Revue de Recherche
Qwen 3.5 : Modèles IA multimodaux open source avec architecture MoE et 201 langues
Découvrez Qwen 3.5, la famille de modèles IA open source d’Alibaba qui rivalise avec GPT-5 et Claude. Architecture MoE, performances impressionnantes et 201 langues.
Début février 2026, Alibaba a secoué le monde de l’intelligence artificielle en dévoilant Qwen 3.5, une famille complète de modèles vision-langage(VLM), qui repousse les limites de ce qu’on pensait possible avec des modèles open source. Alors que la course aux agents IA s’intensifie, cette nouvelle génération de modèles multimodaux pourrait bien changer la donne pour les développeurs et les entreprises du monde entier.
Qwen3.5🚀 pic.twitter.com/qDwkQRtnUu
— Qwen (@Alibaba_Qwen) February 16, 2026
Une architecture qui révolutionne l’efficacité des modèles IA
Le véritable tour de force de Qwen 3.5 réside dans son architecture hybride. Contrairement aux modèles traditionnels qui activent l’ensemble de leurs paramètres, Qwen 3.5 adopte une approche Mixture-of-Experts (MoE) qui ne sollicite qu’une fraction de ses capacités à chaque requête. Prenez le modèle phare Qwen3.5-397B-A17B, avec ses 397 milliards de paramètres, il n’en active que 17 milliards lors de chaque inférence. Cette prouesse technique permet d’obtenir des performances de pointe tout en réduisant drastiquement les coûts de calcul.
L’architecture combine les Gated Delta Networks, une forme d’attention linéaire, avec des blocs d’attention classiques dans un ratio 3:1. Cette hybridation permet au modèle de maintenir une empreinte mémoire constante tout en préservant la précision nécessaire aux raisonnements complexes. Cela permets d’avoir des fenêtres de contexte allant jusqu’à 1 million de tokens, une capacité qui semblait encore récemment réservée aux infrastructures serveur haut de gamme.
Des performances qui font trembler la concurrence
Les benchmarks parlent d’eux-mêmes. Le Qwen3.5-35B-A3B, avec seulement 3 milliards de paramètres actifs, surpasse son prédécesseur Qwen3-235B qui en activait 22 milliards. Plus impressionnant encore, ce modèle moyen se mesure favorablement à GPT-5.2 d’OpenAI et à Claude Opus 4.5 d’Anthropic sur de certaines tâches.

Tous les modèles Qwen 3.5 sont nativement multimodaux, capables de traiter simultanément du texte, des images et des vidéos sans nécessiter de modules séparés. Cette approche unifiée, combinée à un support de 201 langues et dialectes, fait de Qwen 3.5 une solution véritablement globale pour les développeurs internationaux.
Une gamme complète pour répondre à tous les besoins
Alibaba a déployé une stratégie produit particulièrement réfléchie avec 9 modèles open source sortis (sans les variation, et 17 avec), couvrant tous les cas d’usage possibles. Au sommet de la pyramide, le modèle phare de 397 milliards de paramètres s’adresse aux applications les plus exigeantes. Le Qwen3.5-122B-A10B cible les infrastructures serveur avec GPU de 80GB, tandis que le Qwen3.5-35B-A3B trouve le point d’équilibre parfait pour fonctionner sur du matériel grand public avec 32GB de VRAM.
Le Qwen3.5 27B se distingue par son optimisation poussée, supportant une fenêtre de contexte de plus de 800K tokens tout en restant accessible sur du matériel standard. Pour les besoins en production, Qwen3.5-Flash offre une version hébergée avec 1 million de tokens de contexte par défaut et des outils intégrés, le tout à un tarif API extrêmement compétitif comparé aux acteurs occidentaux.
La série de petits modèles complète l’écosystème avec quatre tailles (0.8B, 2B, 4B et 9B), toutes nativement multimodales et capables de gérer 262K tokens de contexte. Ces modèles compacts ouvrent la voie au déploiement d’IA sur des appareils edge et du matériel grand public, démocratisant ainsi l’accès à des capacités IA avancées.
Qwen 3.5, modèles multimodaux pensés pour les workflows agentiques
Contrairement aux modèles conçus principalement pour la conversation, Qwen 3.5 a été pensé dès le départ pour les workflows agentiques, ces systèmes IA autonomes capables de planifier, d’exécuter des tâches multi-étapes et d’interagir avec des interfaces réelles.
