Revue de Recherche
Meta SAM 3D : Reconstruction 3D des images du monde physique
L’intelligence artificielle générative vit une accélération fulgurante. Si nous avons passé ces dernières années à nous émerveiller devant la capacité des modèles à générer du texte ou des images 2D ultra-réalistes, une nouvelle frontière est en train d’être franchie, celle de la profondeur et du volume. Meta, déjà pionnier avec son modèle de segmentation universel (Segment Anything Model ou SAM), revient sur le devant de la scène avec une évolution majeure qui promet de transformer notre rapport aux contenus numériques.
Cette nouvelle itération, que nous explorerons ici sous le prisme de SAM 3D, ne se contente plus de détourer des objets dans une image plane. Elle cherche à comprendre, interpréter et reconstruire le monde physique en trois dimensions. Pour les développeurs, les créateurs de contenu en réalité augmentée et les passionnés de tech, c’est une avancée critique. Comment passer d’une simple photo à un asset 3D utilisable ? C’est la promesse de cette technologie.
Dans cet article, nous plongerons au cœur de cette innovation pour comprendre ce qu’est véritablement cette nouvelle mouture, comment elle se distingue de ses prédécesseurs, et nous analyserons en détail ses deux composantes majeures, SAM 3D Objects pour les objets inanimés et SAM 3D body pour la reconstruction humaine.
C’est quoi SAM 3 de Meta ?
Pour bien comprendre l’apport de la 3D, il est essentiel de revenir sur le moteur qui propulse cette technologie. Lorsque l’on évoque SAM 3 (la dernière évolution logique de la lignée Segment Anything), on parle avant tout d’un « cerveau » visuel capable d’une compréhension sémantique inégalée.
La première version de SAM avait choqué l’industrie par sa capacité « zero-shot« , elle pouvait segmenter n’importe quel objet dans une image sans avoir jamais été spécifiquement entraînée pour cet objet précis. SAM 3 pousse cette logique beaucoup plus loin. Il ne s’agit plus seulement de reconnaître des contours basés sur des contrastes de pixels, mais d’intégrer une compréhension contextuelle et temporelle (héritée des travaux sur la vidéo).
Ce modèle agit comme une fondation. Il fournit les masques de segmentation d’une précision chirurgicale qui sont indispensables pour toute tâche de reconstruction 3D. Sans une segmentation parfaite en amont, toute tentative de modéliser un objet en 3D échoue, car le logiciel ne sait pas distinguer l’objet de son arrière-plan. SAM 3 est donc cette brique fondamentale, plus rapide, plus légère et surtout plus « intelligente » dans sa gestion des occlusions et des lumières complexes, préparant le terrain pour l’étape suivante, la spatialisation.
Quelles différences entre SAM 3 et SAM 3D ?
Il est fréquent de confondre le modèle de fondation et son application spatiale. Pour vulgariser, nous pourrions dire que SAM 3 est l’œil, tandis que SAM 3D est le sculpteur.
SAM 3 opère fondamentalement dans un espace bidimensionnel. Il analyse des pixels sur un plan X et Y. Son résultat est un masque binaire : « ceci est un chat, ceci n’est pas un chat ». Il excelle dans l’identification et la séparation des éléments d’une image, mais il ne « sait » pas intrinsèquement à quoi ressemble le dos du chat si celui-ci est vu de face.

SAM 3D, en revanche, utilise les outputs de SAM 3 pour inferer la dimension Z (la profondeur). Il combine la puissance de segmentation de SAM avec des techniques avancées de vision par ordinateur et d’apprentissage profond géométrique. Là où SAM 3 vous donne une silhouette découpée, SAM 3D vous donne un maillage ou un nuage de points orientable. C’est cette transition de l’analyse d’image vers la synthèse de forme qui marque la rupture technologique. Cette distinction est cruciale pour comprendre que SAM 3D n’est pas juste une mise à jour, mais une nouvelle branche d’application dédiée à la reconstruction 3D immersive.
