Revue de Recherche
DeepSeek-OCR : Compression de contexte avec la vision 2D
Les grands modèles de langage (LLMs) sont aujourd’hui capables de raisonner, rédiger, coder et dialoguer avec une fluidité impressionnante, mais même les plus puissants d’entre eux butent sur une contrainte fondamentale, la longueur du contexte. Plus un texte est long, qu’il s’agisse d’un échange conversationnel, d’un code source ou d’un document, plus il nécessite de tokens pour être représenté, ce qui augmente la mémoire utilisée, ralentit le traitement et multiplie les coûts.
Face à cet obstacle, DeepSeek propose une réponse radicalement nouvelle avec DeepSeek-OCR. Plutôt que de chercher à étendre indéfiniment la fenêtre de contexte, une solution coûteuse en ressources, l’approche vise à compresser intelligemment l’information textuelle avant même qu’elle n’atteigne le modèle.
Longueur du contexte d’un LLM, qu’est-ce que c’est ?
La longueur du contexte ou fenêtre de contexte d’un grand modèle de langage (LLM) désigne le nombre maximal de tokens qu’il peut prendre en compte à la fois lorsqu’on lui soumet une entrée, que ce soit une question, un texte à compléter, un historique de conversation ou un document à analyser. Ce « contexte » est la mémoire immédiate du modèle, tout ce qui s’y trouve peut influencer sa réponse, tout ce qui dépasse cette limite est simplement ignoré.
Concrètement, chaque mot, ponctuation ou symbole est découpé en tokens (unités de base du traitement du langage). Par exemple, la phrase « Bonjour, comment ça va ? » peut être transformée en 6 à 8 tokens selon le modèle. Si un LLM a une fenêtre de contexte de 8 000 tokens, il ne pourra pas « voir » au-delà de ce seuil, même s’il reçoit un roman entier ou un long échange conversationnel.
Pourquoi la longueur du contexte pose problème ?
Même si un LLM peut théoriquement gérer des fenêtres de dizaines ou centaines de milliers de tokens, l’efficacité réelle diminue souvent avec la longueur. Le modèle accorde naturellement plus d’attention aux éléments situés au début ou à la fin du contexte, tandis que l’information placée au milieu risque d’être « noyée », un phénomène bien documenté appelé lost-in-the-middle [1]. Cela limite sa capacité à extraire des faits précis dans un long document ou à maintenir une cohérence sur des dialogues étendus.
Par ailleurs, étendre la fenêtre de contexte a un coût, chaque token supplémentaire augmente la mémoire requise, le temps de traitement et la facture énergétique. Ainsi, la contrainte ne vient pas seulement de la capacité maximale du modèle, mais de l’équilibre entre performance, précision et faisabilité opérationnelle. C’est dans ce contexte qu’émergent des solutions alternatives comme DeepSeek-OCR, qui ne cherchent pas à agrandir la fenêtre, plutôt, à rendre chaque token bien plus informatif.
DeepSeek introduit DeepSeek-OCR, un VLM révolutionnaire
Face aux limites structurelles des grands modèles de langage dans le traitement des longs contextes, DeepSeek propose une rupture conceptuelle avec DeepSeek-OCR, un modèle vision-langage (VLM) conçu non pas pour répondre à des questions sur des images, mais pour compresser efficacement du texte en le traitant comme une image. Plutôt que d’agrandir indéfiniment la fenêtre de contexte, DeepSeek-OCR encode l’information textuelle sous une forme visuelle compacte, qu’un décodeur spécialisé peut ensuite relire avec une précision remarquable. Cette approche transforme la vision en un outil d’efficacité computationnelle, ouvrant la voie à des LLMs capables de « mémoriser » des documents entiers sans surcharger leurs ressources.

DeepSeek a choisi l’OCR comme base de sa compression contextuelle
L’OCR (Reconnaissance Optique de Caractères) est une technologie qui permet de convertir du texte présent dans une image, comme un scan de document, une photo de tableau ou une capture d’écran, en texte numérique exploitable. Traditionnellement, l’OCR était un pipeline en deux étapes, d’abord détecter les zones de texte, puis reconnaître les caractères. Aujourd’hui, grâce aux progrès des modèles vision-langage (VLMs), cette tâche peut être réalisée de bout en bout par un seul modèle, qui « lit » une image comme le ferait un humain. Ce qui rend l’OCR particulièrement intéressante, c’est qu’elle établit un pont naturel entre la vision et le langage, une image de texte contient la même information qu’une séquence de tokens, mais sous une forme spatiale et compacte.
