Intelligence Artificielle
Modèle IA : Comprendre les formats Safetensors et GGUF
Comprendre Safetensors et GGUF pour exploiter les modèles de langage selon votre matériel informatique.
Lorsqu’on explore les plateformes de partage de modèles d’intelligence artificielle comme Hugging Face, une question revient systématiquement, pourquoi un même modèle existe-t-il en plusieurs versions, portant des noms étranges comme Safetensors ou souvent GGUF ?
Cette apparente complexité cache en réalité une logique simple et pragmatique. Comprendre ces formats, vous permettrons un utilisation personnalisée des modèles IA, adaptée à votre matériel et vos besoins. Que vous disposiez d’une station de travail surpuissante ou d’un ordinateur portable standard, il existe un format pensé pour vous.
Pourquoi plusieurs formats Safetensors et GGUF pour un même modèle ?
La multiplication des formats de modèles IA répond à une contrainte fondamentale. L’extraordinaire diversité du matériel informatique utilisé par les développeurs et passionnés de technologie. Un grand modèle de langage (LLM) peut peser plusieurs dizaines de gigaoctets dans sa version complète. Or, tout le monde ne dispose pas d’une carte graphique professionnelle avec ou moins 24 Go de mémoire vidéo dédiée.
Cette réalité technique a conduit la communauté à développer différents formats, chacun optimisé pour un usage spécifique. Certains privilégient la performance brute et la fidélité absolue au modèle original, tandis que d’autres misent sur la compression intelligente pour rendre ces technologies accessibles au plus grand nombre.
Safetensors, le format de référence non compressé
Le format Safetensors s’est progressivement imposé comme le standard de facto pour la distribution des modèles d’intelligence artificielle. Son nom évoque directement sa philosophie, la sécurité avant tout. Contrairement aux formats plus anciens comme le pickle de Python, Safetensors a été conçu pour éliminer les risques d’exécution de code malveillant lors du chargement d’un modèle.

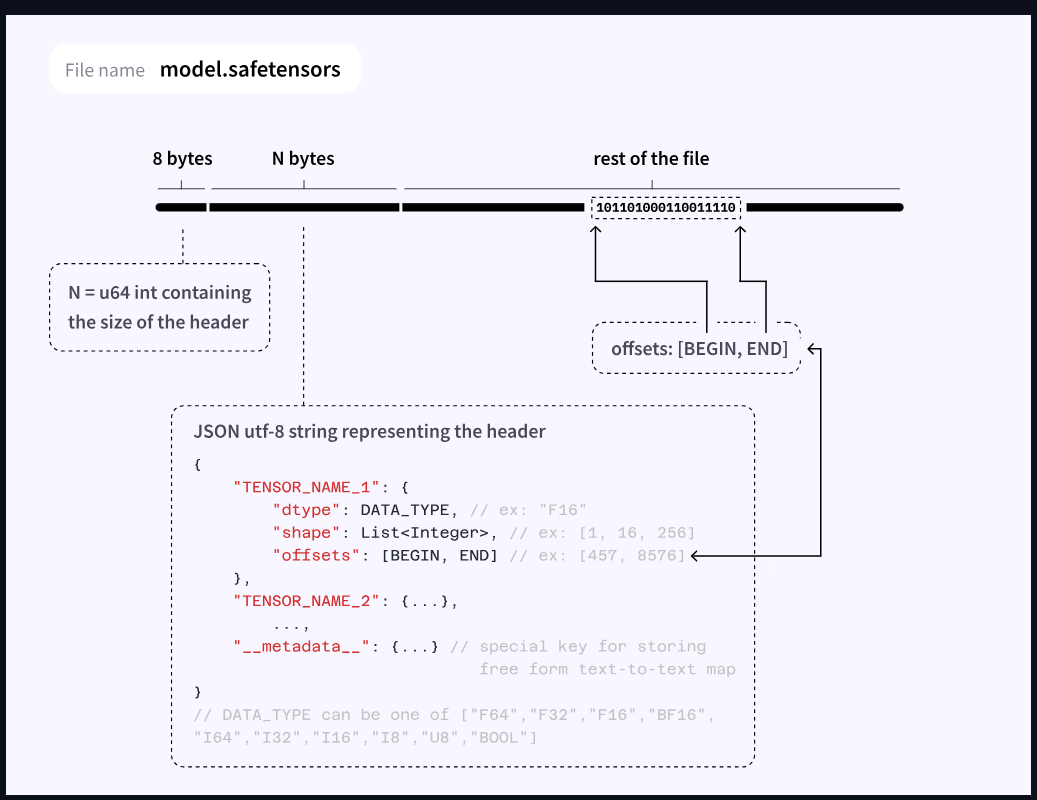
Cette conception simple et transparente garantit la sécurité en évitant l’exécution de code arbitraire lors du chargement, contrairement aux anciens formats.
Techniquement, Safetensors stocke les poids du réseau neuronal dans leur précision d’origine, généralement en format float16 ou float32. Cette absence de compression garantit que le modèle fonctionne exactement comme ses créateurs l’ont entraîné, sans aucune perte de qualité ou modification des performances. Pour les utilisateurs qui recherchent les résultats les plus fidèles possibles, Safetensors représente le choix évident.
Cependant, cette fidélité a un prix. Les modèles au format Safetensors nécessitent une mémoire conséquente, principalement sur la carte graphique. Un modèle de 7 milliards de paramètres occupera environ 14 Go de VRAM. Cette exigence matérielle réserve de facto Safetensors aux utilisateurs équipés de cartes graphiques performantes, typiquement les GPU NVIDIA de gamme professionnelle ou gaming haut de gamme. Pour ceux qui possèdent ce type d’équipement, Safetensors offre une expérience optimale avec des temps de génération rapides et une qualité maximale.
GGUF, la révolution de la quantification accessible
Face aux limitations matérielles qui excluaient une large part du public, le format GGUF apparaît comme une véritable innovation démocratique. Développé dans l’écosystème llama.cpp, GGUF repose sur un principe ingénieux, la quantification. Cette technique consiste à réduire la précision numérique des poids du modèle, passant par exemple de nombres flottants sur 16 bits à des entiers sur 4 ou 8 bits.
Le génie de GGUF réside dans son approche pragmatique de cette compression. Plutôt que de proposer un seul niveau de quantification, le format offre tout un spectre de choix, désignés par des codes comme Q4_K_M ou Q8_0. Chaque niveau représente un compromis différent entre taille de fichier et préservation de la qualité. Un modèle quantifié en Q4 pèsera environ quatre fois moins lourd que sa version Safetensors, tout en conservant généralement plus de 95% de ses capacités originales.


