Actualité
GPT-5.4 et capacités agentiques natives pour transformer le travail professionnel
Découvrez GPT-5.4 : architecture agentique révolutionnaire, efficacité token améliorée de 47%. Le nouveau standard pour les workflows automatisés complexes.
OpenAI vient de lever le voile sur GPT-5.4, son nouveau modèle qui marque une rupture technologique majeure dans l’écosystème des modèles de langage. Contrairement aux itérations précédentes, gpt 5.4 se distingue par l’intégration native de capacités de contrôle informatique, une fonctionnalité qui transforme fondamentalement la manière dont les agents IA interagissent avec les environnements logiciels.
Le timing de cette annonce intervient dans un contexte de compétition intense entre les acteurs majeurs de l’IA générative, où chaque gain de performance sur les benchmarks professionnels devient un différenciateur stratégique. Avec gpt 5.4, OpenAI propose non seulement un modèle plus performant, mais surtout une architecture repensée pour supporter les workflows agentiques de nouvelle génération.
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT.
— OpenAI (@OpenAI) March 5, 2026
GPT-5.4 is also now available in the API and Codex.
GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model. pic.twitter.com/1hy6xXLAmJ
Architecture agentique et contrôle informatique natif
La caractéristique technique la plus remarquable de gpt 5.4 réside dans ses capacités de computer-use intégrées directement au cœur du modèle. Concrètement, le système peut désormais interpréter des captures d’écran, émettre des commandes clavier et souris, et naviguer de manière autonome dans différentes applications. Cette fonctionnalité s’appuie sur des bibliothèques d’automatisation comme Playwright, permettant au modèle d’écrire du code pour piloter les interfaces utilisateur sans intervention humaine.
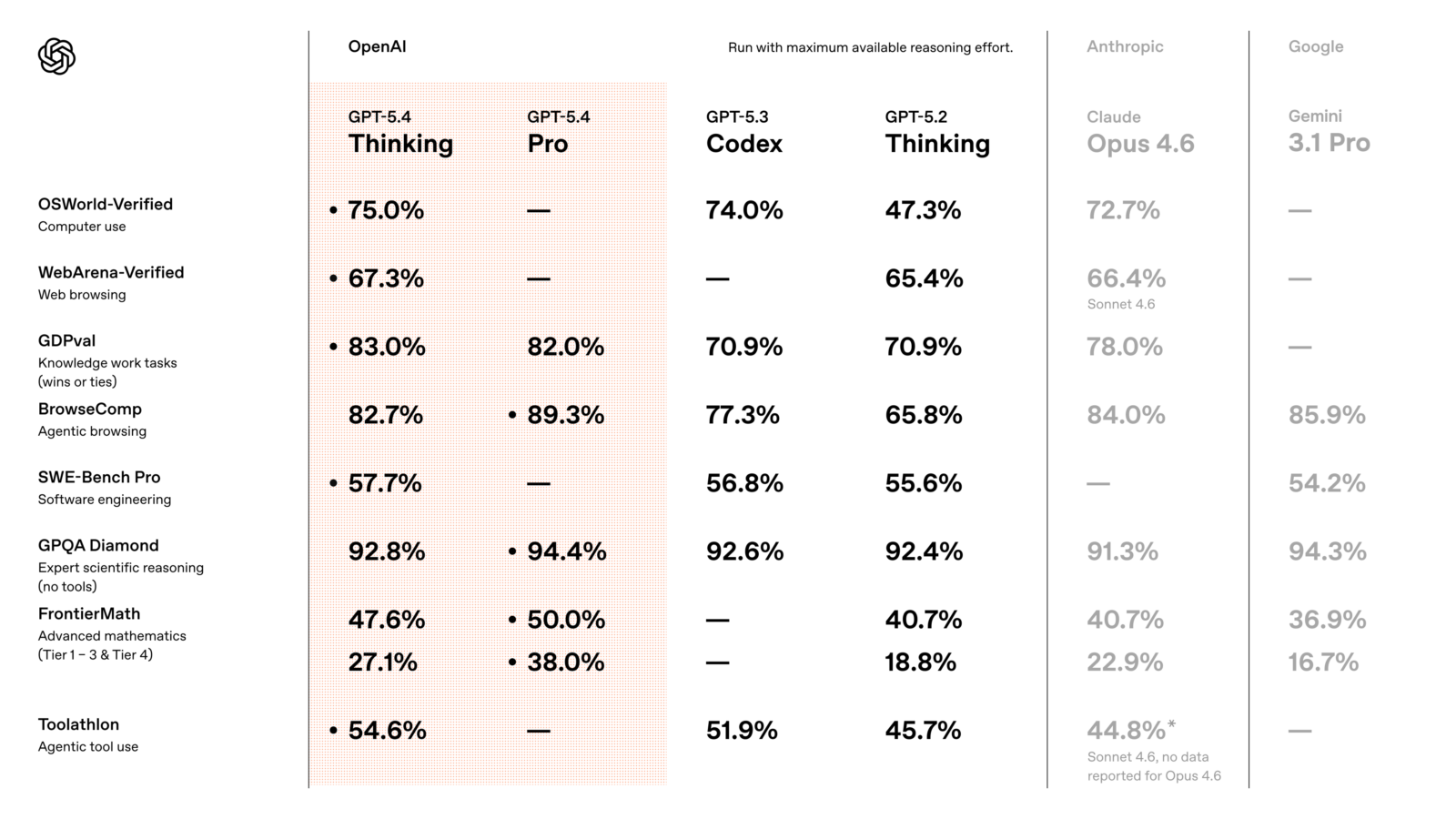