C’est précisément cette dualité qui a guidé le choix de DeepSeek. Plutôt que de traiter le texte uniquement comme une suite linéaire de symboles, l’équipe a vu dans l’OCR un banc d’essai idéal pour tester une nouvelle idée, utiliser la modalité visuelle non pas pour décrire des images, mais pour compresser du texte. En encodant un document sous forme d’image, on préserve sa structure tout en réduisant drastiquement le nombre de tokens nécessaires à sa représentation. L’OCR devient alors un mécanisme de compression contextuelle, où la « lecture » du texte par un modèle devient une opération de décodage visuel. Cette approche ouvre la voie à des systèmes capables de gérer des contextes très longs sans surcharger les ressources, un avantage décisif pour les futurs LLMs.
Architecture de DeepSeek-OCR
DeepSeek-OCR repose sur une architecture end-to-end simple mais ingénieuse, divisée en deux grandes étapes, un encodeur visuel (DeepEncoder) qui transforme le document en une représentation compacte, et un décodeur multimodal (DeepSeek3B-MoE-A570M) qui reconvertit cette représentation en texte. L’encodeur est conçu pour traiter des images haute résolution sans saturer la mémoire, grâce à une combinaison d’attention locale et globale, et à un module de compression convolutif qui réduit drastiquement le nombre de tokens visuels avant leur traitement final. Le décodeur, lui, utilise une architecture Mixture of Experts (MoE) pour lire efficacement ces tokens visuels et générer du texte avec une grande précision, même après une forte compression. Ce flux, permet au système de compresser l’information textuelle tout en conservant son essence, ouvrant la voie à des modèles plus légers et plus rapides.
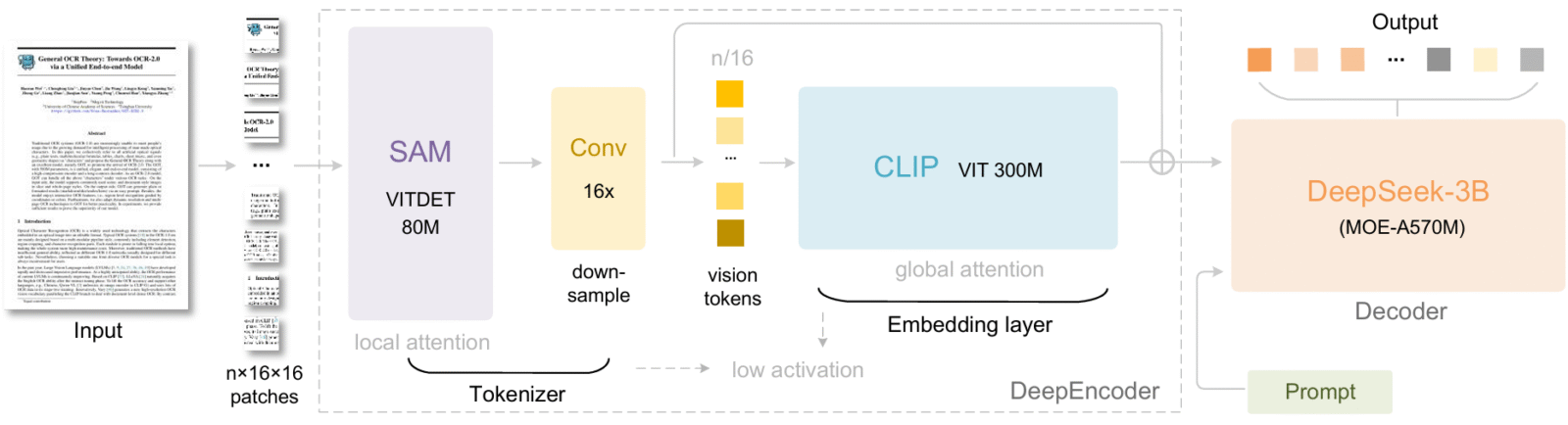
Encodeur DeepEncoder, le cœur de DeepSeek-OCR
Le moteur de compression de DeepSeek-OCR est DeepEncoder. Son objectif est simple mais ambitieux, transformer un document, qu’il soit texte brut, PDF ou image scannée, en une représentation visuelle ultra-compacte, appelée vision tokens, tout en conservant l’essentiel de l’information. Pour y parvenir, il ne traite pas le texte comme une suite linéaire de mots, mais comme une image structurée, où la disposition des titres, paragraphes ou tableaux compte autant que le contenu lui-même.
