Revue de Recherche
RAG Anything : La Nouvelle Ère du RAG Multimodal
L’intelligence artificielle générative a franchi un cap décisif ces dernières années, transformant radicalement notre manière d’interagir avec l’information. Cependant, une frustration persiste chez les développeurs et les entreprises, la cécité partielle des modèles de langage face à la richesse visuelle de nos documents. Jusqu’à présent, la majorité des systèmes de Retrieval-Augmented Generation (RAG) excellaient dans le traitement du texte pur mais trébuchaient dès qu’il s’agissait d’interpréter un graphique complexe, une équation mathématique ou une mise en page sophistiquée.
C’est précisément pour combler ce fossé que le framework RAG Anything a été conçu. Cette innovation promet de redéfinir les standards de l’extraction d’information en traitant chaque élément d’un document, qu’il soit textuel ou visuel, comme une entité de connaissance interconnectée.
La fin des silos de données : L’unification multimodale
La principale limitation des architectures RAG traditionnelles réside dans leur approche cloisonnée. Dans un système classique, le texte est souvent séparé des images ou des tableaux, qui sont soit ignorés, soit traités par des processus parallèles sans véritable lien sémantique avec le reste du contenu. RAG Anything brise cette barrière en proposant une approche unifiée qui ne discrimine plus les types de données. Pour ce framework, une image, une légende, un tableau financier ou un paragraphe de texte sont tous des citoyens de première classe au sein du même écosystème de connaissances.
Cette philosophie de conception change la donne pour l’analyse de documents longs et hétérogènes. Imaginez un rapport financier de cent pages rempli de graphiques boursiers et de tableaux de bilans. Là où une IA classique pourrait halluciner ou perdre le fil en ne lisant que le texte environnant, RAG Anything est capable de « voir » et de comprendre le document dans sa globalité. Il contextualise chaque modalité, permettant ainsi à l’intelligence artificielle de raisonner sur des preuves qui s’étendent sur plusieurs formats simultanément. Cette capacité à fusionner la vision et le langage permet de capturer des nuances qui échappaient totalement aux systèmes précédents, offrant ainsi une précision inégalée pour des tâches professionnelles critiques.
L’architecture Dual-Graph