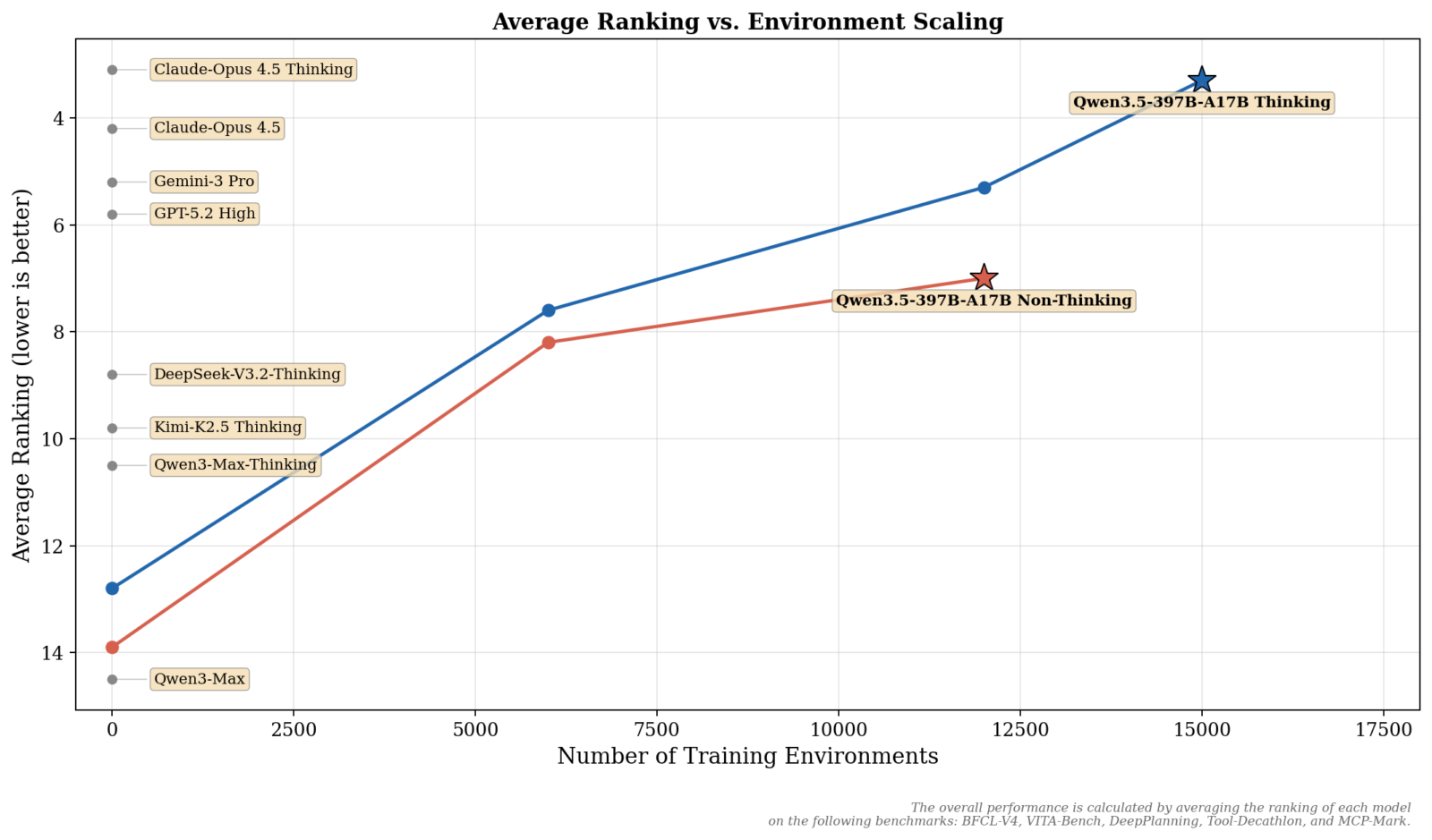
L’entraînement par apprentissage par renforcement a été massivement étendu. Cette approche privilégie la généralisation et la difficulté plutôt que l’optimisation étroite sur des benchmarks spécifiques. Le résultat ? Des modèles qui savent nativement utiliser des outils, effectuer des recherches web, interpréter du code et s’intégrer sans friction avec les frameworks agentiques majeurs, y compris la compatibilité avec OpenClaw, Claude Code et les principales plateformes de développement.
Le mode « thinking » intégré par défaut permet au modèle de générer une chaîne de raisonnement interne avant de fournir sa réponse finale, améliorant ainsi la fiabilité et la traçabilité des décisions. Couplé à une architecture qui maintient les performances sur des contextes ultra-longs, Qwen 3.5 peut analyser des référentiels de code complets ou traiter des documents massifs sans recourir à des stratégies complexes de découpage.
Une nouvelle famille de modèle open source
L’arrivée de Qwen 3.5 marque un tournant significatif dans le paysage de l’IA. En proposant des modèles open source sous licence Apache 2.0 qui rivalisent avec les solutions propriétaires des géants américains, Alibaba démocratise l’accès à des capacités IA de pointe. L’écart entre modèles propriétaires et open source continue de se réduire, et les laboratoires chinois jouent un rôle central dans cette convergence.
Pour les entreprises et développeurs confrontés à des contraintes de coûts, de latence ou de souveraineté des données, Qwen 3.5 représente une alternative crédible et performante. La promesse d’un raisonnement de niveau frontier à une fraction du coût n’est plus théorique. Avec une gamme complète allant du minuscule modèle de 0.8B au mastodonte de 397B, tous partageant la même architecture et tous nativement multimodaux, Qwen 3.5 offre une cohérence rarement vue dans l’industrie.