Algorithme
Clustering : Travaux pratiques avec K-Means
À l’ère des données massives, savoir structurer et interpréter l’information est essentiel. Mais que faire lorsqu’on ne dispose d’aucune étiquette pour guider l’analyse ? C’est là qu’intervient le clustering, une technique d’apprentissage automatique non supervisé qui permet de regrouper automatiquement des données similaires.
Le clustering est largement utilisé pour explorer, segmenter ou organiser des jeux de données, sans nécessiter d’exemples préalablement classés. Dans cet article, nous découvrirons ce qu’est le clustering, dans quels contextes il est utilisé, quels sont ses principaux algorithmes, et en quoi il diffère des approches supervisées comme la classification.
Qu’est-ce que le Clustering ?
Le clustering, c’est un peu comme jouer à faire des groupes avec des objets sans avoir d’étiquettes sur eux. Imagine que tu reçoives une boîte pleine de billes multicolores de tailles différentes. Sans aucune consigne, tu essaies instinctivement de les regrouper, les grosses ensemble, les rouges d’un côté, les petites bleues ailleurs… C’est exactement ce que fait le clustering en data science. Il regroupe automatiquement les données qui se ressemblent, sans qu’on lui dise à l’avance quels sont les bons groupes. C’est ce qu’on appelle une méthode non supervisée, car il n’y a pas de réponse « correcte » fournie à l’algorithme.
Techniquement, l’objectif est de créer des clusters, c’est-à-dire des ensembles de points similaires selon certains critères (valeurs numériques, comportements, formes, etc.). Pour ça, les algorithmes utilisent des mesures de distance (comme la distance euclidienne) ou de densité pour calculer la proximité entre les points. L’idéal, c’est que les éléments d’un même cluster soient très proches entre eux, et très éloignés des autres groupes. C’est une façon efficace de découvrir des structures cachées dans des données complexes, d’en tirer des tendances ou même d’initier un processus d’annotation intelligente. Bref, le clustering, c’est l’art de révéler l’ordre dans le chaos !
Principaux algorithmes de clustering
Il existe une variété d’algorithmes de clustering, chacun avec sa propre manière de détecter les similarités et de former des groupes. Certains, comme les méthodes hiérarchiques, construisent des regroupements en formant peu à peu une arborescence de liens entre les données. D’autres, comme DBSCAN, s’appuient sur la densité locale pour identifier des zones peuplées et repérer les points isolés. Il existe aussi des approches plus sophistiquées, comme le clustering spectral, qui s’appuient sur des notions de graphes et d’algèbre linéaire.
Le choix de l’algorithme dépend souvent de la forme des données, de la taille de l’échantillon, et des objectifs du projet. Mais parmi tous ces outils, il en est un qui reste incontournable tant pour sa simplicité que pour son efficacité, le K-Means, l’algorithme de clustering le plus utilisé dans la pratique.
K-Means, le classique du clustering
L’algorithme K-Means est une star du clustering, autant pour sa simplicité que pour sa rapidité. Il est utilisé lorsqu’on veut diviser un ensemble de données en k groupes distincts, appelés clusters, tout en gardant chaque groupe aussi homogène que possible. K-Means fonctionne selon un principe intuitif, chaque groupe est représenté par un point central (appelé centroïde) et chaque donnée va se coller au centroïde le plus proche. Ce mécanisme est idéal pour des données bien réparties et relativement « rondes », comme des nuages de points.
Voici comment K-Means fonctionne, étape par étape :
- Choisir le nombre de clusters (k) à créer (ce choix est crucial !).
- Initialiser aléatoirement k centroïdes dans l’espace des données.
- Assigner chaque point au centroïde le plus proche (selon une distance, souvent euclidienne).
- Recalculer les centroïdes en prenant la moyenne des points associés à chaque groupe.
- Répéter les étapes 3 et 4 jusqu’à ce que les centroïdes ne bougent plus (ou très peu).
Ce processus d’optimisation est rapide, ce qui fait de K-Means un excellent choix pour des jeux de données volumineux. Mais attention, il a aussi ses faiblesses. Il faut choisir k à l’avance, ce qui peut être difficile sans connaissance préalable des données. De plus, il peut être trompé par des clusters de formes irrégulières, de tailles très différentes ou contenant des outliers (valeurs aberrantes). Malgré cela, K-Means reste un point d’entrée incontournable en clustering, et souvent la première étape pour explorer et comprendre une base de données complexe.