SAM 3D Object, de l’image fixe aux objets virtuels dans une scène 3D
L’une des fonctionnalités les plus attendues de cette suite technologique est le module SAM 3D Object. Imaginez pouvoir prendre une photo d’une chaise vintage dans un magasin et, en quelques secondes, obtenir un modèle 3D texturé prêt à être intégré dans un jeu vidéo ou une application de décoration d’intérieur. C’est exactement le but visé ici.
Le processus repose sur une reconstruction à partir d’un point de vue unique (single-view reconstruction) ou de quelques vues éparses. Le modèle identifie l’objet grâce à la segmentation, puis « hallucine » de manière cohérente les parties invisibles de l’objet en se basant sur une immense base de données de formes 3D qu’il a apprise. Il ne s’agit pas de photogrammétrie classique qui nécessite des dizaines de photos sous tous les angles, c’est une reconstruction prédictive assistée par IA. La texture est ensuite projetée et extrapolée pour couvrir l’intégralité du volume. Cela ouvre des portes immenses pour le commerce électronique et le métavers, réduisant drastiquement le coût de production d’assets 3D.
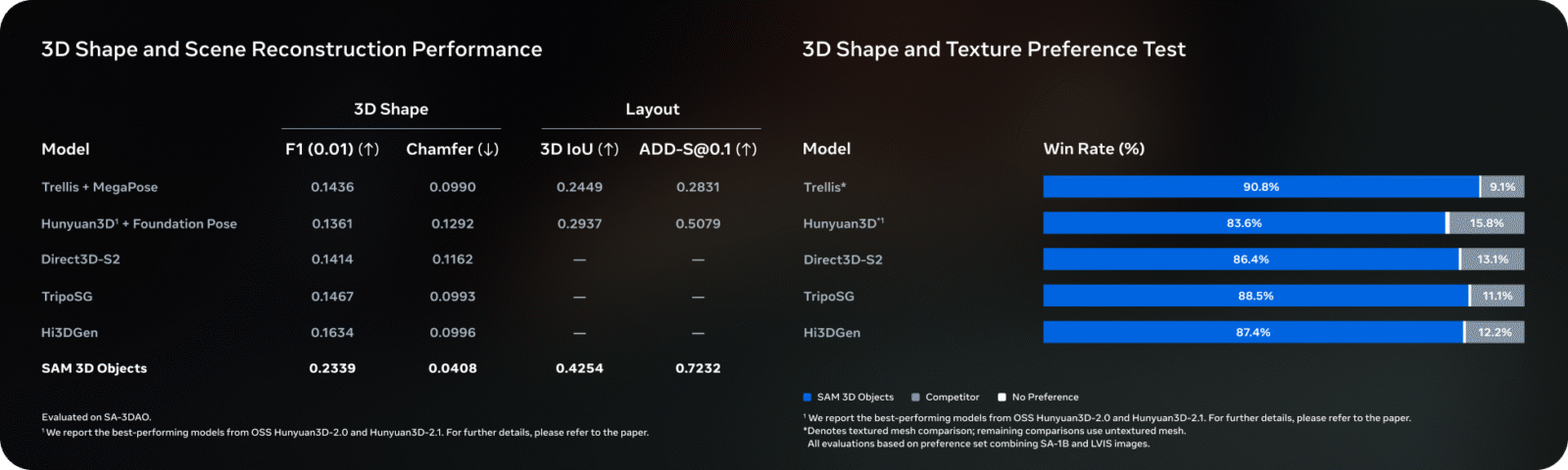
Limites de SAM 3D Object
Toutefois, cette technologie n’est pas encore magique. La génération de SAM 3D Object rencontre des obstacles notables. Le premier concerne la géométrie complexe. Si l’objet possède des trous (comme une anse de tasse complexe) ou des structures fines (comme les rayons d’une roue de vélo), l’IA a tendance à « boucher » ces espaces ou à créer des formes trop lisses, perdant le détail fin.
