Data Science
Data Warehouse : Qu’est-ce que c’est ?
Data Warehouse est un terme de plus en plus courant dans le monde de l’informatique et de la gestion des données. Il désigne un système qui permet de centraliser, stocker et organiser de grandes quantités d’informations provenant de diverses sources. Grâce à cet entrepôt de données, les entreprises peuvent analyser leurs activités plus facilement et prendre des décisions plus éclairées. Dans cet article, nous allons expliquer simplement ce qu’est un Data Warehouse, à quoi il sert, comment il fonctionne, et pourquoi il est devenu un outil clé pour la transformation numérique.
Pourquoi un Data Warehouse ?
La définition du Data Warehouse peut parfois sembler floue, surtout pour ceux qui découvrent le concept. Rassurez-vous, j’ai moi-même eu du mal à en saisir toute la portée au début. Lorsque l’on parle d’un système capable de centraliser des informations issues de différentes sources, une question peut naturellement surgir, en particulier si vous avez une expérience en développement :
« Mais pourquoi parler de Data Warehouse, alors que les bases de données comme MySQL, PostgreSQL ou même MongoDB permettent déjà de stocker de grandes quantités de données ? »
C’est une excellente question. Mais elle passe à côté d’un point essentiel, l’origine multiple des données. Et c’est justement ce qui change tout.
Les bases de données classiques sont généralement conçues pour répondre à des besoins spécifiques, dans le cadre d’une seule application ou d’un seul domaine fonctionnel. Prenons un exemple courant dans les entreprises, les systèmes ERP. Chaque service, qu’il s’agisse du CRM, du marketing, des ressources humaines, ou encore de la finance, dispose souvent de sa propre base de données, dédiée à ses activités. Ces bases sont distinctes, mais elles ne sont pas isolées, des relations logiques peuvent exister entre elles.
Par exemple, un client enregistré dans le système CRM peut être le même que celui qui a acheté un produit à 1 000 $ via le service marketing. Ces informations sont liées, mais elles résident dans des systèmes différents. C’est là que le Data Warehouse prend tout son sens, il permet de regrouper ces données éparpillées dans un seul environnement, afin de faciliter leur croisement, leur analyse et leur exploitation stratégique.
Le processus de mise en place d’un Data Warehouse
La création d’un Data Warehouse ne se fait pas au hasard. Elle suit un processus bien défini, élaboré par des spécialistes de la gestion des données. Ce processus repose sur une méthode appelée ETL (pour Extract, Transform, Load) en français : Extraction, Transformation et Chargement.
Ces trois étapes sont essentielles pour construire un entrepôt de données conforme aux standards, afin qu’il soit exploitable efficacement par les data analysts et les outils de Business Intelligence. Grâce à ce pipeline, les données brutes issues de différentes sources sont nettoyées, harmonisées, puis intégrées dans un environnement unifié, prêt à être analysé.
Avant de détailler le fonctionnement du processus ETL, il est utile de connaître quelques exemples de Data Warehouses populaires. Parmi les plus utilisés, on peut citer :
- Google BigQuery
- Amazon Redshift
- Snowflake
Ces plateformes ont été spécialement conçues pour exécuter des opérations analytiques et statistiques sur de grands volumes de données, avec des performances élevées. Contrairement aux bases de données classiques, les Data Warehouses sont optimisés pour la lecture massive, la consolidation de données issues de multiples sources, et la production de rapports stratégiques à forte valeur ajoutée.
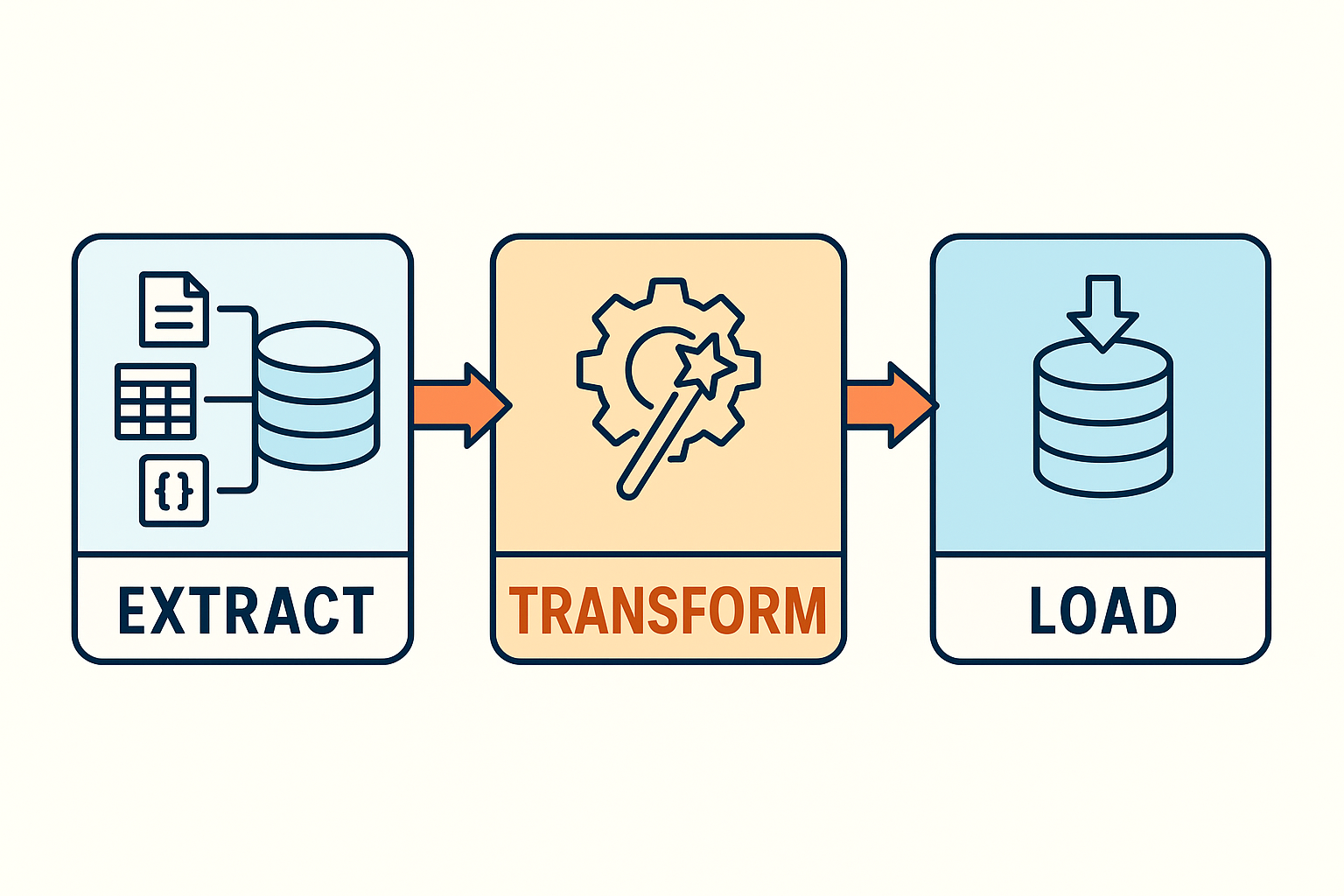
La Méthode ETL (Extract, Transform, Load)