Les métadonnées contiennent des informations essentielles comme l’architecture du modèle (llama), le type de tokenizer et le contexte maximum. Cette structure organisée permet une lecture efficace et une compatibilité optimale avec les outils comme llama.cpp ou LM Studio.
L’autre révolution apportée par GGUF concerne l’utilisation de la mémoire. Contrairement à Safetensors qui sollicite massivement la carte graphique, GGUF peut fonctionner principalement sur la RAM classique de votre ordinateur. Cette flexibilité transforme radicalement l’équation matérielle. Un PC portable standard avec 16 Go de RAM peut désormais faire tourner des modèles qui nécessitaient auparavant une station de travail professionnelle. Pour les utilisateurs disposant d’une configuration modeste, GGUF ouvre l’accès à des modèles d’intelligence artificielle qui leur étaient jusqu’alors inaccessibles.
Comment choisir entre Safetensors et GGUF en pratique ?
Le choix entre Safetensors et GGUF dépend essentiellement de votre configuration matérielle et de vos priorités. Si vous possédez une carte graphique puissante avec au moins 12 Go de VRAM et que vous recherchez les meilleures performances possibles, Safetensors s’impose naturellement. En revanche, si votre matériel est plus limité ou si vous souhaitez expérimenter avec plusieurs modèles simultanément, GGUF représente le choix pragmatique.

Pour exploiter ces formats, plusieurs outils se sont imposés dans l’écosystème. LM Studio constitue probablement la solution la plus accessible pour les débutants. Cette application graphique intuitive permet de télécharger, gérer et utiliser des modèles au format GGUF sans toucher une seule ligne de code. L’interface claire guide l’utilisateur dans le choix du niveau de quantification approprié à sa configuration.
Pour ceux qui privilégient la rapidité et l’efficacité en ligne de commande, Ollama s’est taillé une réputation solide. Cet outil simplifie le téléchargement et l’exécution de modèles GGUF avec une syntaxe minimaliste. Enfin, llama.cpp représente le moteur de référence pour les utilisateurs avancés qui souhaitent un contrôle total sur les paramètres d’exécution. Ces trois solutions forment un écosystème complémentaire qui couvre tous les niveaux d’expertise.
Formats de modèles IA
La coexistence des formats Safetensors et GGUF illustre une tendance fondamentale dans le développement de l’intelligence artificielle. Alors que les modèles continuent de gagner en sophistication et en taille, la quantification intelligente représentée par GGUF devient de plus en plus stratégique.
Cette évolution technique s’inscrit dans un mouvement plus large de démocratisation de l’IA. En permettant à davantage d’utilisateurs d’expérimenter localement avec des modèles avancés, ces formats participent à la diffusion des connaissances et à l’émergence d’une communauté plus diverse de créateurs et d’innovateurs.