Appliquons K-Means sur de vraies données
Pour mettre en œuvre ce que nous avons appris, nous allons utiliser un jeu de données réel et emblématique, le dataset Iris. Ce jeu de données, très populaire en data science, contient 150 observations de fleurs mesurées selon 4 caractéristiques numériques, la longueur et la largeur des sépales et des pétales.
Ces données sont associées à trois espèces de fleurs différentes (setosa, versicolor et virginica), mais attention, pour le clustering, nous ne tiendrons pas compte des étiquettes. L’objectif est de voir si K-Means est capable de retrouver automatiquement les groupes naturels présents dans les données, en se basant uniquement sur les mesures. Nous en profiterons pour visualiser les clusters obtenus et comparer leur structure avec la répartition réelle des espèces. C’est un excellent moyen d’illustrer la puissance, mais aussi les limites du clustering non supervisé sur des données du monde réel. Le code complet du TP est disponible sur Colab.
Importation des modules utile au traitement
Pour bien démarrer notre projet de clustering, il est essentiel d’importer les bibliothèques nécessaires. Nous utiliseront ici python. Ces modules vont nous permettre de charger les données, d’explorer leur structure et d’appliquer nos algorithmes. Pour nos travaux, nous avons principalement utilisé Scikit-Learn.
#Importation des différentes dépendence
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import pandas as pdVisualisation du Dataset Iris
Avant de lancer les traitements d’analyse ou de clustering, il est important de prendre un moment pour explorer nos données. Nous allons commencer par observer leur structure générale afin de mieux comprendre ce que contient notre jeu de données.
# 1. Chargement des données Iris
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# 2. EDA - Aperçu des données
print("Aperçu du dataset :")
print(df.head(10))
#print(df.tail(10)) => Pour voir les 10 dernières lignes
Application de K-Means
Comme mentionné précédemment, K-Means est un algorithme de regroupement efficace, capable de rassembler les données selon des critères de similarité, ce qui le rend particulièrement utile pour l’étiquetage automatique. Dans notre cas, nous allons ignorer les valeurs cibles déjà présentes dans le dataset et nous appuyer uniquement sur les caractéristiques (features) disponibles pour effectuer le clustering.
X = iris.data
y_true = iris.target # Les vraies classes (non utilisées par K-Means)
# Appliquer K-Means avec k=3 (car il y a 3 espèces de fleurs)
kmeans = KMeans(n_clusters=3, random_state=42)
y_kmeans = kmeans.fit_predict(X)
# Réduction de dimension pour visualisation (PCA en 2D)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)En utilisant le paramètre n_clusters de KMeans, nous avons choisi n_clusters = 3, car nous savons à l’avance que notre jeu de données contient trois catégories de fleurs.
Cette information, bien que normalement inconnue dans un contexte non supervisé, nous permet ici d’évaluer la performance de l’algorithme. Par la suite, nous utilisons le PCA (Analyse en Composantes Principales) pour réduire les dimensions des données et permettre une visualisation claire des clusters en deux dimensions.
Pour visualiser les clusters vous pouvez ajouter se bloque à votre notebook
# Visualisation des clusters prédits
plt.figure(figsize=(8, 5))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_kmeans, cmap='viridis', s=50)
centers = pca.transform(kmeans.cluster_centers_) # centres réduits en 2D
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, marker='X', label='Centres')
plt.title("Clustering K-Means sur Iris (projection 2D)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.legend()
plt.show()Vous devez avoir un graphe comme celui-ci si vous avez suivie l’ensemble du proccessuce. On remarque qu’il y a trois centroid désignent ici trois clusters qui sont ceux de nos fleurs.