La véritable prouesse technique de RAG Anything repose sur son moteur hybride innovant, souvent décrit comme une construction « Dual-Graph » ou à double graphe. Contrairement aux méthodes simplistes qui se contentent de transformer le contenu en vecteurs mathématiques (embeddings) pour la recherche de similarité, ce framework va beaucoup plus loin en construisant une véritable carte mentale du document. Il comprend structurellement comment une figure est liée à son explication trois pages plus loin.
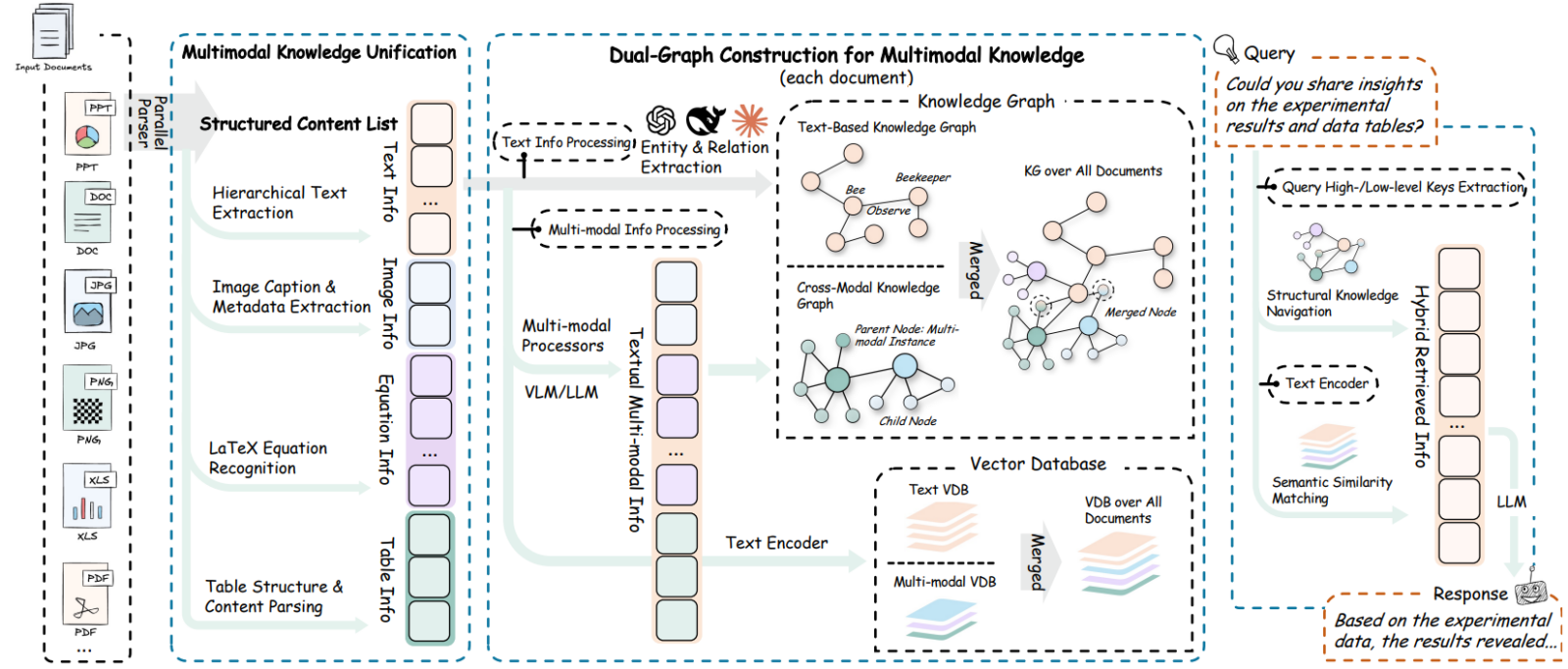
Cette architecture combine intelligemment la navigation structurelle et la correspondance sémantique. D’un côté, le système utilise des graphes de connaissances pour préserver les relations explicites entre les éléments, comme le lien parent-enfant entre un titre de section et son contenu, ou le lien référentiel entre une note de bas de page et un tableau. De l’autre, il continue d’exploiter la puissance des vecteurs denses pour identifier des connexions thématiques subtiles qui ne sont pas explicitement liées par la structure du document. En mariant ces deux approches, RAG Anything permet une récupération d’information « multi-sauts ». L’IA peut ainsi suivre un fil conducteur complexe à travers un document, sautant d’un graphique à un texte explicatif, puis à une conclusion, reproduisant ainsi le cheminement cognitif d’un expert humain qui analyse un dossier technique.

Vers des agents IA plus autonomes et performants
L’impact de cette technologie dépasse la simple amélioration des moteurs de recherche internes. En fournissant une compréhension aussi fine et structurée des données, RAG Anything pave la voie à une nouvelle génération d’agents autonomes beaucoup plus fiables. La capacité à traiter des informations hétérogènes sans perte de contexte est essentielle pour des applications avancées, telles que l’audit automatisé, l’aide à la recherche scientifique ou l’assistance juridique.
De plus, les benchmarks récents montrent que cette approche surpasse nettement les méthodes de pointe actuelles, en particulier sur les documents longs où la charge cognitive est élevée. En réduisant la fragmentation architecturale qui contraignait les systèmes actuels, ce framework offre une solution plus robuste et plus évolutive pour les entreprises. L’intégration de telles capacités dans les pipelines de développement web et logiciel annonce une démocratisation de l’intelligence multimodale, rendant les assistants virtuels non seulement plus bavards, mais véritablement plus clairvoyants.
[1] Guo, Z., Ren, X., Xu, L., Zhang, J., & Huang, C. (2025). RAG-Anything: All-in-One RAG framework. arXiv. https://doi.org/10.48550/arXiv.2510.12323