Cette approche marque une évolution significative par rapport aux solutions précédentes qui nécessitaient des couches d’abstraction supplémentaires. Les performances mesurées sur le benchmark OSWorld-Verified illustrent cette avancée avec un taux de réussite de 75%, démontrant la capacité du modèle à accomplir des tâches multi-étapes dans des environnements de bureau réels. Sur WebArena Verified, gpt 5.4 établit également de nouveaux records, confirmant sa robustesse dans la navigation web complexe.

La fenêtre de contexte atteint désormais 1 million de tokens dans l’API et Codex, permettant aux agents de planifier, exécuter et vérifier des tâches sur des horizons temporels beaucoup plus longs. Cette expansion du contexte s’avère particulière utile pour les workflows nécessitant la consultation de documentation volumineuse ou l’analyse de bases de code étendues.
Performances benchmark et fiabilité accrue avec GPT 5.4
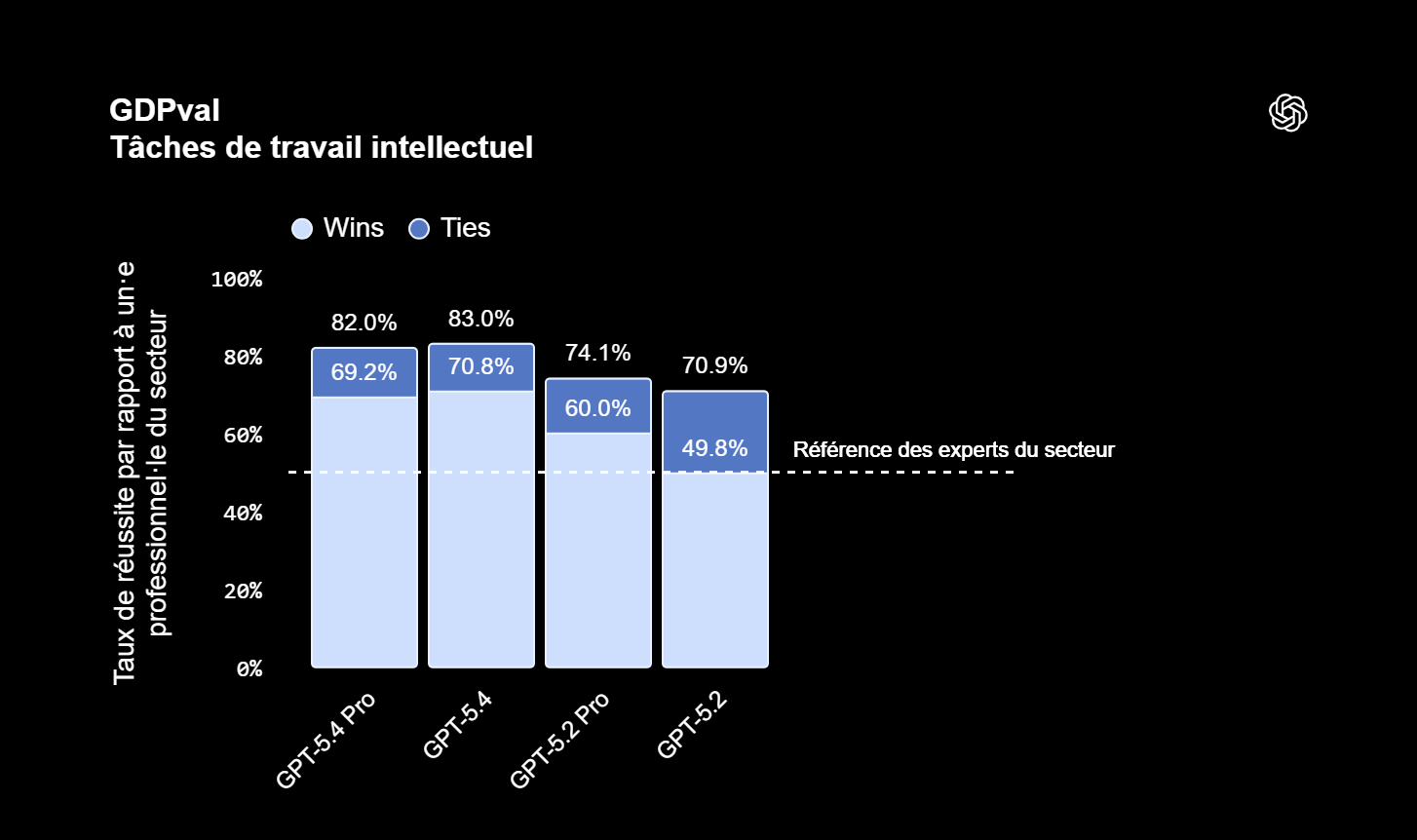
Les résultats sur le benchmark GDPval révèlent une progression notable dans les capacités de travail professionnel du modèle. Avec un score de 83%, gpt 5.4 égale ou surpasse les performances de professionnels humains dans 83% des comparaisons effectuées sur 44 occupations différentes, contre 70,9% pour GPT-5.2. Ces tests couvrent les 9 principales industries contribuant au PIB américain, offrant une évaluation réaliste des compétences professionnelles du modèle.

Dans le domaine spécifique de la modélisation de feuilles de calcul, les performances atteignent 87,3% contre 68,4% pour la version précédente. Cette amélioration substantielle s’explique par l’intégration des capacités de GPT-5.3-Codex, spécialisé dans le code, et par une meilleure compréhension des structures et formules utilisées dans les environnements professionnels réels.