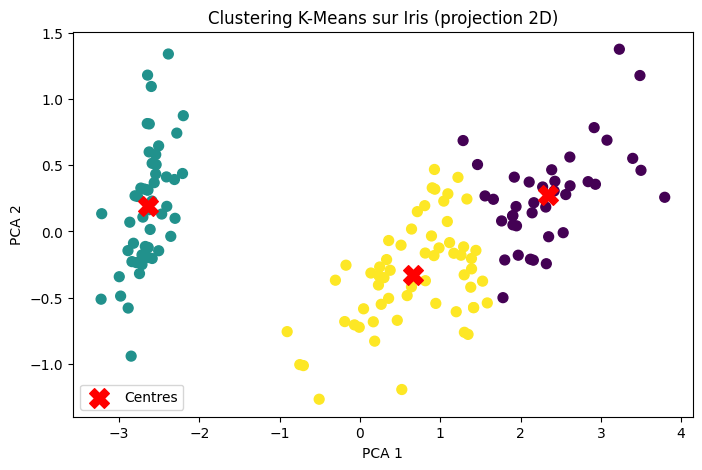
Evaluons nos résultats
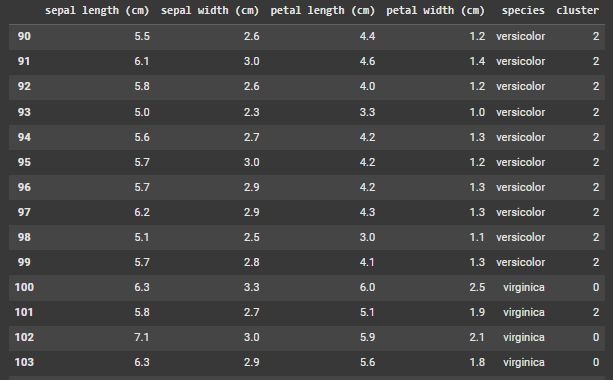
Afin d’évaluer la fiabilité de notre approche, nous avons ajouté les clusters prédits dans notre dataset, ce qui nous permet de comparer visuellement les regroupements obtenus avec les vraies catégories.
Bien que quelques erreurs de regroupement soient apparentes, ce qui est attendu dans une approche non supervisée, nous avons pu constater que K-Means a correctement identifié les structures naturelles des données dans la majorité des cas. Cela montre que, l’algorithme parvient à retrouver des schémas cohérents et utiles comme vous pouvez le remarquer dans cette image.

Clustering ou Prédiction ? Deux approches, deux objectifs
Il est important de bien distinguer le clustering des méthodes classiques de prédiction supervisée, comme la régression ou la classification. Ces deux types d’approches appartiennent au domaine de l’apprentissage automatique, mais ils répondent à des objectifs très différents.
Les méthodes supervisées (comme la régression ou la classification) utilisent un jeu de données étiqueté, c’est-à-dire que pour chaque observation, on connaît la « bonne réponse ». L’objectif est d’apprendre une fonction qui permettra de prédire une valeur ou une étiquette pour de nouvelles données. Exemple : prédire le type d’un animal (chat, chien…) ou le prix d’une maison.
À l’inverse, le clustering est non supervisé, on ne connaît pas les étiquettes, et l’algorithme tente de découvrir des structures ou des regroupements dans les données. On ne cherche pas à faire une prédiction explicite, mais plutôt à explorer ou segmenter les données selon leurs similarités internes. Le clustering est donc plus adapté à des tâches exploratoires, segmentation de clients, regroupement d’articles, détection d’anomalies, ou même préparation d’un jeu de données pour une annotation supervisée.
| Critère | Clustering | Classification / Régression |
|---|---|---|
| Type d’apprentissage | Non supervisé | Supervisé |
| Présence de labels | Non | Oui |
| Objectif | Découvrir des groupes cachés | Prédire une valeur ou une catégorie |
| Sortie du modèle | Numéro de cluster | Label (classe) ou valeur continue |
| Exemples d’usage | Segmentation client, regroupement d’images | Prédire un diagnostic, classifier un email |
Que retenir ?
Le clustering est un pilier de l’apprentissage non supervisé. Il permet d’explorer des données brutes, de détecter des structures naturelles, ou encore d’optimiser le travail d’annotation. Bien qu’il ne permette pas de faire des prédictions comme les méthodes supervisées, son rôle est crucial dans tout pipeline de data science.
Que vous cherchiez à comprendre votre clientèle, à trier des documents ou à simplifier un jeu de données complexe, le clustering offre une approche souple, intuitive et puissante.