L’architecture de DeepEncoder repose sur trois blocs clés, agencés en série. Il commence par SAM (Segment Anything Model)[3], un modèle spécialisé dans l’analyse fine des images, qui repère les zones pertinentes du document, texte, formules, graphiques avec une grande précision. Ces zones sont ensuite fortement compressées par un module convolutif 16×, composé de deux couches successives qui réduisent le nombre de tokens visuels par un facteur 16, passant par exemple de 4096 à 256 pour une image de 1024×1024 pixels.
Enfin, CLIP (Contrastive Language–Image Pre-training)[4], plus précisément CLIP-large (dont la couche d’embedding initiale a été retirée, puisqu’il ne reçoit plus des pixels mais des tokens visuels déjà structurés), prend ces fragments compressés et les transforme en une représentation vectorielle riche. C’est cette représentation vectorielle, compacte, mais expressive que le décodeur (DeepSeek3B-MoE) utilise ensuite comme entrée. Grâce à elle, le modèle peut reconstruire le texte d’origine avec une précision remarquable, même après une forte compression.
DeepSeek3B-MoE, le décodeur multimodal derrière DeepSeek-OCR
Le décodeur de DeepSeek-OCR est DeepSeek3B-MoE-A570M, un modèle de langage de 3 milliards de paramètres basé sur une architecture Mixture of Experts (MoE). Contrairement aux modèles denses classiques, ce système n’active qu’une partie de ses paramètres à la fois, soit 570 millions lors de l’inférence, ce qui lui confère une efficacité computationnelle remarquable tout en conservant une grande capacité expressive.
Spécialement entraîné pour la tâche d’OCR, il ne reçoit pas du texte brut, mais une représentation vectorielle compacte issue de DeepEncoder, une séquence de vision tokens qui encode le document sous forme visuelle compressée. Son rôle est de « relire » cette image mentale et de reconstruire fidèlement le texte d’origine, y compris sa structure et son contenu sémantique.
Grâce à cette conception, DeepSeek3B-MoE agit comme un pont entre vision et langage. Il ne fait pas que reconnaître des caractères, il comprend le contexte spatial, interprète des formules chimiques, décode des graphiques ou restitue du texte multilingue, le tout à partir d’une entrée ultra-condensée. Une fois les tokens visuels injectés dans le décodeur, celui-ci génère la réponse textuelle complète de façon autoregressive, token après token, exactement comme un LLM classique le ferait à partir d’un prompt textuel.
Deep Parsing, DeepSeek-OCR comprendre au-delà du texte
DeepSeek-OCR va au-delà de la simple reconnaissance optique de caractères grâce à une fonctionnalité appelée Deep Parsing. Lorsqu’on lui soumet un prompt spécifique, le modèle ne se contente plus de transcrire les mots visibles. Il analyse la structure sémantique de ce qu’il voit, puisl convertit alors ces éléments en formats structurés exploitables, comme des tableaux HTML, du Markdown, ou des notations spécialisées telles que SMILES pour les molécules.
Bien que DeepSeek-OCR soit principalement conçu pour la compression contextuelle et l’OCR avancée, les chercheurs lui ont aussi conféré une certaine capacité à comprendre des images générales, au-delà du simple texte. Comme le montre la figure ci-dessous, il sait par exemple identifier un « enseignant » dans une photo de classe, décrire les éléments d’un emballage alimentaire, ou même reconnaître une image avec un texte en chinois.

LLM capables de “lire” des documents entiers sans saturer leur mémoire ?
DeepSeek-OCR est une première pierre dans la construction d’une nouvelle génération de modèles de langage. En transformant le texte en une représentation visuelle compacte (via DeepEncoder), puis en le relisant avec précision grâce à un décodeur MoE, il prouve qu’il est possible de compresser jusqu’à 20 fois plus de contexte tout en conservant une grande partie de l’information. À 10× de compression, la précision atteint 97 %, même à 20×, elle reste autour de 60 %, un résultat remarquable pour un système aussi efficace.