Le benchmark APEX-Agents de Mercor, qui évalue les compétences professionnelles en droit et finance, place également gpt 5.4 en tête du classement. Sur BigLaw Bench, le modèle atteint 91%, démontrant sa capacité à structurer des analyses transactionnelles complexes et à maintenir la précision à travers de longs contrats juridiques.
Réduction des hallucinations et efficacité token chez GPT 5.4
OpenAI a consacré des efforts considérables à la réduction des hallucinations, un défi persistant dans les modèles de langage. Les métriques internes révèlent que les affirmations individuelles de gpt 5.4 sont 33% moins susceptibles d’être fausses comparé à GPT-5.2, tandis que les réponses complètes contiennent 18% d’erreurs en moins. Ces améliorations résultent d’ajustements dans le processus d’entraînement et d’optimisation du système de vérification factuelle.
L’efficacité en termes de tokens représente un autre progrès technique significatif. Le modèle résout les mêmes problèmes en utilisant substantiellement moins de tokens que ses prédécesseurs, ce qui se traduit directement par des coûts opérationnels réduits pour les utilisateurs de l’API.
La recherche web approfondie bénéficie également d’améliorations notables, notamment pour les requêtes hautement spécifiques. Le modèle maintient mieux le contexte lors de questions nécessitant une réflexion prolongée, évitant la perte d’informations critiques au fil des échanges multiples.
Evolution des agents IA autonomes
GPT-5.4 représente une avancée technique dans l’évolution des agents IA autonomes. L’intégration native du computer-use, combinée à des performances benchmark exceptionnelles et une réduction significative des erreurs, positionne ce modèle comme une infrastructure capable de gérer des workflows professionnels complexes de bout en bout.
Cette convergence de capacités techniques ouvre la voie à une nouvelle génération d’applications agentiques où l’automatisation intelligente devient viable pour une gamme élargie de tâches professionnelles.