, et ceux qui n’ont aucun lien sémantique sont éloignés. L’entraînement repose donc sur l’optimisation d’une fonction qui ajuste progressivement les vecteurs afin de refléter ces relations.
Pour rendre ce processus praticable sur de très grands corpus, des astuces d’efficacité comme le negative sampling sont utilisées. Au lieu de comparer chaque mot à l’ensemble du vocabulaire (ce qui serait trop coûteux), on sélectionne un petit nombre de mots « négatifs » qui n’apparaissent pas dans le contexte et on apprend à les distinguer des bons candidats. Ainsi, de manière indirecte, mais efficace, CBOW et Skip-gram produisent des embeddings riches en informations linguistiques, tout en restant légers et rapides à entraîner.
Vecteurs statiques aux représentations contextuelles
Les embeddings statiques donnent toujours le même vecteur à un mot, peu importe la phrase où il se trouve. Le problème, c’est que certains mots ont plusieurs sens : par exemple « vol » peut désigner un trajet en avion ou un délit, mais un seul vecteur ne peut pas faire la différence. Pour résoudre ça, on a inventé les embeddings contextuels. Avec des modèles modernes comme ELMo, BERT ou GPT, chaque mot est représenté par un vecteur qui dépend de la phrase entière. En tenant compte de toute la phrase : « le vol a été retardé » n’a pas le même vecteur que « le vol a eu lieu hier ». Cette finesse améliore fortement la compréhension du sens, la désambiguïsation et les performances sur de nombreuses tâches, même si le principe de base reste le même, projeter les mots dans un espace où la proximité signifie une ressemblance de sens.
Ce glissement des embeddings statiques vers les modèles de langage a aussi changé la manière dont on conçoit les applications. Au lieu d’entraîner un embedding from scratch pour chaque projet, on réutilise les représentations apprises par de grands modèles, puis on les adapte à la tâche. Dans TensorFlow, par exemple, on peut intégrer ces embeddings comme couches au sein d’un réseau, ou récupérer des vecteurs issus d’un modèle préentraîné pour alimenter une recherche sémantique, un classifieur, ou un système de recommandation.
Word Embedding, modèles et stack moderne
Aujourd’hui, quand on parle de word embedding dans l’écosystème moderne, on peut distinguer trois grands niveaux. Le premier est celui des embeddings statiques, comme Word2Vec (avec ses variantes CBOW et Skip-gram), GloVe ou encore FastText. Ces modèles attribuent à chaque mot un vecteur unique, quel que soit le contexte. Leur intérêt est qu’ils sont rapides, simples et restent utiles dans des tâches où la compréhension profonde du contexte n’est pas essentielle, ou lorsque les ressources de calcul sont limitées.
Le deuxième niveau correspond aux embeddings contextuels, introduits avec ELMo puis popularisés par BERT, ses variantes et les modèles de type GPT. Ici, chaque mot reçoit une représentation différente selon la phrase où il apparaît, ce qui permet une bien meilleure compréhension des nuances et des ambiguïtés. On obtient ces embeddings en utilisant des modèles de langage préentraînés ou en extrayant les représentations intermédiaires de leurs couches internes. Cette approche est devenue dominante pour les tâches complexes de compréhension du langage.
Enfin, le troisième niveau regroupe les embeddings universels et multimodaux, qui ne se limitent plus aux mots, ils représentent aussi des phrases, des documents, des images ou même du code. Le principe de base reste le même, la proximité vectorielle traduit une similarité de sens, mais les architectures s’adaptent pour traiter différents types de données. Cette généralisation illustre comment l’idée d’« embedding » s’est étendue bien au-delà du texte pur pour devenir une brique fondamentale de l’intelligence artificielle moderne.