La méthode ETL (Extract, Transform, Load), évoquée précédemment, est au cœur du fonctionnement d’un Data Warehouse. Elle se décompose en trois grandes étapes, que nous allons explorer en détail.
1. Extract – Extraction des données
L’extraction est la première étape, et sans doute l’une des plus critiques du processus. Sans données à extraire… il n’y aurait tout simplement rien à transformer ni à charger ! Elle consiste à récupérer les données brutes à partir de diverses sources. Ces sources peuvent être très variées, bases de données relationnelles (comme MySQL ou PostgreSQL), fichiers Excel, fichiers JSON, ou même… des fichiers Microsoft Access (oui, ils existent encore !). L’objectif ici est simple, rassembler toutes les données utiles, peu importe leur format ou leur provenance.
2. Transform – Uniformiser et structurer
La phase de transformation est souvent la plus technique et la plus réfléchie. Elle consiste à appliquer une série de traitements (généralement sous forme de scripts en Python, SQL ou tout autre langage adapté) pour convertir les données brutes en un format cohérent et exploitable.
Pourquoi cette étape est-elle cruciale ? Parce qu’il faut s’assurer que toutes les données, actuelles et futures, soient transformées de manière identique. C’est une question d’intégrité des données. Eh oui, un Data Warehouse n’est pas figé dans le temps : il évolue, se met à jour régulièrement.
Ces mises à jour se font généralement de deux façons :
- Batch Process : les données sont mises à jour par lots, à des moments précis (ex. chaque nuit ou chaque semaine).
- Stream Process : les données sont mises à jour en temps réel, automatiquement, dès qu’une source change.
3. Load – Chargement dans le Data Warehouse
Enfin, l’étape de chargement (Load) consiste à insérer les données transformées dans le Data Warehouse. C’est la dernière étape du pipeline ETL. Une fois cette opération effectuée, les données sont prêtes à être utilisées par les outils de Business Intelligence, pour produire des rapports, des analyses, ou encore des tableaux de bord interactifs.
Et après ? Qu’est-ce qu’on fait vraiment avec un Data Warehouse ?
Maintenant que toutes nos données sont soigneusement extraites, transformées et chargées dans le Data Warehouse, on pourrait se demander, à quoi ça sert concrètement ? Eh bien, c’est là que la magie commence. Une fois les données centralisées et structurées, elles deviennent exploitables. Et pas juste pour faire joli dans un tableau Excel. Non. On parle ici d’analyses poussées, de rapports dynamiques, de tableaux de bord en temps réel, et surtout… de décisions stratégiques basées sur des données fiables.
Par exemple, un responsable marketing peut analyser le comportement des clients sur les six derniers mois, croiser ça avec les ventes, et ajuster ses campagnes publicitaires. Les RH peuvent suivre les performances et les absences pour améliorer la gestion du personnel. Les dirigeants ? Ils peuvent voir en un coup d’œil si l’entreprise atteint ses objectifs. Bref, c’est un peu comme donner une vue panoramique à chaque service, grâce à une base commune de données unifiées. Et tout ça, c’est possible grâce à des outils de Business Intelligence comme Power BI, Tableau, Looker ou Metabase, qui se connectent directement au Data Warehouse pour en tirer le meilleur.
Mais attention, tout n’est pas parfait ni universel. Car parfois, on a affaire à des données non structurées, ou à des volumes tellement énormes que le Data Warehouse classique commence à montrer ses limites. Et c’est là qu’arrive un autre concept, un peu plus sauvage, un peu plus libre, le Data Lake.
Mais ça, c’est une autre histoire… que nous explorerons dans un prochain article.