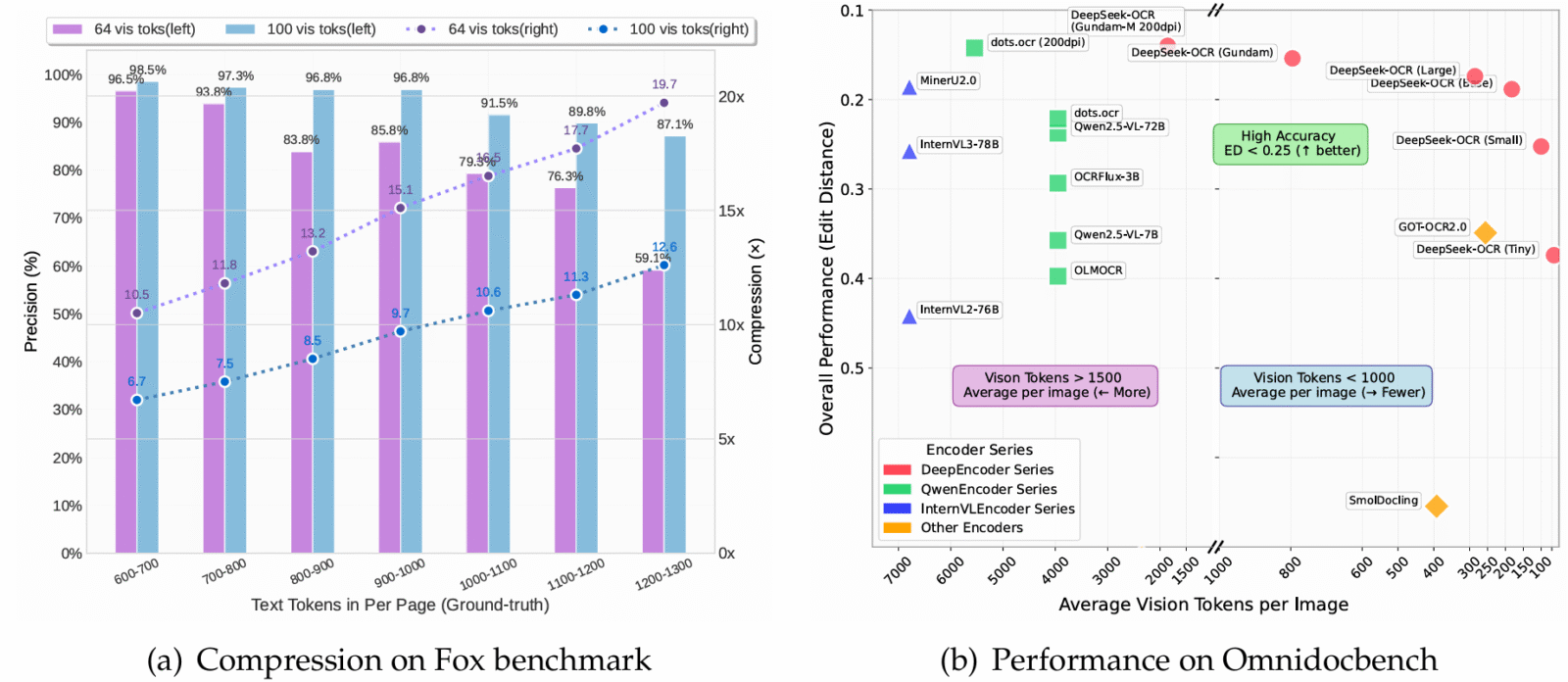
Sur des benchmarks comme OmniDocBench, il dépasse des concurrents bien plus gourmands en tokens. C’est un changement de paradigme, où la vision devient un allié pour rendre les LLMs plus légers, plus rapides… et surtout, plus intelligents.
[1] Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the Middle: How Language Models Use Long Contexts (arXiv preprint arXiv:2307.03172).
[2] Wei, H., Sun, Y., & Li, Y. (2025). DeepSeek-OCR: Contexts Optical Compression (arXiv preprint arXiv:2510.18234).
[3] Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., & Girshick, R. (2023). Segment Anything (arXiv preprint arXiv:2304.02643).
[4] Chen, H.-Y., Lai, Z., Zhang, H., Wang, X., Eichner, M., You, K., Cao, M., Zhang, B., Yang, Y., & Gan, Z. (2024). Contrastive Localized Language-Image Pre-Training (arXiv preprint arXiv:2410.02746).