De plus, la texture des parties cachées reste une prédiction. Si vous photographiez un objet dont l’arrière est radicalement différent de l’avant (par exemple, une boîte de céréales avec des ingrédients au dos), l’IA générera probablement une texture arrière qui ressemble à l’avant ou une texture générique, créant une incohérence avec la réalité. Enfin, les surfaces réfléchissantes ou transparentes (verre, métal poli) restent le cauchemar de la reconstruction 3D, provoquant souvent des artefacts visuels.
SAM 3D Body, reconstruction humaine 3D robuste et précise
L’autre versant fascinant de cette technologie est SAM 3D Body. La reconstruction humaine est un défi bien plus ardu que celle des objets rigides, car le corps humain est articulé, mou, et souvent recouvert de vêtements qui masquent sa véritable forme.
Ici, Meta frappe fort en proposant une solution capable de capturer non seulement la pose (le squelette), mais aussi la forme (le volume corporel) avec une fidélité impressionnante. Contrairement aux approches précédentes qui produisaient souvent des « mannequins » génériques, SAM 3D Body parvient à estimer la morphologie du sujet à partir d’une image ou d’une vidéo. Le système utilise des priors (connaissances préalables) sur l’anatomie humaine pour corriger les erreurs de segmentation.
L’application est immédiate pour l’essayage virtuel de vêtements (virtual try-on), l’analyse sportive biomécanique ou la création d’avatars réalistes pour la réalité virtuelle. La robustesse du modèle est telle qu’il parvient à maintenir une cohérence 3D même lorsque le sujet bouge rapidement ou adopte des poses complexes qui, auparavant, auraient « cassé » le modèle 3D.

Limites de SAM 3D Body
Malgré ces avancées, la reconstruction humaine parfaite n’est pas encore acquise. La limite principale de SAM 3D Body réside dans la gestion des vêtements amples. L’IA a encore du mal à dissocier le volume du tissu du volume du corps en dessous. Une personne portant un manteau d’hiver risque d’être reconstruite comme ayant une corpulence beaucoup plus massive qu’en réalité, le modèle interprétant le vêtement comme de la chair.
Ensuite, il y a la question des interactions mains-visage ou mains-objets. Bien que la reconstruction globale du corps soit bonne, les détails fins comme les doigts entrelacés ou une main tenant un téléphone souffrent souvent de fusion de maillage, créant des « blobs » indistincts aux extrémités. Enfin, l’éclairage dramatique ou les ombres portées fortes peuvent encore tromper l’algorithme sur la profondeur réelle de certains membres, faussant légèrement la perspective du modèle 3D généré.
L’essentiel à retenir des travaux de META
Avec l’arrivée de ces nouvelles capacités de reconstruction, Meta ne se contente plus de segmenter le monde, l’entreprise cherche à le cloner numériquement. Le passage de la 2D à la 3D via SAM 3D représente un saut qualitatif immense, transformant n’importe quelle caméra de smartphone en un scanner 3D potentiel.
Bien que des limites subsistent notamment sur la gestion des textures cachées pour les SAM 3D objects ou les vêtements amples pour le SAM 3D body, les travaux menés par l’équipe de meta restent toujours une grande avancer majeur dans le domaine de la vision par ordinateur et la modélisation 3D.
[1] Carion, N., Gustafson, L., Hu, Y.-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K. V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., … Feichtenhofer, C. (2025). SAM 3: Segment Anything with Concepts. arXiv.
[2] SAM 3D Team, Chen, X., Chu, F.-J., Gleize, P., Liang, K. J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., & Malik, J. (2025). SAM 3D: 3Dfy Anything in Images. arXiv.
[3] Introducing SAM 3D: Powerful 3D Reconstruction for Physical World Images
Testez SAM 3 pour la segmentation – SAM 3D Object – SAM 3D body